Spark2 ML 学习札记
Posted 混沌战神阿瑞斯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark2 ML 学习札记相关的知识,希望对你有一定的参考价值。
摘要:
1.pipeline 模式
1.1相关概念
1.2代码示例
2.特征提取,转换以及特征选择
2.1特征提取
2.2特征转换
2.3特征选择
3.模型选择与参数选择
3.1 交叉验证
3.2 训练集-测试集 切分
4.spark新增SparkSession与DataSet
内容:
1.pipeline 模式
1.1相关概念
DataFrame是来自Spark SQL的ML DataSet 可以存储一系列的数据类型,text,特征向量,Label和预测结果
Transformer:将DataFrame转化为另外一个DataFrame的算法,通过实现transform()方法
Estimator:将DataFrame转化为一个Transformer的算法,通过实现fit()方法
PipeLine:将多个Transformer和Estimator串成一个特定的ML Wolkflow
Parameter:Tansformer和Estimator共用同一个声明参数的API
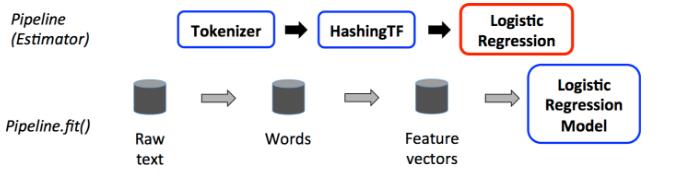
上图中蓝色标识的是Transformer(Tokenizer and HashingTF),红色标识的是Estimator(LogisticRegression)
1.2代码示例
val tokenizer = new Tokenizer() .setInputCol("text") .setOutputCol("words") val hashingTF = new HashingTF() .setNumFeatures(1000) .setInputCol(tokenizer.getOutputCol) .setOutputCol("features") val lr = new LogisticRegression() .setMaxIter(10) .setRegParam(0.01) val pipeline = new Pipeline() .setStages(Array(tokenizer, hashingTF, lr)) // Fit the pipeline to training documents. val model = pipeline.fit(training)
// Make predictions on test documents.
model.transform(test)
.select("id", "text", "probability", "prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}
2.特征提取,转换以及特征选择
2.1特征提取
-
- TF-IDF:提取文档的关键词
- Word2Vec:将文档转换成词向量
- CountVectorizer:向量值计数
2.2特征转换
-
- Tokenizer:分词器
- StopWordsRemover:停词表 注:The list of stopwords is specified by the
stopWordsparameter. Default stop words for some languages are accessible by callingStopWordsRemover.loadDefaultStopWords(language) - n-gram
- Binarizer
- PCA:主成分分析,一种降维方法,可以提取出区分度比较高的特征,并计算权重
- PolynomialExpansion:多项式核转换
- Discrete Cosine Transform (DCT)
- StringIndexer
- IndexToString
- OneHotEncoder:独热编码
- VectorIndexer
-----------------------------------------------------------------标准化和归一化-------------------------------------------------------------------------------------- Normalizer:向量正则化处理,参见http://www.cnblogs.com/arachis/p/Regulazation.html
- StandardScaler:标准化方法1:( x-mean ) / standard deviation
- MinMaxScaler:标准化方法2:
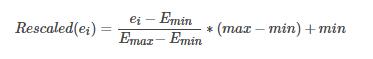
- MaxAbsScaler 标准化方法3: x / abs(max)
- ----------------------------------------------------------------离散化-----------------------------------------------------------------------------------------------
- Bucketizer:分区,可指定分区的上下界
- QuantileDiscretizer:等宽离散化
- ----------------------------------------------------------------交叉特征---------------------------------------------------------------------------------------------
- ElementwiseProduct
- ----------------------------------------------------------------SQL-------------------------------------------------------------------------------------------------
- SQLTransformer
- VectorAssembler
2.3特征选择
- VectorSlicer:截取指定的特征,可以是索引,也可以是特征标识
- RFormula:RFormula用于将数据中的字段通过R语言的Model Formulae转换成特征值,输出结果为一个特征向量和Double类型的label。R文档
- ChiSqSelector:ChiSqSelector用于使用卡方检验来选择特征(降维)。
3.模型选择与参数选择
3.1 交叉验证
将数据分为K分,每次测评选取一份作为测试集,其余为训练集;
3.2 训练集-测试集 切分
根据固定的比例将数据分为测试集和训练集
代码示例:
val cv = new CrossValidator() .setEstimator(pipeline) .setEvaluator(new BinaryClassificationEvaluator) .setEstimatorParamMaps(paramGrid) .setNumFolds(2) // Use 3+ in practice
4.spark新增SparkSession与DataSet
http://blog.csdn.net/yhao2014/article/details/52215966
http://blog.csdn.net/u013063153/article/details/54615378
http://blog.csdn.net/lsshlsw/article/details/52489503
以上是关于Spark2 ML 学习札记的主要内容,如果未能解决你的问题,请参考以下文章