爬取当当网的图书信息之工作流程介绍
Posted 王起帆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取当当网的图书信息之工作流程介绍相关的知识,希望对你有一定的参考价值。
前往http://book.dangdang.com/我们可以看到当当网上面的图书种类非常丰富

我们是计算机类图书为例子,那么计算机类图书页面的URL http://book.dangdang.com/01.54.htm?ref=book-01-A是我们的种子URL
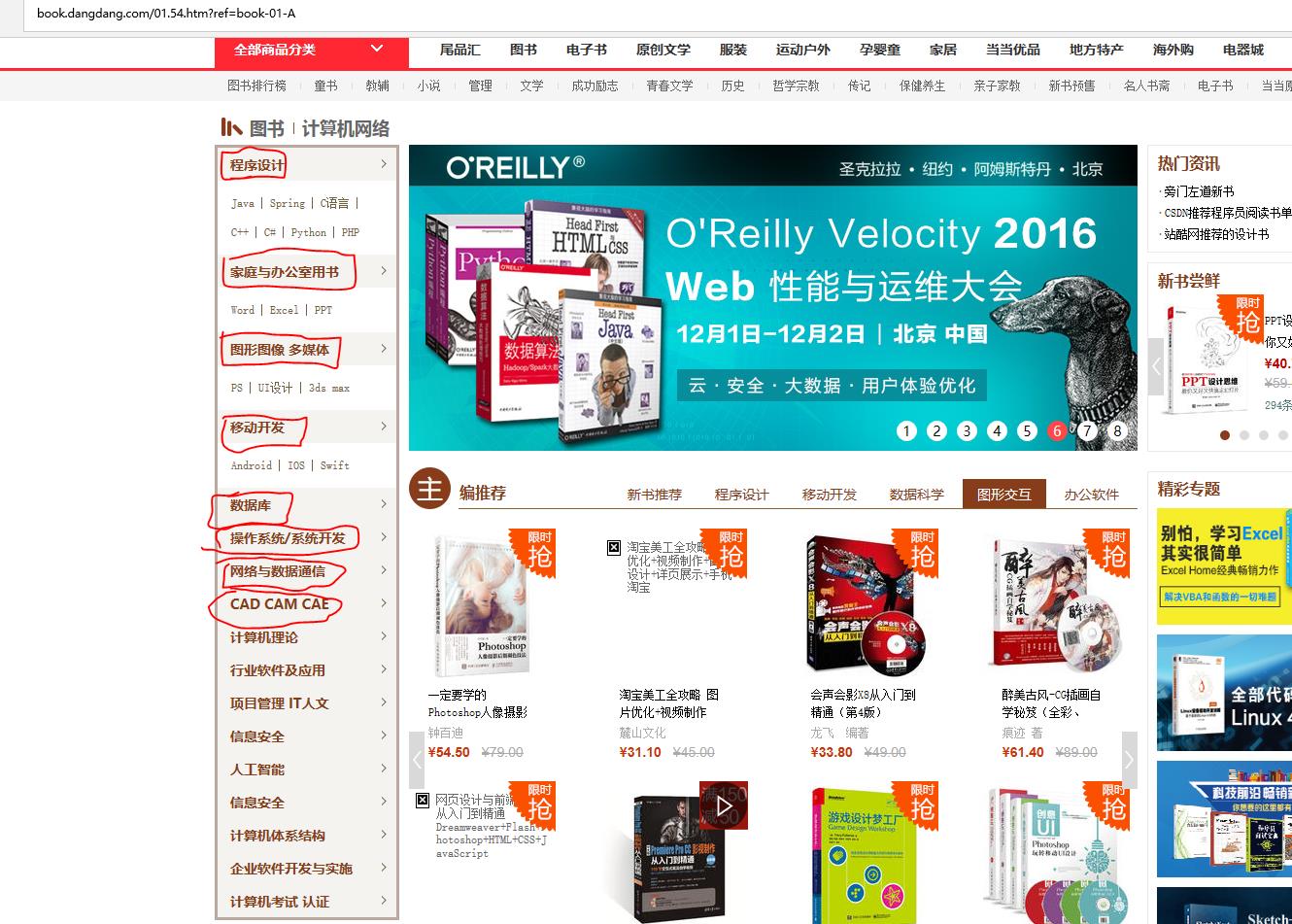
当我们进入这个页面可以看到很多计算机类图书,什么都别说了,都抓取下来,然后在进入子品类页面继续抓取信息,我们以程序涉及品类为例
