Spark 资源池简介
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 资源池简介相关的知识,希望对你有一定的参考价值。
在一个application内部,不同线程提交的Job默认按照FIFO顺序来执行,假设线程1先提交了一个job1,线程2后提交了一个job2,那么默认情况下,job2必须等待job1执行完毕后才能执行,如果job1是一个长作业,而job2是一个短作业,那么这对于提交job2的那个线程的用户来说很不友好:我这个job是一个短作业,怎么执行了这么长时间。
使用spark的公平调度算法可以在一定程度上解决这个问题,此时,job2不必等待job1完全运行完毕之后就可以获得集群资源来执行,最终的效果的就是,job2可能会在job1之前运行完毕。这对于一个更强调对资源的公平竞争的多用户场景下是非常有用的,每一个用户都可以获得等量的资源,当然你可以为每一个用户指定一个优先级/权重,优先级/权重越高,获得的资源越多,比如对于一个长作业,你可以为指定更高的权重,而对于短作业,指定一个相对较低的权重。
没有显示配置fairScheduler.xml下的公平调度算法
假设线程1提交了一个action,这个action触发了一个jobId为1的job。同时,在提交这个action之前,设置了spark.scheduler.pool:
SparkContext.setLocalProperty(“spark.scheduler.pool”,”pool_name_1”)
假设线程2提交了一个action,这个action触发了一个jobId为2的job。同时,在提交这个action之前,也设置了spark.scheduler.pool:
SparkContext.setLocalProperty(“spark.scheduler.pool”,”pool_name_1”)
假设线程3提交了一个action,这个action触发了一个JobId=3的job,但是这个线程并没有设置spark.scheduler.pool属性。
最后的spark 资源池逻辑上如下图所示:
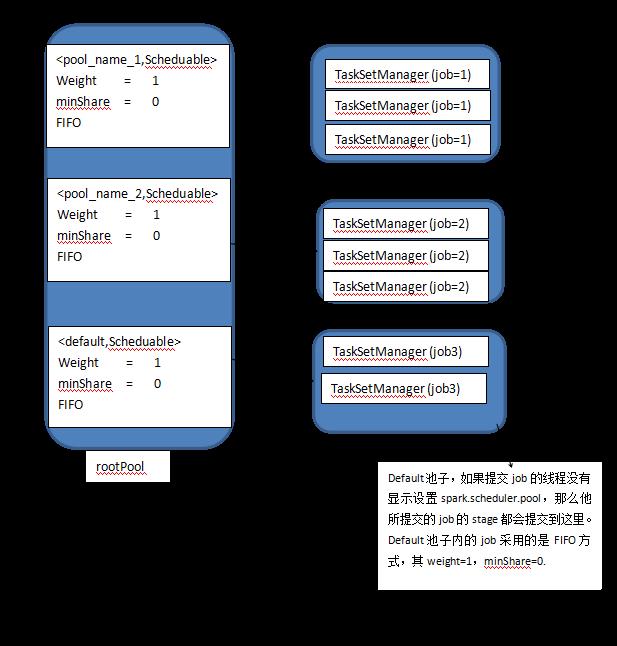
rootPool这个池子里面有三个小池子,其名字分别为:pool_name1,pool_name2,default;pool_name1这个池子存储线程1提交的job,pool_name2存储线程2提交的job,default池子存储那些没有显示设置spark.scheduler.pool的线程提交的job,换句话说我们将不同线程提交的job给隔离到不同的池子里了。
每一个小池子都有以下三个可以配置的属性:weight,minshare,mode,他们的默认值如下:
weight=1
minshare=0
mode=FIFO
一个池子的weight值越大,其获得资源就越多,在上图中,因为这三个池子的weight值相同,所以他们将获得等量的资源。
一个池子的minShare表示这个池子至少获得的core个数。
mode可以是FIFO或者FAIR,如果为FIFO,那么池子里jobid越大的job(等价的,先提交的job),将越先获得集群资源;如果是FAIR,那么将采用一种更加公平的机制来调度job,这个后面再说。
显示配置fairScheduler.xml的公平调度算法
可以发现,上面那种通过在线程里设置spark.scheduler.pool的方式,所创建的池子的属性采用的都是默认值,而且一旦创建好之后你就不能再修改他们。spark提供了另外一种创建池子的方式,你可以配置conf/fairScheduler.xml文件,假设其内容如下(官方提供的内容):
<?xml version="1.0"?> <allocations> <pool name="production"> <schedulingMode>FAIR</schedulingMode> <weight>1</weight> <minShare>2</minShare> </pool> <pool name="test"> <schedulingMode>FIFO</schedulingMode> <weight>2</weight> <minShare>3</minShare> </pool> </allocations>
如果配置了fairScheduler.xml文件,并且其内容如上所示,那么此时的spark 资源池的样子大致如下:
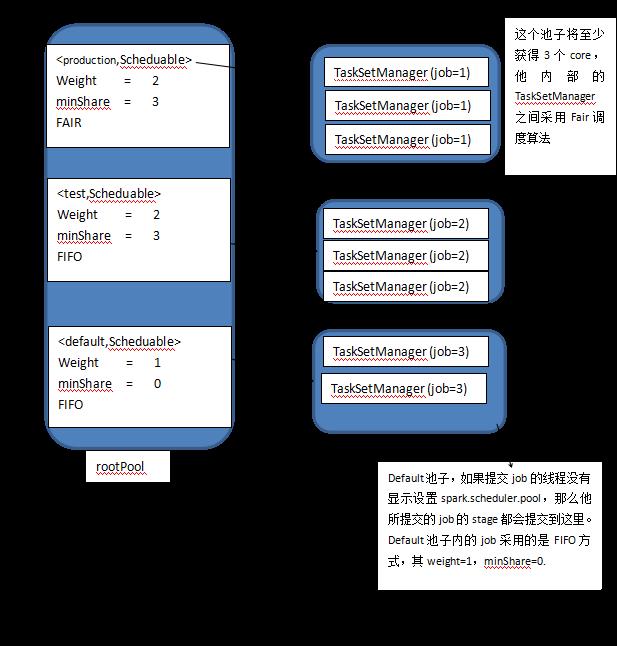
这个资源池里面同样有三个小池子,其名字分别为:production,test,default。其中production资源池的weight为2,他将获得更多的资源(与default池子相比),由于其minShare=3,所以他最低将获得3个core,其mode=FAIR,所以提交到这个池子里的job将按照FAIR算法来调度。
事实上,通过这两个图已经能够在脑海里对spark资源池产生一个大致的印象了,此时再去看spark 资源池的源码就会非常容易。
在初次阅读FIFO算法源码之前:需要重点关注两个属性,priority和stageId,其中的priority就是jobid。先提交的job,其jobid越小,因此priority就越小。finalStage其stageId最大,其parent stage 的stageId较小。
对于公平调度算法,给定两个池子a和b,谁优先获得资源?
1.如果a阻塞了但是b没有阻塞,那么先执行a
2.如果a没有阻塞,b阻塞了,先执行b
3.如果a和b都阻塞了,那么阻塞程度高(等待执行的task比例大) 的那个先执行
4.如果a和b都没有阻塞,那么资源少的那个先执行。
5.如果以上条件都不满足,那么按照a和b的名字来排序。
还是看一下这个算法的实现吧:
private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm { override def comparator(s1: Schedulable, s2: Schedulable): Boolean = { val minShare1 = s1.minShare val minShare2 = s2.minShare val runningTasks1 = s1.runningTasks val runningTasks2 = s2.runningTasks val s1Needy = runningTasks1 < minShare1 val s2Needy = runningTasks2 < minShare2 val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0).toDouble val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0).toDouble val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble var compare: Int = 0 //如果s1阻塞,s2没有阻塞,那么就先执行s1 if (s1Needy && !s2Needy) { return true } else if (!s1Needy && s2Needy) { return false //如果s1没有,s2阻塞了,就先执行s2 } else if (s1Needy && s2Needy) {//如果二者都阻塞了,那就看谁阻塞程度大 compare = minShareRatio1.compareTo(minShareRatio2) } else {//都没阻塞,那么看谁的资源少。 compare = taskToWeightRatio1.compareTo(taskToWeightRatio2) } if (compare < 0) { true } else if (compare > 0) { false } else { s1.name < s2.name//实在不行了,按照池子的name排序吧。 } } }
源码走读
TaskSchedulerImpl在收到DAGScheduler提交的TaskSet时执行如下方法:
override def submitTasks(taskSet: TaskSet) { val tasks = taskSet.tasks logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks") this.synchronized { //创建TaskSetManager val manager = createTaskSetManager(taskSet, maxTaskFailures) val stage = taskSet.stageId val stageTaskSets = taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager]) stageTaskSets(taskSet.stageAttemptId) = manager val conflictingTaskSet = stageTaskSets.exists { case (_, ts) => ts.taskSet != taskSet && !ts.isZombie } if (conflictingTaskSet) { throw new IllegalStateException(s"more than one active taskSet for stage $stage:" + s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}") } //将TaskSetManager添加到资源池,properties里面存储了我们调用SparkContext.setLocalProperty时传递的poolName schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties) if (!isLocal && !hasReceivedTask) { starvationTimer.scheduleAtFixedRate(new TimerTask() { override def run() { if (!hasLaunchedTask) { logWarning("Initial job has not accepted any resources; " + "check your cluster UI to ensure that workers are registered " + "and have sufficient resources") } else { this.cancel() } } }, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS) } hasReceivedTask = true } //调用CoarseGrainedSchedulerBakckend的reviveOffers() backend.reviveOffers() }
这个方法主要做两件事情:第一创建TaskSetManager然后将其添加到资源池,第二调用CoarseGrainedSchedulerBackend进行资源调度。
我们重点讲解资源池的构造和资源池的添加,因此重点关注schedulerBuilder。他是一个trait,主要有两个实现:FIFOSchedulableBuilder和FairSchedulableBuilder。
/** * An interface to build Schedulable tree * buildPools: build the tree nodes(pools) * addTaskSetManager: build the leaf nodes(TaskSetManagers) */ private[spark] trait SchedulableBuilder { def rootPool: Pool //构建资源池,在创建SchedulerBuilder时,会调用buildPools方法来构建池子 def buildPools() //将资源池添加到rootPool中 def addTaskSetManager(manager: Schedulable, properties: Properties) }
这里重点关注他的FairSchedulerBuilder。
addTaskSetManager
override def addTaskSetManager(manager: Schedulable, properties: Properties) { var poolName = DEFAULT_POOL_NAME // var parentPool = rootPool.getSchedulableByName(poolName) //如果用户设置了spark.scheduler.pool if (properties != null) { //默认用户设置的spark.scheduler.pool的值 poolName = properties.getProperty(FAIR_SCHEDULER_PROPERTIES, DEFAULT_POOL_NAME) parentPool = rootPool.getSchedulableByName(poolName) //如果没有这个池子,就创建一个新的池子 if (parentPool == null) { // we will create a new pool that user has configured in app // instead of being defined in xml file //此时的mode,minshare,weight都采用默认值,因此可以发现,在通过设置spark.scheduler.pool这种方式生成的池子 //采用的都是默认值 parentPool = new Pool(poolName, DEFAULT_SCHEDULING_MODE, DEFAULT_MINIMUM_SHARE, DEFAULT_WEIGHT) //最后将新创建的池子添加到rootPool中。 