java中map可以存放哪些信息
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java中map可以存放哪些信息相关的知识,希望对你有一定的参考价值。
java map是以键值对的方式保存数据的,map中的键key和值value可以是各种对象,如String、Double、Integer、或者自己定义的类对象,不能是普通基本类型如int、double等 参考技术A 可以放的内容种类很多,包括数字,字符,字符串,对象等。 参考技术B Map中“键、值“对均以对象的方式进行存储,像int、double等基本类型在加入泛型时要用其对应的包装类进行代替。另外如果用TreeMap实现Map接口的话,如果存储的键类型为自定义类型的话,则要实现Comparable接口,并重写compareTo方法,否则无法进行键的排序。
java中Map有哪些实现类和使用场景
Java中的map是一个很重要的集合(集合是用来存放对象的,集合主要分为Collection和Map两个接口),他是一个接口,下面有多个实现类,这些类各有千秋,各自有各自的优点和缺点。
map的主要特点是键值对的形式,一一对应,且一个key只对应1个value,且key唯一。其常用的map实现类主要有HashMap、HashTable、TreeMap、ConcurrentHashMap、LinkedHashMap、weakHashMap等等。
1、HashMap
使用哈希表实现(最近的jdk1.8改用红黑树存储而非哈希表),它是线程不安全的Map,方法上都没有synchronized关键字修饰,具体可以参考https://blog.csdn.net/qq_30683329/article/details/80454518
2、HashTable
hashTable是线程安全的一个map实现类,它实现线程安全的方法是在各个方法上添加了synchronized关键字。但是现在已经不再推荐使用HashTable了,因为现在有了ConcurrentHashMap这个专门用于多线程场景下的map实现类,其大大优化了多线程下的性能。
3、ConcurrentHashMap
这个map实现类是在jdk1.5中加入的,其在jdk1.6/1.7中的主要实现原理是segment段锁,它不再使用和HashTable一样的synchronized一样的关键字对整个方法进行加锁,而是转而利用segment段落锁来对其进行加锁,以保证Map的多线程安全。
其实可以理解为,一个ConcurrentHashMap是由多个HashTable组成,所以它允许获取不用段锁的线程同时持有该资源,segment有多少个,理论上就可以同时有多少个线程来持有它这个资源。
其默认的segment是一个数组,默认长度为16。也就是说理论上可以提高16倍的性能。
但是要注意咯,在JAVA的jdk1.8中则对ConcurrentHashMap又再次进行了大的修改,取消了segment段锁字段,采用了CAS+Synchronized技术来保障线程安全。底层采用数组+链表+红黑树的存储结构,也就是和HashMap一样。这里注意Node其实就是保存一个键值对的最基本的对象。其中Value和next都是使用的volatile关键字进行了修饰,以确保线程安全。这里推荐一下大神的Volatile的深入理解篇,写的非常好http://www.cnblogs.com/xrq730/p/7048693.html。
在插入元素时,会首先进行CAS判定,如果OK就插入其中,并将size+1,但是如果失败了,就会通过自旋锁自旋后再次尝试插入,直到成功。
所谓的CAS也就是compare And Swap(比较和交换),即在更改前先对内存中的变量值和你指定的那个变量值进行比较,如果相同这说明在这期间没有被修改过,则可以进行修改,而如果不一样了,则就要停止修改,否则就会覆盖掉其他的参数。即内存值a,旧值b,和要修改的值c,如果这里a=b,那么就可以进行更新,就可以将内存值a修改成c。否则就要终止该更新操作。
为什么这里会用volatile进行修饰,我在其他博客找到了答案。主要有两个用处:
1、令这个被修饰的变量的更新具有可见性,一旦该变量遭到了修改,其他线程立马就会知道,立马放弃自己在自己工作内存中持有的该变量值,转而重新去主内存中获取到最新的该变量值。