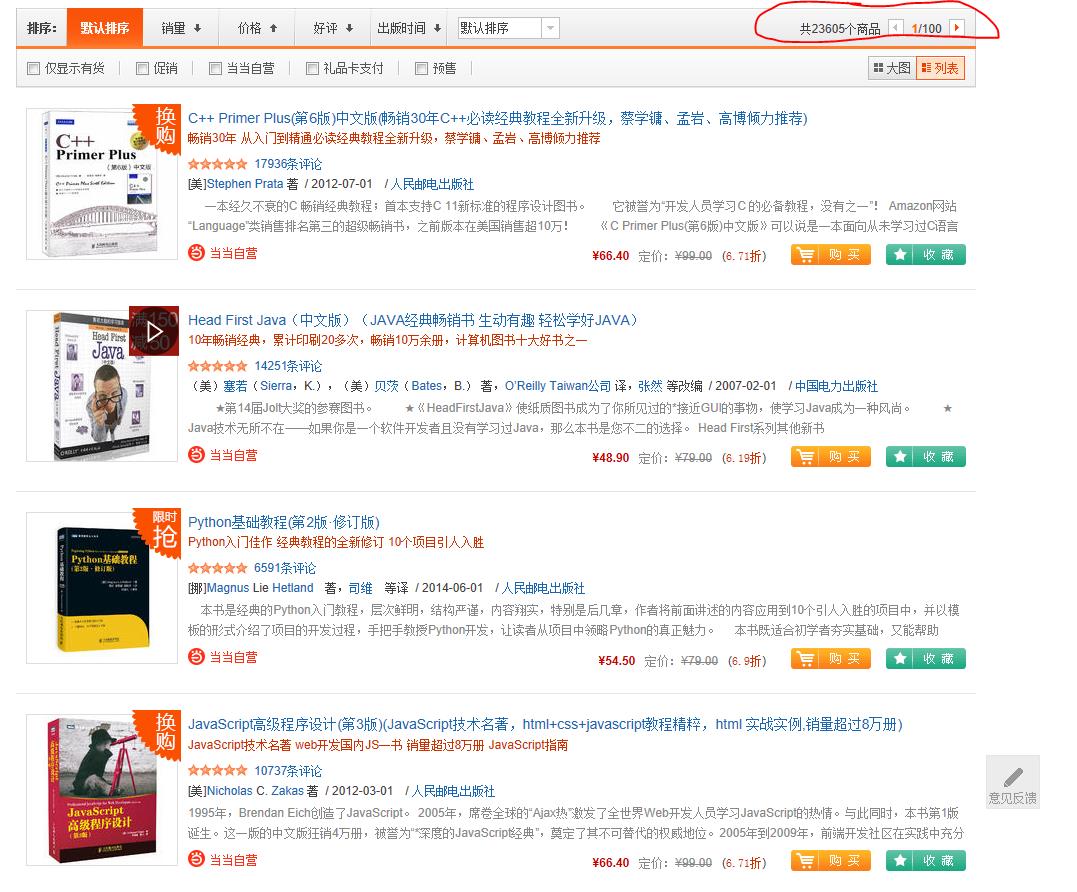
进来之后我们可以看到大量的图书,而且在页面上方我们可以看到100页,可不止这么一点还有99页没有显示出来,我们把这些图书的URL全部抓取下来。我们以《C++ primer plus》为例
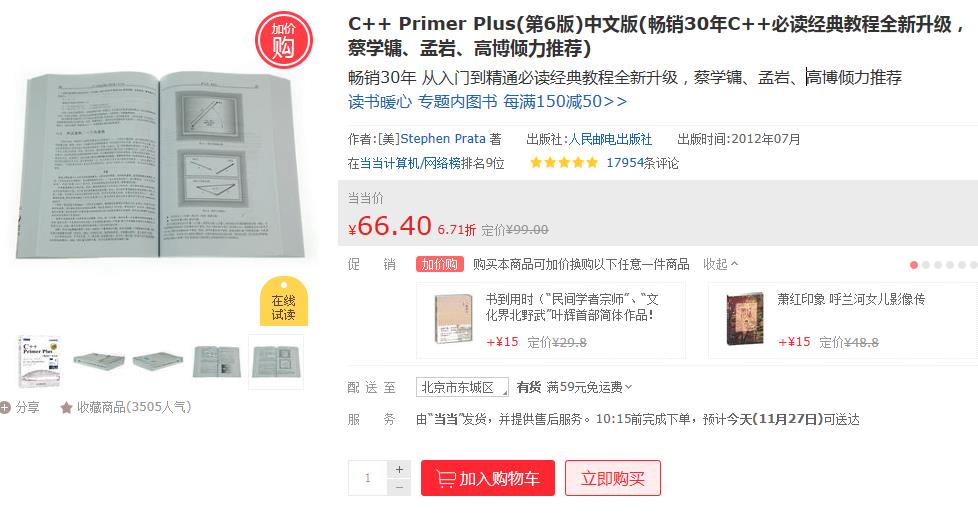

这个页面有大量的图书信息,包含图书的价格,图书的作者,出版社等信息,这都是我们需要的信息,都可以抽取出来。
总结
给程序一个图书大类的URL,程序下载这个页面之后发现大量的图书小种类的URL,爬虫去下载小种类图书的信息后,发现页面有很多图书的URL,进入图书的URL可以抓取图书的相关信息

以上是关于爬取当当网的图书信息之工作流程介绍的主要内容,如果未能解决你的问题,请参考以下文章