rootPool.addSchedulable(parentPool) logInfo("Created pool %s, schedulingMode: %s, minShare: %d, weight: %d".format( poolName, DEFAULT_SCHEDULING_MODE, DEFAULT_MINIMUM_SHARE, DEFAULT_WEIGHT)) } } parentPool.addSchedulable(manager) logInfo("Added task set " + manager.name + " tasks to pool " + poolName) }
从这里可以看出,通过在线程里使用SparkContext.setLocalProperty来设置spark.scheduler.pool所生成的资源池,其weight,minShare,mode采用的都是默认值,这在某些场景可能不满足用户要求,此时就需要显示的配置fairScheduler.xml文件了。
如果用户创建了fairScheduler.xml,那么会调用buildPools读取这个文件,来创建用户配置的池子:
override def buildPools() { var is: Option[InputStream] = None try { is = Option { schedulerAllocFile.map { f => new FileInputStream(f) }.getOrElse { Utils.getSparkClassLoader.getResourceAsStream(DEFAULT_SCHEDULER_FILE) } } //构建fairScheduler.xml中指定的池子 is.foreach { i => buildFairSchedulerPool(i) } } finally { is.foreach(_.close()) } // finally create "default" pool //构建默认池子,也就是default池子。 buildDefaultPool() }
private def buildFairSchedulerPool(is: InputStream) { val xml = XML.load(is) for (poolNode <- (xml \\\\ POOLS_PROPERTY)) { val poolName = (poolNode \\ POOL_NAME_PROPERTY).text var schedulingMode = DEFAULT_SCHEDULING_MODE var minShare = DEFAULT_MINIMUM_SHARE var weight = DEFAULT_WEIGHT val xmlSchedulingMode = (poolNode \\ SCHEDULING_MODE_PROPERTY).text if (xmlSchedulingMode != "") { try { schedulingMode = SchedulingMode.withName(xmlSchedulingMode) } catch { case e: NoSuchElementException => logWarning("Error xml schedulingMode, using default schedulingMode") } } val xmlMinShare = (poolNode \\ MINIMUM_SHARES_PROPERTY).text if (xmlMinShare != "") { minShare = xmlMinShare.toInt } val xmlWeight = (poolNode \\ WEIGHT_PROPERTY).text if (xmlWeight != "") { weight = xmlWeight.toInt } //创建用户配置的池子 val pool = new Pool(poolName, schedulingMode, minShare, weight) rootPool.addSchedulable(pool) logInfo("Created pool %s, schedulingMode: %s, minShare: %d, weight: %d".format( poolName, schedulingMode, minShare, weight)) } }
总结:
如果开启了fari公平调度算法,并且在提交action的线程里面设置了sparkContext.setLocalPropery("spark.scheduler.pool",poolname),那么这个线程提交的所有job都被提交到poolName指定的资源池里,如果poolName指定的资源池不存在,那么将使用默认值来自动创建他。一种更加灵活的创建池子的方式是用户显示的配置fairScheduler.xml文件,你可以显示的设置池子的weight,minShare,mode值。
由于本人接触spark时间不长,如有错误或者任何意见可以在留言或者发送邮件到[email protected],让我们一起交流。
作者:FrancisWang
邮箱:[email protected]
出处:http://www.cnblogs.com/francisYoung/
本文地址:http://www.cnblogs.com/francisYoung/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
以上是关于Spark 资源池简介的主要内容,如果未能解决你的问题,请参考以下文章
分享一个 hive on spark 模式下使用 HikariCP 数据库连接池造成的资源泄露问题
在这个 spark 代码片段中 ordering.by 是啥意思?
Spark调研笔记第3篇 - Spark集群对应用的调度策略简介
spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)(代码片段