OpenStack 企业私有云的几个需求:自动扩展(Auto-scaling) 支持
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenStack 企业私有云的几个需求:自动扩展(Auto-scaling) 支持相关的知识,希望对你有一定的参考价值。
本系列会介绍OpenStack 企业私有云的几个需求:
- GPU 支持
- 自动扩展(Auto-scaling)支持
- 混合云(Hybrid cloud)支持
- 物理机(Bare metal)支持
- CDN 支持
- 企业负载均衡器(F5)支持
- 大规模扩展性(100个计算节点)支持
- 商业SDN控制器支持
弹性是一个真正的云平台必须具备的五大特征(自助使用、网络、独立资源池、快速弹性、服务可计量)之一,它是指一种对资源快速和弹性地提供(扩展),以及同样对资源快速和弹性地释放(收缩)的能力。因此,可以认为,弹性是云平台的一种属性和能力,而自动扩展(Auto-Scaling)资源即是实现该能力的方法。借助 Auto-Scaling,客户可以在峰值期间无缝地扩展资源来处理增加的工作负载,并在峰值过后自动减少资源来保持合理的容量和最大程度地降低成本。
1. 扩展(Scale)的概念
1.1 垂直扩展和水平扩展
当一个应用所收到的负载超出了它当前的处理能力时,支撑它的资源必须得到增加。从方向上将,有两种增加的方式:
- Scale up / Vertically Scale :垂直扩展。它也有两种可能:
- 当物理机/虚机目前还有富裕的资源时,向应用分配更多的资源,比如 CPU、内存、网络带宽、磁盘等等。这种分配可以是手工或者自动的。
- 当物理机/虚机已经没有空余的资源时,先向物理机/虚机增加更多的资源,再分配给应用。
- Scale Out /Horizonally Scale:水平扩展。这种扩展方式不是向应用的物理机/虚机增加资源,而是增加其数目,从而增加其服务能力。
下面左图的垂直扩展实例中,应用所在的虚机的 CPU 从 2 个增加到了 4 个;下面右图的水平扩展实例中,通过两次按需水平扩展,虚拟服务器(虚机)数目从1个增加到了3个。
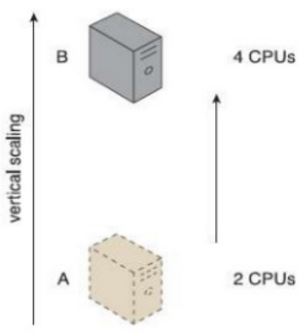
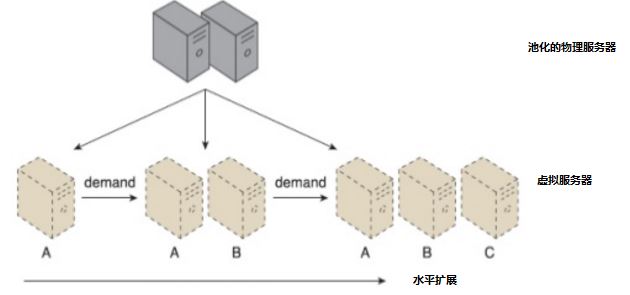
(垂直扩展) (水平扩展)
两者之间的简单对比:
| 对比项 | 水平扩展 | 垂直扩展 |
| 成本 | 较低,因为往往可以增加普通商用服务器即可 | 较高,因为单个普通服务器性能总是有限的,因此往往需要专用的服务器 |
| 实时性 | 往往能达到实时性要求 | 部分情况下可以实时,部分情况下需要一些停机时间 |
| 自动化能力 | 往往能较容易地自动扩展 | 往往需要额外的步骤,不太容易实现自动扩展。 |
| 硬件服务器限制 | 不受单个服务器最高容量的限制 | 往往受到单个服务器最高容量的限制 |
| 应用限制 | 对应用有要求,往往要求应用是无状态的、可横向扩展的 | 对应用没有要求,传统应用和云原生应用都可以 |
1.3 自动扩展
根据上文中的对比,水平扩展比较容易实现自动化,因此,在现在的云提供商所提供的云中,往往都是提供很丰富的自动扩展能力,以及小部分垂直扩展能力,比如增加虚机的内存等。下文的介绍都只涉及到水平扩展。
1.3.1 常见实现方式
自动扩展在理论上有多种实现方式,比如 基于阈值的规则(threshold-based rules)、 增强型学习(reinforcement learning or Q-learning (RL))、 队列理论(queuing theory)、控制理论和时间序列分析(control theory and time series analysis)等等。
其中,基于阈值的规则 在目前的云中实现得较为普遍,比如亚马逊的Cloud Watch。在这种实现方式中,要将水平扩展自动化,往往需要一个管理软件,它包括以下几个基本模块:
- 扩展触发模块:往往包括定时触发模块,以及根据系统状态触发,比如通过对 CPU、内存、网络带宽等做持续监测然后根据定义的不同策略来触发扩展。
- IT资源编排模块:在被调用的时候,可以增加或者减少服务器
