自动化测试---被玩坏的数据驱动
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动化测试---被玩坏的数据驱动相关的知识,希望对你有一定的参考价值。
最近在整理接口测试相关的资料,所以,看到有关资料就会多看两眼。偶看到别人发的微信公众号。
Python接口测试框第一篇 --- python如何读取txt文件。
Python接口测试框第三篇 --- python如何读取XML文件。
Python接口测试框第四篇 --- python如何读取CSV文件。
曾几何时,也许某大牛说,搞自动化必须要把测试数据放文件里,然后通过程序读取文件。于是,大家纷纷效仿。
什么?你做自动化测试居然不读取测试数据文件,一看就是新手,没逼格。
小王啊!我们这个自动化框架一定得做数据与代码分离,得读取文件啊!
在这个全民微信的年代,各位大牛开了公从号,传授大家自动化测试技术,教点啥呢?那我们就从读取数据文件开始起吧!
什么是数据驱动?
从它的本意来解释,就是数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。说人话,其实就是参数化。
数据驱动有什么用?
对开发来说说,数据驱动无处不在,写好了一个模块,传个参数调用一下,看结果是不是等于预期。
def add(a,b): return a + b if __name__ == \'__main__\': result = add(3, 5) assert result == 8
对测试有来说就可厉害了,你知道早期的自动化测试(工具)都是流水式,第一步打开浏览器,第二步输入“abc”,第三步点击按钮。假如我有一个登录,登录的步骤完全一样,就是每次登录时用的账号密码不一样。用数据驱动啊!
# 伪代码 def login(username, password): driver.find_element_by_id("idInput").send_keys(username) driver.find_element_by_id("pwdInput").send_keys(password) driver.find_element_by_id("loginBtn").click() if __name__ == \'__main__\': login("zhangsan","123") #... login("lisi","456")
看!是不是很厉害了我的数据驱动。我传zhangsan,程序就会用zhangsan登录,我传lisi,就会用lisi登录。
数据驱动的本质就是“测试数据”与“执行代码”做分离。至于,“测试数据”放哪儿都可以,
定义成变量:
username = "zhangsan"
password = "123"
或放到数组里
users =["zhangsan","123"]
或放到字典:
users = {"zhangsan":"123"}
或放到txt文件里,XML文件里,CSV文件里,再读取过出来,调用登录方法时使用,这其实都是可以的。
但是,我们要做的是自动化测试,要分用例的,一种情况一条用例。
--------------------------------------------------------------------
用例1,用户名密码为空。
用例2,用户名为空。
用例3,密码为空。
用例4,用户名密码正确。
----------------------------------------------------------
相信身为软件测试人员的你,对这个用例没有意见吧?
这里以你们喜闻乐见的读取csv文件为例。
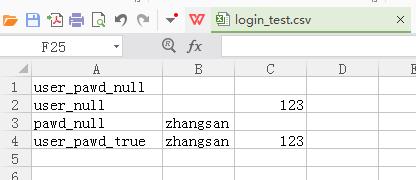
读取数据文件,并得到相应的数据,把这些数据用到具体的某个用例当中。
from selenium import webdriver import unittest import csv # 读取本地 CSV 文件 data = csv.reader(open(\'login_test.csv\', \'r\')) # 读取整个文件的数据放到users数组 users = [] for i in data: user = [] for j in i: user.append(j) users.append(user) class loginTest(unittest.TestCase): def setUp(self): self.driver = webdriver.Chrome() self.driver.get("http://xxx.login.page") # 封装用户登录 def user_login(self, username, password): self.driver.find_element_by_id("idInput").send_keys(username) self.driver.find_element_by_id("pwdInput").send_keys(password) self.driver.find_element_by_id("loginBtn").click() def test_login1(self): \'\'\'用户名、密码为空登录\'\'\' i = 0 for user in users: print(user[0]) if user[0] == \'user_pawd_null\': print(i) username = users[i][1] password = users[i][2]
break; else: i +=1 self.user_login(username, password) def test_login2(self): \'\'\'用户名正确,密码为空\'\'\' username = users[1][1] password = users[1][2] self.user_login(username, password) def test_login3(self): \'\'\'用户名为空,密码正确\'\'\' username = users[2][1] password = users[2][2] self.user_login(username, password) def test_login4(self): \'\'\'用户名密码正确 \'\'\' username = users[3][1] password = users[3][2] self.user_login(username, password) if __name__ == \'__main__\': unittest.main()
来看看你都干了什么高大上的事儿。
1、创建了一CSV文件,然后把登录用的测试数据写到了文件了。 --->创建了一个专门存放数据的文件,这多有逼格,自我感觉良好。
2、读取CSV文件,并且通过for循环,把所有数据组装成一个二维数组,并放users数组中。--->这没什么呀,只是多写了个for循环而已,继续自我感觉良好。
3、test_login1用例,为用户名密码都为空的用例,判断users数组中某一行的第一列是否为“user_pawd_null”,是的话,说明这一行就是我想要的。取这一行的第二、第三列的测试数据,进行登录测试。 --->这个取数据的方式有点。。。有点麻烦!