2、产生了内存屏障,这里volatile可以保证CPU在执行代码时保证,所有被volatile中被修饰的之前的一定在之前被执行,也就是所谓的“指令重排序”。
同hashMap一样,在JDK1.8中,如果链表中存储的Entry超过了8个则就会自动转换链表为红黑树,提高查询效率。
4、TreeMap
TreeMap也是一个很常用的map实现类,因为他具有一个很大的特点就是会对Key进行排序,使用了TreeMap存储键值对,再使用iterator进行输出时,会发现其默认采用key由小到大的顺序输出键值对,如果想要按照其他的方式来排序,需要重写也就是override 它的compartor接口。此处引用一下其他大神的代码:
1 import java.util.Comparator;
2 import java.util.Iterator;
3 import java.util.Set;
4 import java.util.TreeMap;
5
6
7 public class Compare {
8 public static void main(String[] args) {
9 TreeMap<String,Integer> map = new TreeMap<String,Integer>(new xbComparator());
10 map.put("key_1", 1);
11 map.put("key_2", 2);
12 map.put("key_3", 3);
13 Set<String> keys = map.keySet();
14 Iterator<String> iter = keys.iterator();
15 while(iter.hasNext())
16 {
17 String key = iter.next();
18 System.out.println(" "+key+":"+map.get(key));
19 }
20 }
21 }
22 class xbComparator implements Comparator
23 {
24 public int compare(Object o1,Object o2)
25 {
26 String i1=(String)o1;
27 String i2=(String)o2;
28 return -i1.compareTo(i2);
29 }
30 }
另外,TreeMap底层的存储结构也是一颗红黑树。是不是发现好多都是红黑树,没错因为红黑树查找效率高,只有O(lgn)。它是一种自平衡的二叉查找树。在每次插入和删除节点时,都可以自动调节树结构,以保证树的高度是lgn。
5、LinkedHashMap
LinkedHashMap它的特点主要在于linked,带有这个字眼的就表示底层用的是链表来进行的存储。相对于其他的无序的map实现类,还有像TreeMap这样的排序类,linkedHashMap最大的特点在于有序,但是它的有序主要体现在先进先出FIFIO上。没错,LinkedHashMap主要依靠双向链表和hash表来实现的。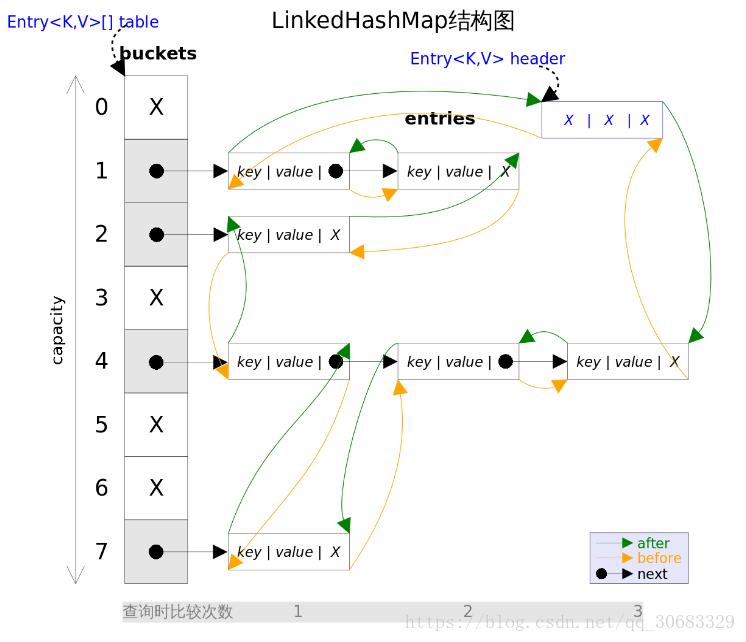
仔细看,这里虽然在计算hashcode时还是发生了hash冲突,采用了链地址法解决了冲突,但是这里的Entry对象是采用双向链表保存的,每个Entry都有一个after和before的属性。当插入一个entry时,如果发生了冲突,就可以将新的Entry插入Entry链表中的头部,但是按照双向链表的角度来说,又会将该Entry插入到双向链表的尾部。
6、weakHashMap
首先,weakHashMap它是一个“弱键”,它的Key值和Value都可以是null,而且其Map中如果这个Key值指向的对象没被使用,此时触发了GC,该对象就会被回收掉的。其原理主要是使用的WeakReference和ReferenceQueue实现的,其key就是weakReference,而ReferenceQueue中保存了被回收的 Key-Value。
如果当其中一个Key-Value不再使用被回收时,就将其加入ReferenceQueue队列中。当下次再次调用该WeakHashMap时,就会去更新该map,比如ReferenceQueue中的key-value,将其中包含的key-value全部删除掉。这就是所谓的“自动删除”。
以上是关于java中map可以存放哪些信息的主要内容,如果未能解决你的问题,请参考以下文章