- 负载均衡模块:将运行在多个服务器中的服务虚拟化为一个虚拟服务
不同的云服务供应商都有自己实现这种管理软件的方式,下文将会仔细分析当前比较流行的实现,比如阿里云、亚马逊和OpenStack 中的实现方式。
1.3.2 自动扩展的目标
理论上,自动扩展的目标包括所有类型的资源,包括计算、存储、网络资源等。目前,应用较多的、实现得较为完善的为计算资源即虚机的自动扩展。
1.3.3 自动扩展的模式
弹性伸缩模式主要分为以下几类:
- 定时模式:配置周期性任务(如每天 13:00),定时地增加或减少实例。
- 动态模式:基于云监控性能指标(如 CPU 利用率),自动增加或减少实例。
- 固定数量模式:通过“最小实例数”属性,可以让用户始终保持健康运行的实例数量,以保证日常场景实时可用。
- 自定义模式:根据用户自有的监控系统,通过 API 手工伸缩实例。
- 健康模式:如实例为非运行状态,将自动移出或释放该不健康的实例。
2. 公有云上的自动扩展功能
2.1 亚马逊(AWS)弹性伸缩服务
亚马逊弹性计算云(EC2,Elastic Compute Cloud)在 2009 年就发布了实现弹性的特性,包括:
- 用于监测的 CloudWatch:一项针对 AWS 云资源和在 AWS 上运行的应用程序进行监控的服务,使用户可以了解到资源使用、操作性能和总体需求状况,包括CPU使用、磁盘读写和网络流量等指标。
- 自动伸缩的 Auto Scaling:允许EC2的容量根据需求增大或减小,保证EC2在流量高峰时增容以维持其性能,在流量较低时减容以节省成本,此特性对于使用率波动频繁的程序来说尤其适用。它由 Amazon CloudWatch 启用,无需额外费用。
- 弹性负荷调节 Elastic Load Balancing(ELB):在各EC2计算实例之间分配流量,允许程序出错,它还能够在资源池中探测出运行不正常的实例,并引导信息流通过正常实例前进,直到不正常实例被修复。
2.1.1 基本概念和流程
AWS 的 Auto Scaling 的基本概念和流程如下图所示:
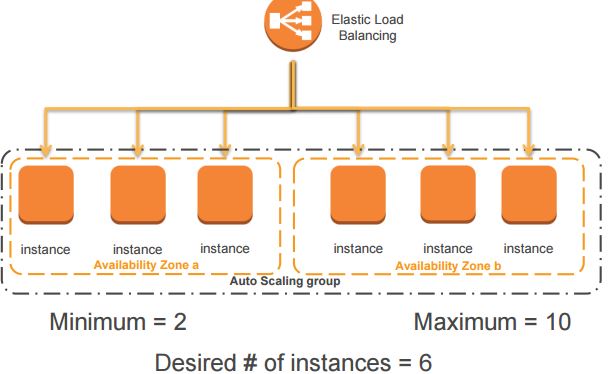

其中,Auto Scaling groups,即伸缩组,包含若干虚机,可以跨可用域。用于可以设置其(1)最小虚机数目(2)最大虚机数目(3)期望虚机数目(4)
2.1.2 Scaling Policy (扩展策略)
(1)简单扩展策略(Simple Scaling Policy)及问题:评估(evaluation period)- 告警发出 (alarm)- 扩展(scale out/down)- 冷却(cool down)
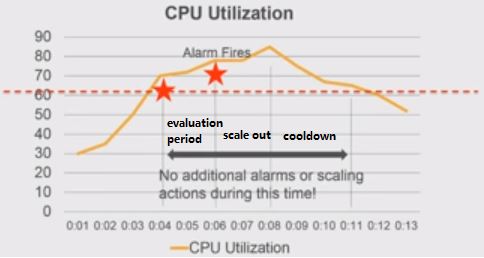
这种策略的问题是,一个完整的周期内,系统是不会发出新的告警的,直到当前周期处理结束。那么,可能的问题是,当前处理周期还没结束,系统就因为扛不住超大的负载而宕机了:
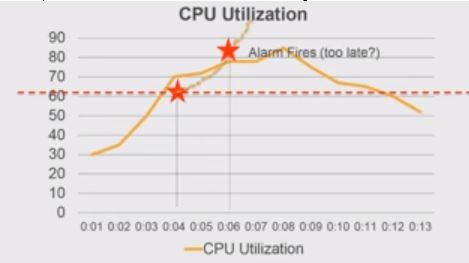
(2)亚马逊的分步扩展策略(Step Scaling Policy)
2015 年,亚马逊为了解决上述问题,上线了分步扩展策略(Auto Scaling Update – New Scaling Policies for More Responsive Scaling)。其特征如下:
- 一个策略中定义多个步骤
- 没有锁定,而是持续评估和告警
- 根据告警,从多个步骤中选择最合适的步骤来执行
- 不支持 cooldown
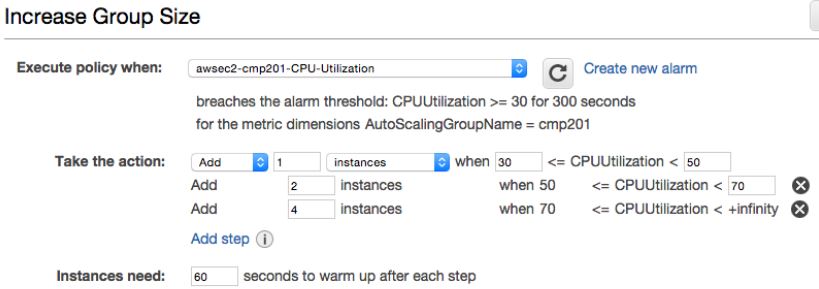
结果和比较:
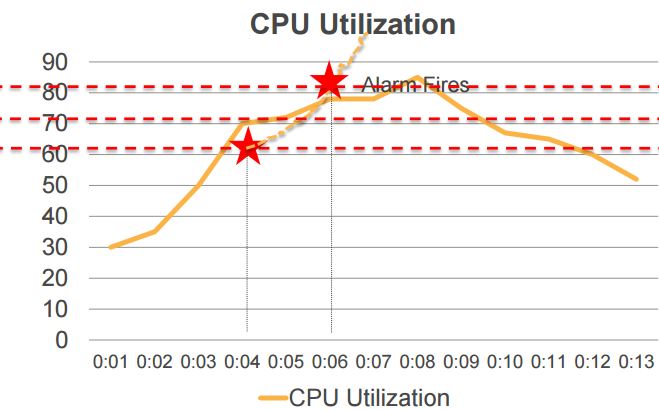

AWS 的推荐策略:When in doubt, prefer step scaling policies (当你有疑惑时,请使用 step scaling policy)。
2.1.3 Netfix 使用 AWS Auto-scaling 服务的经验教训(lesson learnt)
- Scale up early:早 Scale up,建议将 CloudWatch 告警的阈值设置为 75%,并且需要考虑虚机创建所需要的时间和应用启动所需要的时间。