4、没关系!没关系!麻烦的话,我们看test_login2 ,用users[1][1]和users[1][2]也能取到CSV表第二行的数据。 ---->这不就不那么麻烦了!嗯,是不那么麻烦了,不过,有点傻逼。你确定你清楚的知道users[1][1]和users[1][2] 代表的啥?别急!别急!我打开CSV文件看看第2行对应是什么数据。
这就是你玩的高大上的“数据驱动”,再下实在是佩服佩服!什么你还有更高大上,简洁的玩法?真心请赐教。。。。
为什么不按照下面的方式写用例?
from selenium import webdriver import unittest class loginTest(unittest.TestCase): def setUp(self): self.driver = webdriver.Chrome() self.driver.get("http://xxx.login.page") # 封装用户登录 def user_login(self, username, password): self.driver.find_element_by_id("idInput").send_keys(username) self.driver.find_element_by_id("pwdInput").send_keys(password) self.driver.find_element_by_id("loginBtn").click() def test_login1(self): \'\'\'用户名、密码为空登录\'\'\' self.user_login("", "") def test_login2(self): \'\'\'用户名正确,密码为空\'\'\' self.user_login("", "123") def test_login3(self): \'\'\'用户名为空,密码正确\'\'\' self.user_login("zhangsan", "") def test_login4(self): \'\'\'用户名密码正确 \'\'\' self.user_login("zhangsan", "123") if __name__ == \'__main__\': unittest.main()
我相信,正常人一定看出来了这比上面读CSV文件简单多了。可是,用读取数据文件的话,不懂代码也能写用例!你是在自我YY这种需求吧??不懂自动化测试的同学差点就信了!
“都已经开始写代码做自动化的你告诉我,不想懂开发,你确定这不是任性?”
我在CSV文件中改测试数和在代码中改测试数据有什么区别? 在代码中改测试数据,我是知道对应哪个用例的,在CSV文件中改你确定一下子就知道对应的哪个用例?
那什么情况下才要用到读取测试数据文件呢?
关于自动化测试的误区(二)
已经说明了自己的观点。这里就不再重复,总之,用到要读取文件的情况并不多。不管是UI自动化测试,还是接口自动化测试。
我们还可以借助单元测试框架的功能进行参数化:
unittest单元测试框架实现参数化
坚持我原来的看法,不接受反驳!
@虫师
我理解自动化和手工的区别点只是执行方式上的区别,自动化是由代码来执行用例,手工是由人来执行用例。这里的test_login方法,只是用来执行用例的代码,它并不是真正意义上的用例。本质上说,那个csv文件才是用例,“一种情况一个用例”,而作为用例,这个csv文件中缺少了预期结果。是否可以考虑将预期结果的内容按照一定格式也补充到csv中,然后做一个专门解析csv中结果的方法,加入到test_login中,这样即使是远超过4组数据的情况,也只需要用一个方法就可以进行测试,而不是每组数据写一个方法,失败与否也是针对每组数据而言。
至于用例数量,同样,其实是拿数据组的数量来计算,然后体现在最后生成的测试报告中
@ nuist_kevin
你说的我很赞成,我之前做音乐搜索排序的效果测试时就是使用数据+期望结果组成一条case,并保存在excel中的一行数据,然后用method去一行一行使用数据,并把每条case的实际结果写到对应case的后面,用例跑完之后,再对比即可知道测试报告。
这两段留言,我看了!也明白是什么意思。
我上面的观点是建立在unittest 单元测试框架的基础上面的,在unittest 中一个以“test”开头的方式被计算为一条用例,按照上面的两哥们的观点 excel 文件里面的一条数据计算为一个用例。
我很想弄明白,用例不同,步骤不一样,数据字段不一样(登录需要“用户名”和“密码”, 搜索需要“搜索关键字”, 添加用户需要"id", "name", "age"....),所以,一个方法只能涵盖一组测试,对吧!? 那是不是需要创建多个测试数据文件?,同时也需要多个方法?
这些数据文件中的结果是不是最终还要汇合到一起统计。用例运行失败的错误提示信息是不是也要 写到 excel 文件里? ”方便“查看报错嘛。
总结:
* 维护不便,多个方法 和 多个数据文件,不同的方法还要找对应的数据文件。
* 测试结果统计,测试结果是分散在不同的数据文件中的。
这个需要自己灵活点。数据量越大,数据驱动的优势越明显。还有,数据文件里需要包含:
1、用例名字
2、输入值1、输入值2.。。。
3、期望值
这样脚本里只需要一直一个测试方法就可以了
数据量越大,“数据驱动”越有优势? 你是拿登录或搜索之类的功能测试一万遍么? 那确实挺有优势的,毕竟字段都是一样的。一个方法就可以搞定了。
我们知道UI自动化测试是模拟用户行为,用户肯定不愿意傻逼的重复做某事,能让用户选择的就不要让用户输入,需要用户输入的大数据是不存在的。除了,我现在写博客是在输入大量数据。
你还能再给我举两个例子是让用户输入很多数据的例子么? 谈到数据驱动,你们马上跳出来个想法。如果需要很多数据的话就需要数据驱动了。别YY这个伪需求了!我就问啥功能需要?
再说了,就算数据驱动就一定要读文件么?
以上是关于自动化测试---被玩坏的数据驱动的主要内容,如果未能解决你的问题,请参考以下文章