python中json.loads()为啥都变成unicode了?加了encoding='utf-8'也没用。我希望得到utf8的k-v,怎么做
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python中json.loads()为啥都变成unicode了?加了encoding='utf-8'也没用。我希望得到utf8的k-v,怎么做相关的知识,希望对你有一定的参考价值。
见最后一行的print,我希望得到utf8的k-v,怎么做?
#coding=utf-8
import json
d =
'name':'测试',
'age':20
print d # 打印'age': 20, 'name': '\xe6\xb5\x8b\xe8\xaf\x95'
j_str = json.dumps(d,ensure_ascii=False)
print j_str #打印"age": 20, "name": "测试"
dd = json.loads(j_str, encoding='utf-8')
print dd #打印u'age': 20, u'name': u'\u6d4b\u8bd5'
json里面的字符串都是unicode(见http://json.org/),所以在dd中不可能出现utf-8的kv。loads函数的参数encoding是指定字符串j_str的编码。将字符串j_str读到dd时,会按这个编码进行解码成unicode。
dd = json.loads(j_str, encoding='utf-8') #dd中的字符串都是unicode 参考技术A- 录入:usage: raise [Exception [, args [, trackback]]]

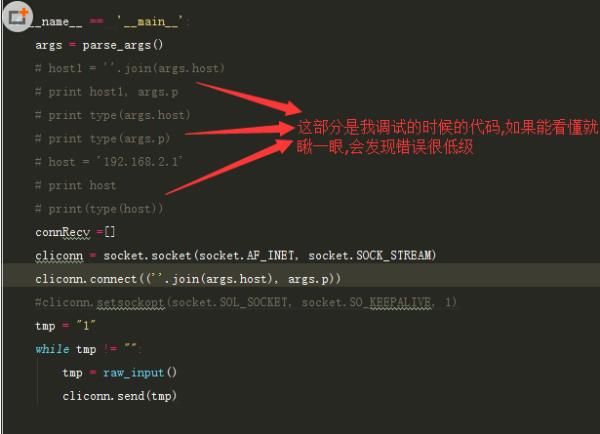
命令行传入的host即ip地址是list形式,想要通过list转为str的格式之后来进行socket.connect
出发的动机是因为自己写的小程序要通过命令行的形式传参并执行命令.
为啥 json.loads 比 ast.literal_eval 更适合解析 JSON?
【中文标题】为啥 json.loads 比 ast.literal_eval 更适合解析 JSON?【英文标题】:Why should json.loads be preferred to ast.literal_eval for parsing JSON?为什么 json.loads 比 ast.literal_eval 更适合解析 JSON? 【发布时间】:2015-04-08 20:05:02 【问题描述】:我有一个字典,它作为字符串存储在 db 字段中。我正在尝试将其解析为 dict,但 json.loads 给了我一个错误。
为什么json.loads 失败而ast.literal_eval 有效?一个比另一个更可取吗?
>>> c.iframe_data
u"u'person': u'Annabelle!', u'csrfmiddlewaretoken': u'wTE9RZGvjCh9RCL00pLloxOYZItQ98JN'"
# json fails
>>> json.loads(c.iframe_data)
Traceback (most recent call last):
ValueError: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
# ast.literal_eval works
>>> ast.literal_eval(c.iframe_data)
u'person': u'Annabelle!', u'csrfmiddlewaretoken': u'wTE9RZGvjCh9RCL00pLloxOYZItQ98JN'
【问题讨论】:
如果能将此问题作为本主题的规范问题,那就太好了(因为它不断被问到,无论是隐含的还是明确的)。但是,由于 OP 提供的 JSON 实际上是非法/格式错误的,因此部分答案是否应该考虑“ 对非法/格式错误的 JSON 有多宽容?” (类似于在抓取 XML/HTML/CSS 上的 BeautifulSoup vs lxml?)。例如,这里的 OP 是否应该使用正则表达式来修复/预处理不需要的和非法的u' 前缀? (这只是在接近 EOL 的 Python 2.x 中会出现的问题)。然后直接使用json.loads,已经?
如果数据库仍然包含从 Python 2.x 以错误方式导出的非法/格式错误的 JSON,那么这个问题就变得不那么规范了。
【参考方案1】:
json.loads 失败,因为您的 c.iframe_data 值不是有效的 JSON 文档。在有效的json 文档中,字符串用双引号引起来,并且没有像u 这样的东西用于将字符串转换为unicode。
使用json.loads(c.iframe_data) 表示反序列化c.iframe_data 中的JSON 文档
ast.literal_eval 在您需要 eval 来评估 input 表达式时使用。如果您有 Python 表达式作为要评估的输入。
一个比另一个更可取吗?