- Scaling down slowly:晚 Scale down,这样可以减少虚机数量减少带来的风险。比如, 在虚机 CPU 使用率高于60% 持续五分钟后,scale up 10%;在 CPU 使用率低于 30% 并持续 20分钟后,scale down 10%。
- When NOT to use Percent Based Auto scaling:对于小规模的自动伸缩组,不要使用基于百分比的自动伸缩策略。
- 伸和缩策略使用相同的调整量:比如伸缩比例都设置为 10%,这么做可以避免”容量颠簸 capacity thrashing“。
2.2 阿里云弹性伸缩服务(Elastic Scaling Service - ESS)
![]() (阿里云官网链接)
(阿里云官网链接)
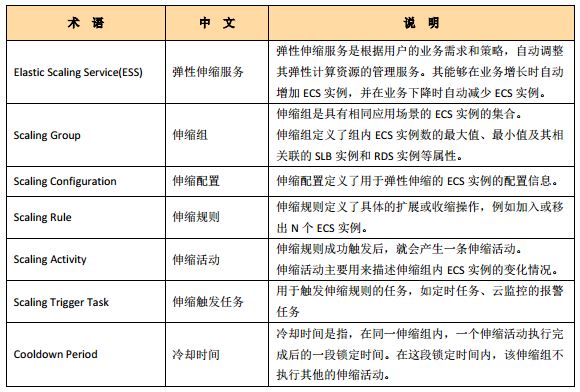
阿里云的弹性伸缩服务(Elastic Scaling Service)是根据用户的业务需求和策略,自动调整其弹性计算资源的管理服务。用户根据自己的业务需求自动调整其弹性计算资源,在满足业务需求高峰增长时无缝地增加 ECS 实例,并在业务需求下降时自动减少 ECS 实例以节约成本。目前,阿里云的该产品是免费提供给客户使用的,但是目前一个用户最多只能创建20个伸缩组。
2.2.1 基本功能
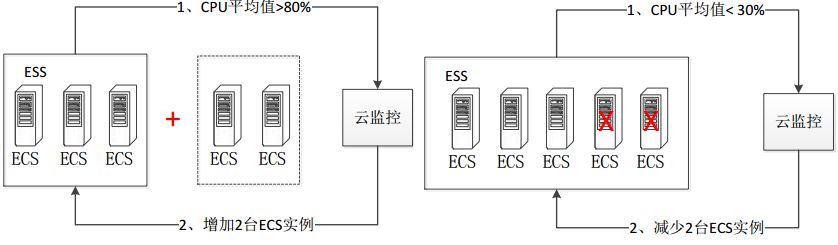
基本功能除了动态增加或者减少ECS实例外,还包括其它附加功能,比如在增加或减少 ECS 实例时,自动向 SLB(弹性负载均衡器) 实例中添加或移除相应的 ECS 实例;以及 自动向 RDS(关系数据库) 访问白名单中添加或移出该 ECS 实例的 IP。可见,阿里云所实现的方式正是亚马逊在2015年之前实现的方式。
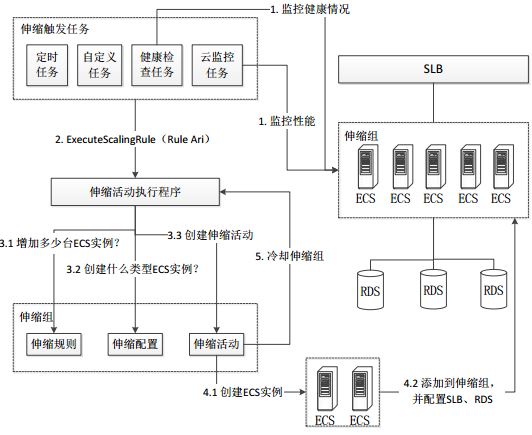
2.2.2 基本概念和流程
2.2.3 应用示例
ESS 作为云平台基础服务之一,几乎在阿里云的各种解决方案中都能看到它的身影。比如多媒体解决方案中,流媒体转码集群和服务集群都是具有自动伸缩能力的集群。
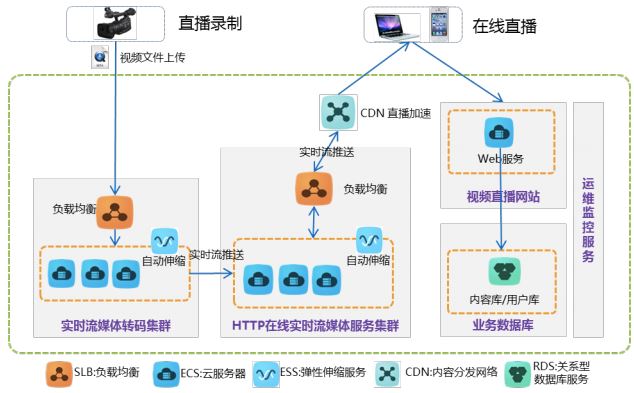 (资源来源)
(资源来源)
目前本人还没有机会试用阿里云的ESS服务。从官网的介绍来看,该服务是2015年8月27日正式开放上线,因此其功能还比较简单,只是提供了最基本的能力,比如从可以查找到的渠道来看,其监控指标只是包括传统的如CPU、内存利用率等指标;而且一个用户只能使用有限的ESS组。
3. OpenStack 中的 Auto-scaling
3.1 当前版本中的实现:Heat + Ceilometer + Neutron LBaaS V1
3.1.1 原理
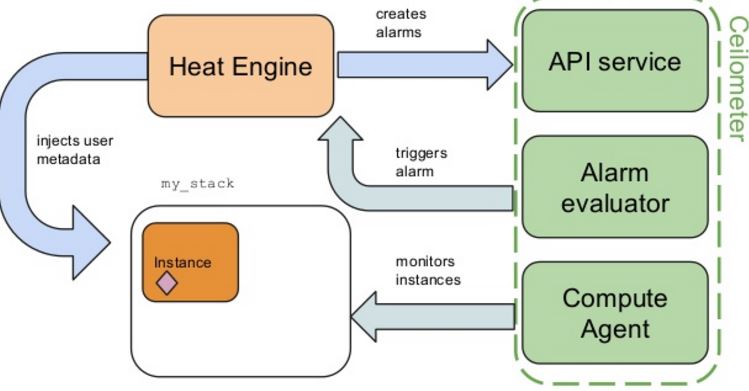
目前 OpenStack 实现的是类似 AWS 的自动扩展架构:
- Ceilometer:类似于 AWS CloudWatch,监控指定的虚机的各种指标,并根据告警策略发出告警。
- Neutron LBaaS:类似于 AWS ELB,提供虚拟的负载均衡器
- Heat:类似于 AWS Auto Scaling,提供自动扩展功能,以及承担编排器角色。它通过 HOT 创建所有需要的对象,包括 Ceilometer alarm。
3.1.2 简单例子:仅使用 Heat + Ceilometer
(1)定义 heat HOT 文件 simple-no-lb.yaml,内容如下
heat_template_version: 2016-02-16
description: A simple auto scaling group by Sammy Liu resources: group: type: OS::Heat::AutoScalingGroup #定义自动扩展组 properties: cooldown: 60 #冷却时间,单位秒 desired_capacity: 2 #起始组内虚机数目 max_size: 5 #组内最大虚机数目 min_size: 1 #组内最小虚机数目 resource: type: OS::Nova::Server #组内资源即虚机的类型 properties: image: ‘cirros‘ #虚机所使用的Glance 镜像的名称 metadata: {"metering.stack": {get_param: "OS::stack_id"}} #设置虚机的元数据 ‘metering.stack‘ 为 heat stack ID flavor: m1.tiny networks: - network: sammynet1
