python 爬虫超级课程表话题时出错,请问各位大神如何解决
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 爬虫超级课程表话题时出错,请问各位大神如何解决相关的知识,希望对你有一定的参考价值。
# -*- coding: utf8 -*-
import urllib2
from cookielib import CookieJar
import json
def fetch_data(json_data):
data = json_data['data']
timestampLong = data['timestampLong']
messageBO = data['messageBOs']
topicList = []
for each in messageBO:
topicDict =
if each.get('content', False):
topicDict['content'] = each['content']
topicDict['schoolName'] = each['schoolName']
topicDict['messageId'] = each['messageId']
topicDict['gender'] = each['studentBO']['gender']
topicDict['time'] = each['issueTime']
print each['schoolName'],each['content']
topicList.append(topicDict)
return timestampLong, topicList
def load(timestamp, headers, url):
headers['Content-Length'] = '155'
loadData ='platform=1&phoneVersion=23&phoneBrand=Xiaomi×tamp=0&versionNumber=7.5.0&selectType=0&phoneModel=MI+4LTE&channel=XiaoMiMarket&topicId=13&genderType=-1&'
req = urllib2.Request(url, loadData, headers)
loadResult = opener.open(req).read()
loginStatus = json.loads(loadResult).get('status', False)
if loginStatus == 1:
print 'load successful!'
timestamp, topicList = fetch_data(json.loads(loadResult))
load(timestamp, headers, url)
else:
print 'load fail'
print loadResult
return False
loginUrl='http://120.55.151.61/V2/StudentSkip/loginCheckV4.action'
topicUrl ='http://120.55.151.61/V2/Treehole/Message/getMessageByTopicIdV3.action'
headers=
'Accept-Encoding': 'gzip',
'User-Agent': 'Dalvik/2.1.0 (Linux; U; android 6.0.1; MI 4LTE MIUI/6.6.16)',
'Content-Length': '215',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Connection': 'Keep-Alive',
'Host': '120.55.151.61',
loginData = 'platform=1&password=2564677763D413C3FF12B347528A8226&phoneVersion=23&phoneBrand=Xiaomi&account=2FEB8EB9AE2A2ABF8B8A6726BE1760BF&versionNumber=7.5.0&phoneModel=MI+4LTE&deviceCode=865372021434169&channel=XiaoMiMarket&'
cookieJar = CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar))
req = urllib2.Request(loginUrl, loginData, headers)
loginResult = opener.open(req).read()
loginStatus = json.loads(loginResult).get('data', False)
if loginResult:
print 'login successful!'
else:
print 'login fail'
print loginResult
topicData ='platform=1&phoneVersion=23&phoneBrand=Xiaomi×tamp=0&versionNumber=7.5.0&selectType=0&phoneModel=MI+4LTE&channel=XiaoMiMarket&topicId=13&genderType=-1&'
headers['Content-Length'] = '155'
topicRequest = urllib2.Request(topicUrl, topicData, headers)
topichtml = opener.open(topicRequest).read()
topicJson = json.loads(topicHtml)
topicStatus = topicJson.get('status', False)
print topicJson
if topicStatus == 1:
print 'fetch topic success!'
timestamp, topicList = fetch_data(topicJson)
load(timestamp, headers, topicUrl)
报错信息
你生成的url不正确,这个你可以打印一下,找一个报503的url直接在url里访问,看看是否有问题。
亚马逊判断出你是爬虫,给禁止返回数据了,这个就需要伪装一下你的爬虫,比如修改爬取间隔,随机使用http header,或者使用代理ip。
import urllib
if __name__ == '__main__':
enc = r"%C0%FA%CA%B7%C9%CF%C4%C7%D0%A9%C5%A3%C8%CB%C3%C7.PDF"
string = urllib.unquote(enc).decode('gb2312')
print type(string), string
这是python2的,简单点。只能帮这么多了。 参考技术B if (myreader.HasRows)
MessageBox.Show(myreader.GetString("email") );
myreader.Close();
mycon.Close();
Python爬虫:抓取手机APP的数据
1、抓取APP数据包
方法详细可以参考这篇博文:http://my.oschina.net/jhao104/blog/605963
得到超级课程表登录的地址:http://120.55.151.61/V2/StudentSkip/loginCheckV4.action
表单:
表单中包括了用户名和密码,当然都是加密过了的,还有一个设备信息,直接post过去就是。
另外必须加header,一开始我没有加header得到的是登录错误,所以要带上header信息。
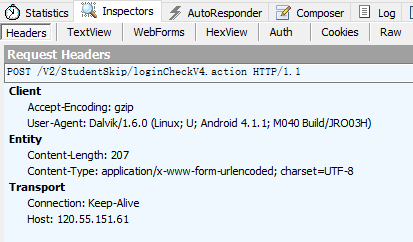
2、登录
登录代码:
#python学习交流群:125240963 import urllib2 from cookielib import CookieJar loginUrl = ‘http://120.55.151.61/V2/StudentSkip/loginCheckV4.action‘ headers = { ‘Content-Type‘: ‘application/x-www-form-urlencoded; charset=UTF-8‘, ‘User-Agent‘: ‘Dalvik/1.6.0 (Linux; U; Android 4.1.1; M040 Build/JRO03H)‘, ‘Host‘: ‘120.55.151.61‘, ‘Connection‘: ‘Keep-Alive‘, ‘Accept-Encoding‘: ‘gzip‘, ‘Content-Length‘: ‘207‘, } loginData = ‘phoneBrand=Meizu&platform=1&deviceCode=868033014919494&account=FCF030E1F2F6341C1C93BE5BBC422A3D&phoneVersion=16&password=A55B48BB75C79200379D82A18C5F47D6&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&‘ cookieJar = CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar)) req = urllib2.Request(loginUrl, loginData, headers) loginResult = opener.open(req).read() print loginResult
登录成功 会返回一串账号信息的json数据

和抓包时返回数据一样,证明登录成功
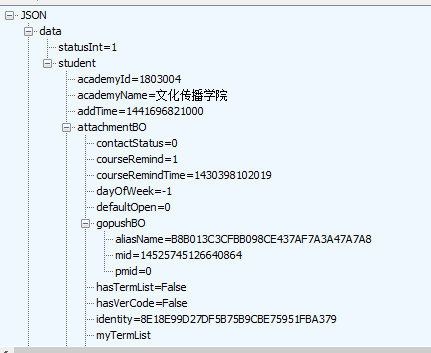
3、抓取数据
用同样方法得到话题的url和post参数
做法就和模拟登录网站一样。详见:http://my.oschina.net/jhao104/blog/547311
下见最终代码,有主页获取和下拉加载更新。可以无限加载话题内容。
#!/usr/local/bin/python2.7 # -*- coding: utf8 -*- """ 超级课程表话题抓取 """ import urllib2 from cookielib import CookieJar import json ‘‘‘ 读Json数据 ‘‘‘ def fetch_data(json_data): data = json_data[‘data‘] timestampLong = data[‘timestampLong‘] messageBO = data[‘messageBOs‘] topicList = [] for each in messageBO: topicDict = {} if each.get(‘content‘, False): topicDict[‘content‘] = each[‘content‘] topicDict[‘schoolName‘] = each[‘schoolName‘] topicDict[‘messageId‘] = each[‘messageId‘] topicDict[‘gender‘] = each[‘studentBO‘][‘gender‘] topicDict[‘time‘] = each[‘issueTime‘] print each[‘schoolName‘],each[‘content‘] topicList.append(topicDict) return timestampLong, topicList ‘‘‘ 加载更多 ‘‘‘ def load(timestamp, headers, url): headers[‘Content-Length‘] = ‘159‘ loadData = ‘timestamp=%s&phoneBrand=Meizu&platform=1&genderType=-1&topicId=19&phoneVersion=16&selectType=3&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&‘ % timestamp req = urllib2.Request(url, loadData, headers) loadResult = opener.open(req).read() loginStatus = json.loads(loadResult).get(‘status‘, False) if loginStatus == 1: print ‘load successful!‘ timestamp, topicList = fetch_data(json.loads(loadResult)) load(timestamp, headers, url) else: print ‘load fail‘ print loadResult return False loginUrl = ‘http://120.55.151.61/V2/StudentSkip/loginCheckV4.action‘ topicUrl = ‘http://120.55.151.61/V2/Treehole/Message/getMessageByTopicIdV3.action‘ headers = { ‘Content-Type‘: ‘application/x-www-form-urlencoded; charset=UTF-8‘, ‘User-Agent‘: ‘Dalvik/1.6.0 (Linux; U; Android 4.1.1; M040 Build/JRO03H)‘, ‘Host‘: ‘120.55.151.61‘, ‘Connection‘: ‘Keep-Alive‘, ‘Accept-Encoding‘: ‘gzip‘, ‘Content-Length‘: ‘207‘, } ‘‘‘ ---登录部分--- ‘‘‘ loginData = ‘phoneBrand=Meizu&platform=1&deviceCode=868033014919494&account=FCF030E1F2F6341C1C93BE5BBC422A3D&phoneVersion=16&password=A55B48BB75C79200379D82A18C5F47D6&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&‘ cookieJar = CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar)) req = urllib2.Request(loginUrl, loginData, headers) loginResult = opener.open(req).read() loginStatus = json.loads(loginResult).get(‘data‘, False) if loginResult: print ‘login successful!‘ else: print ‘login fail‘ print loginResult ‘‘‘ ---获取话题--- ‘‘‘ topicData = ‘timestamp=0&phoneBrand=Meizu&platform=1&genderType=-1&topicId=19&phoneVersion=16&selectType=3&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&‘ headers[‘Content-Length‘] = ‘147‘ topicRequest = urllib2.Request(topicUrl, topicData, headers) topicHtml = opener.open(topicRequest).read() topicJson = json.loads(topicHtml) topicStatus = topicJson.get(‘status‘, False) print topicJson if topicStatus == 1: print ‘fetch topic success!‘ timestamp, topicList = fetch_data(topicJson) load(timestamp, headers, topicUrl)
结果:
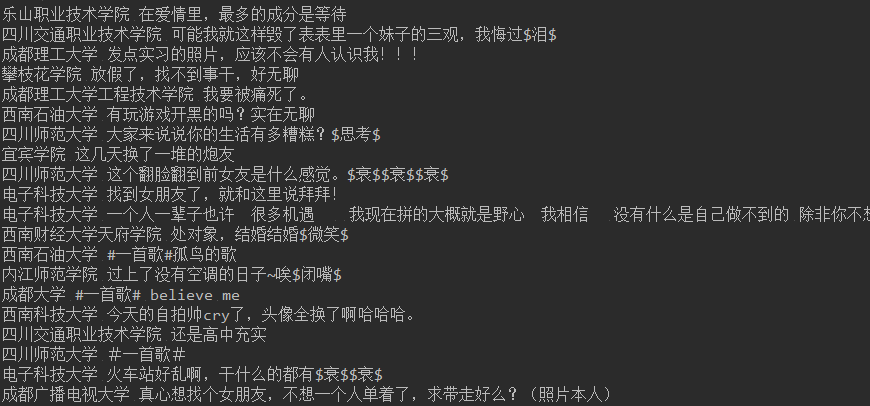
python学习交流群:125240963
以上是关于python 爬虫超级课程表话题时出错,请问各位大神如何解决的主要内容,如果未能解决你的问题,请参考以下文章