这取决于数据。有关更多上下文,请参阅此answer。
【讨论】:
同样在json 数据中,没有任何类似 u 的东西可以将字符串转换为 unicode。
在 Python 3 中,“字符串”都是 Unicode,二进制数据以字节为单位。 Python 2 中的分离不太清楚,2019 年 12 月 31 日之后将不再提供支持。
感谢您链接到我的答案。【参考方案2】:
因为 u"u'person': u'Annabelle!', u'csrfmiddlewaretoken': u'wTE9RZGvjCh9RCL00pLloxOYZItQ98JN'" 在 chrome 控制台中是 Python unicode 字符串,而不是 Javascript Object Notation:
bad = u'person': u'Annabelle!', u'csrfmiddlewaretoken': u'wTE9RZGvjCh9RCL00pLloxOYZItQ98JN'
SyntaxError: Unexpected string
good = 'person': 'Annabelle!', 'csrfmiddlewaretoken': 'wTE9RZGvjCh9RCL00pLloxOYZItQ98JN'
Object person: "Annabelle!", csrfmiddlewaretoken: "wTE9RZGvjCh9RCL00pLloxOYZItQ98JN"
或者你可以使用yaml来处理:
>>> a = '"person": "Annabelle!", "csrfmiddlewaretoken": "wTE9RZGvjCh9RCL00pLloxOYZItQ98JN"'
>>> json.loads(a)
u'person': u'Annabelle!', u'csrfmiddlewaretoken': u'wTE9RZGvjCh9RCL00pLloxOYZItQ98JN'
>>> import ast
>>> ast.literal_eval(a)
'person': 'Annabelle!', 'csrfmiddlewaretoken': 'wTE9RZGvjCh9RCL00pLloxOYZItQ98JN'
>>> import yaml
>>> a = 'u"person": u"Annabelle!", u"csrfmiddlewaretoken": u"wTE9RZGvjCh9RCL00pLloxOYZItQ98JN"'
>>> yaml.load(a)
'u"person"': 'u"Annabelle!"', 'u"csrfmiddlewaretoken"': 'u"wTE9RZGvjCh9RCL00pLloxOYZItQ98JN"'
>>> a = u'u"person": u"Annabelle!", u"csrfmiddlewaretoken": u"wTE9RZGvjCh9RCL00pLloxOYZItQ98JN"'
>>> yaml.load(a)
'u"person"': 'u"Annabelle!"', 'u"csrfmiddlewaretoken"': 'u"wTE9RZGvjCh9RCL00pLloxOYZItQ98JN"'
【讨论】:
尽管 YAML “大部分工作”,但不应以这种方式滥用它。这是一个 Python 字典文字,请使用literal_eval,该工具旨在具体、安全地解析这些结构。【参考方案3】:
json.loads 专门用于解析JSON,这是一种相当严格的格式。没有u'...' 语法,所有字符串都由双引号而不是单引号分隔。使用json.dumps 序列化可以被json.loads 读取的内容。
所以json.loads(string) 是json.dumps(object) 的倒数,而ast.literal_eval(string) 是(模糊地)repr(object) 的倒数。
JSON 很好,因为它是可移植的——几乎每种语言都有解析器。因此,如果您想将 JSON 发送到 Javascript 前端,您将没有任何问题。
ast.literal_eval 不易移植,但它稍微丰富一些:例如,您可以使用键不限于字符串的元组、集合和字典。
还有json.loads is significantly faster than ast.literal_eval。
【讨论】:
【参考方案4】:我有一个字典,它作为字符串存储在 db 字段中。
这是一个设计错误。虽然完全有可能提取字典的repr,但不能保证完全可以评估对象的repr。
在仅存在字符串键和字符串和数值的情况下,大多数时候 Python eval 函数会从其 repr 中复制该值,但我不确定您为什么认为这会使其成为有效的 JSON,例如。
我试图将它解析成一个字典,但是 json.loads 给了我一个错误。
当然。您没有将 JSON 存储在数据库中,因此期望它解析为 JSON 似乎不太合理。虽然 ast.literal_eval 可用于解析值很有趣,但除了相对简单的 Python 类型之外,没有任何保证。