scaleup_policy: #向上扩展策略 type: OS::Heat::ScalingPolicy properties: adjustment_type: change_in_capacity #heat 支持三种调整方式:change_in_capacity (new = current + adjustment), exact_capacity (new = adjustment), percent_change_in_capacity (在current 的基础上上按照 adjustment 的 百分比调整) auto_scaling_group_id: {get_resource: group} #该 policy 的 group 就是上面定义的 ‘group ‘ cooldown: 60 #冷却时间 scaling_adjustment: 1 #每次的调整量 cpu_alarm_high: #定义一个 ceilometer alarm type: OS::Ceilometer::Alarm properties: meter_name: cpu_util #监控虚机的 cpu_util statistic: avg #statistic 的计算方法为 avg 即平均值法 period: 60 #统计周期 evaluation_periods: 1 #连续几个周期才算有效 threshold: 50 #cpu_util 的阈值 alarm_actions: #该告警在alarm 状态时的 action。还可以定义象 ok_actions, insufficient_data_actions 等等 - {get_attr: [scaleup_policy, alarm_url]} matching_metadata: {‘metadata.user_metadata.stack‘: {get_param: "OS::stack_id"}} #设置 ceilometer statistic 的计算方位为元数据 ‘metering.stack‘ 为 stack id 的虚机 comparison_operator: gt #检测值和阈值的比较方式为 gt 即大于
(2)创建 heat stack
heat stack-create -f simple-no-lb.yaml simple-no-lb
(3)创建成功后生成的 heat resource 和两个虚机
[email protected]:/home/sammy# heat stack-list +--------------------------------------+----------------------+-----------------+----------------------+--------------+ | id | stack_name | stack_status | creation_time | updated_time | +--------------------------------------+----------------------+-----------------+----------------------+--------------+ | 51f3ec34-8914-475d-b9df-c50be7893041 | simple-no-lb | CREATE_COMPLETE | 2016-02-21T14:17:13Z | None | +--------------------------------------+----------------------+-----------------+----------------------+--------------+
[email protected]:/home/sammy# heat resource-list 51f3ec34-8914-475d-b9df-c50be7893041 +----------------+--------------------------------------+----------------------------+-----------------+----------------------+ | resource_name | physical_resource_id | resource_type | resource_status | updated_time | +----------------+--------------------------------------+----------------------------+-----------------+----------------------+ | cpu_alarm_high | 76a82c7a-89e0-4888-bd0a-0c7e2c70df29 | OS::Ceilometer::Alarm | CREATE_COMPLETE | 2016-02-21T14:17:13Z | | group | f7d2c038-a955-4930-b757-3a12a22640c4 | OS::Heat::AutoScalingGroup | CREATE_COMPLETE | 2016-02-21T14:17:13Z | | scaleup_policy | 5a5fdfc1b396403aa5d010e3a79d2eb3 | OS::Heat::ScalingPolicy | CREATE_COMPLETE | 2016-02-21T14:17:13Z | +----------------+--------------------------------------+----------------------------+-----------------+----------------------+
三个资源中:group (AutoScalingGroup)被 scaleup_policy (ScalingPolicy) 所使用,scaleup_policy 被 cpu_alarm_high (Ceilometer::Alarm) 使用。
(4)alarm的细节
[email protected]:/home/sammy# ceilometer alarm-show 76a82c7a-89e0-4888-bd0a-0c7e2c70df29 +---------------------------+--------------------------------------------------------------------------+ | Property | Value | +---------------------------+--------------------------------------------------------------------------+ | alarm_actions | [u‘https://devci23.open-test.ibmcloud.com:8000/v1/signal/arn%3Aopenstack | | | %3Aheat%3A%3Abd6b9346393d469eb52734bc3ed42b3c%3Astacks%2Fsimple-no- | | | lb%2F51f3ec34-8914-475d-b9df-c50be7893041%2Fresources%2Fscaleup_policy?T | | | imestamp=2016-02-21T14%3A17%3A12Z&SignatureMethod=HmacSHA256&AWSAccessKe | | | yId=0211a96fd1114eca9d4da8167fbdae5a&SignatureVersion=2&Signature=ji0r5c | | | vQGAIEGkmkCiehxHTCBsDr4jfecv%2BHia6aSbg%3D‘] | | alarm_id | 