由于您的数据确实仅限于此类类型,因此您的问题的真正解决方案是更正数据的存储方式,方法是在存储到数据库之前将字典转换为带有json.dumps 的字符串。某些数据库系统(例如、PostgreSQL)具有 JSON 类型以使查询此类数据更简单,如果您可以使用此类类型,我建议您使用它们。
至于哪个“更好”,这将始终取决于特定的应用程序,但 JSON 被明确设计为用于简单结构化数据的紧凑的人类可读机器可解析格式,而您当前的表示基于特定于特定应用程序的格式Python,(例如)在其他语言中很难评估。 JSON 是这里适用的标准,您将受益于它。
【讨论】:
【参考方案5】:首先,也是最重要的,不要将数据序列化两次。您的数据库本身就是数据的序列化,具有一组丰富且富有表现力的工具来查询、探索、操作和呈现它。对随后放入数据库的数据进行序列化消除了隔离子组件更新、子组件查询和索引的可能性,并将所有写入与强制初始读取相结合,以解决一些最重要的问题。
接下来,Java Script Object Notation (JSON) 是 JavaScript 语言的一个有限子集,适用于表示为数据交换服务的静态数据。作为 语言 的子集,这意味着您可以在 JS 中天真地 eval 它来重构原始对象。它是一个简单的序列化(没有内部引用、模板定义、类型扩展等高级功能),具有 JavaScript 语言的局限性以及对使用需要大量“转义”的字符串的惩罚。结束标记的使用也使其难以在纯粹的流媒体场景中使用,例如在点击其配对的 之前,您无法“最终确定”一个对象,因此它也没有用于记录分离的标记。其他限制的显着示例包括在 JSON 中交付 HTML 需要过度转义,所有数字都是浮点数(54 位整数精度,舍入错误,......)使其明显不适合存储或传输财务信息或使用技术(例如加密) 需要 64 位整数,没有本地日期表示,...
JS 和 Python 作为语言之间存在一些显着差异,因此 JSON“JavaScript 对象表示法”与 PLS(Python 文字语法)的行为方式存在显着差异。碰巧的是,出于文字定义的目的,大多数 JavaScript 文字语法都直接与 Python 兼容,尽管解释略有不同。反之则不然,请参见上面的差异示例。如果您关心为 Python 保留数据的保真度,那么与 JS 等价物相比,Python 文字更具表现力且“损耗”更少。但是,正如其他答案/cmets 所指出的,repr() 不是生成这种表示的可靠方法; Python 文字语法并不是意味着 以这种方式使用的。为了最大的类型保真度,我通常推荐 YAML 序列化,其中 JSON 是完全有效的子集。
仅供参考,为了解决存储与实体关联的类字典映射的实际问题,有entity-attribute-value data models。关系数据库 FTW 中的任意键值存储,但权力伴随着责任。请谨慎使用此模式,并且仅在绝对需要时使用。 (如果这是一种常见模式,请查看文档存储。)
【讨论】:
【参考方案6】:json.loads 在解析 JSON 时应优先于 ast.literal_eval,原因如下(总结其他海报)。
在您的具体示例中,您的输入是非法/格式错误的 JSON,使用 Python 2.x 以错误的方式导出(所有不需要和非法的 u' 前缀),反正 Python 2.x 本身就是接近 EOL,请移至 3.x。您可以简单地使用正则表达式来修复/预处理:
>>> import json
>>> import re
>>> malformed_json = u"u'person': u'Annabelle!', u'csrfmiddlewaretoken': u'wTE9RZGvjCh9RCL00pLloxOYZItQ98JN'"
>>> legal_json = re.sub(r'u\'([^\']*)\'', r'"\1"', malformed_json)
'"person": "Annabelle!", "csrfmiddlewaretoken": "wTE9RZGvjCh9RCL00pLloxOYZItQ98JN"'
>>> json.loads(legal_json)
'person': 'Annabelle!', 'csrfmiddlewaretoken': 'wTE9RZGvjCh9RCL00pLloxOYZItQ98JN'
json.loads 的正当理由,而是重新审视您的架构。在至少只需对所有字符串运行一次修复正则表达式,然后将合法的 JSON 存储回来))
json.loads 优点/缺点:
处理所有合法的 JSON,不像 ast.literal_eval
慢。 有更快的 JSON 库,如 ultrajson, yajl, simplejson 等。此外,在大型导入作业中,您可以使用多处理/多线程(这也可以防止内存泄漏,这是常见的所有解析器都有问题)。
数字字段:将所有整数、长整数和浮点数转换为双精度,可能会丢失精度 (@amcgregor)
【讨论】:
以上是关于python中json.loads()为啥都变成unicode了?加了encoding='utf-8'也没用。我希望得到utf8的k-v,怎么做的主要内容,如果未能解决你的问题,请参考以下文章