76a82c7a-89e0-4888-bd0a-0c7e2c70df29 | | comparison_operator | gt | | description | Alarm when cpu_util is gt a avg of 50.0 over 60 seconds | | enabled | True | | evaluation_periods | 1 | | meter_name | cpu_util | | name | simple-no-lb-cpu_alarm_high-leb4nvtkincw | | period | 60 | | project_id | bd6b9346393d469eb52734bc3ed42b3c | | query | metadata.user_metadata.stack == 51f3ec34-8914-475d-b9df-c50be7893041 | | statistic | avg | | threshold | 50.0 | | type | threshold | +---------------------------+--------------------------------------------------------------------------+
Ceilometer 的 statistics 方法:
[email protected]:/home/sammy# heat output-show 51f3ec34-8914-475d-b9df-c50be7893041 ceilometer_statistics_query "ceilometer statistics -m cpu_util -q metadata.user_metadata.stack=51f3ec34-8914-475d-b9df-c50be7893041 -p 60 -a avg\\n"
[email protected]:/home/sammy# ceilometer statistics -m cpu_util -q metadata.user_metadata.stack=51f3ec34-8914-475d-b9df-c50be7893041 -p 60 -a avg +--------+---------------------+---------------------+---------------+----------+---------------------+---------------------+ | Period | Period Start | Period End | Avg | Duration | Duration Start | Duration End | +--------+---------------------+---------------------+---------------+----------+---------------------+---------------------+ | 60 | 2016-02-21T14:29:31 | 2016-02-21T14:30:31 | 4.8197740113 | 10.0 | 2016-02-21T14:30:01 | 2016-02-21T14:30:11 | | 60 | 2016-02-21T14:30:31 | 2016-02-21T14:31:31 | 4.73989071038 | 11.0 | 2016-02-21T14:31:01 | 2016-02-21T14:31:12 | | 60 | 2016-02-21T14:31:31 | 2016-02-21T14:32:31 | 4.81666666667 | 11.0 | 2016-02-21T14:32:01 | 2016-02-21T14:32:12 | +--------+---------------------+---------------------+---------------+----------+---------------------+---------------------+
(4)简要过程
(a)Ceilometer 每个 60s 运行 "ceilometer statistics -m cpu_util -q metadata.user_metadata.stack=51f3ec34-8914-475d-b9df-c50be7893041 -p 60 -a avg\\n",求得其 avg 值,和阈值 50.0 比较。如果大于 50.0,则发出 alarm。注意这里只统计虚机的元数据 ‘metering.stack’ 的值为 stack id 即 "51f3ec34-8914-475d-b9df-c50be7893041" 的所有虚机。
(b)该 alarm 的 action 是 ‘https://devci23.open-test.ibmcloud.com:8000/v1/signal/arn%3Aopenstack%3Aheat%3A%3Abd6b9346393d469eb52734bc3ed42b3c%3Astacks%2Fsimple-no-lb%2F51f3ec34-8914-475d-b9df-c50be7893041%2Fresources%2Fscaleup_policy?Timestamp=2016-02-21T14%3A17%3A12Z&SignatureMethod=HmacSHA256&AWSAccessKeyId=0211a96fd1114eca9d4da8167fbdae5a&SignatureVersion=2&Signature=ji0r5cvQGAIEGkmkCiehxHTCBsDr4jfecv%2BHia6aSbg%3D’,其实是调用 heat 的 scaleup_policy,并传入了几个包括 Timestamp的参数。
(c)heat 的 scaleup_policy 被触发,计算新的虚机数目 new_capacity,然后调用 resize(new_capacity)来将 instance group 的 capacity 调整为 new_capacity。
3.1.3 OpenStack Kilo 版本中的 Neutron LBaaS V1 和 V2
目前(Kilo 和 Liberty 版本)Heat 只支持 Neutron LBaaS V1, V2 的支持将会在 M 版本中添加。在我的环境中,之前已经通过从 github neutron_lbaas xiangm 上拉取 Neutron LBaaS Kilo stable 代码的方法并且在使用 V2 版本。为了能够支持 Auto-scaling,需要将其降低到 V1 版本。下面简要描述其过程。 (关于直接安装 V1 版本,可以参考我的另一篇文章 Neutron 理解 (7): Neutron 是如何实现负载均衡器虚拟化的 [LBaaS V1 in Juno]).
(0)代码的根目录的路径:
- neutron_lbaas 代码:/opt/bbc/openstack-11.0-bbc148/neutron/lib/python2.7/site-packages/neutron_lbaas
- neutron 代码:/opt/bbc/openstack-11.0-bbc148/neutron/lib/python2.7/site-packages/neutron
(1)修改配置文件
/etc/neutron/neutron.conf:
service_plugins = neutron.services.l3_router.l3_router_plugin.L3RouterPlugin,neutron_lbaas.services.loadbalancer.plugin.LoadBalancerPlugin
/etc/neutron/neutron_lbaas.conf:
service_provider = LOADBALANCER:Haproxy:neutron_lbaas.services.loadbalancer.drivers.haproxy.plugin_driver.HaproxyOnHostPluginDriver:default
/etc/neutron/services/loadbalancer/haproxy/lbaas_agent.ini
interface_driver = neutron.agent.linux.interface.BridgeInterfaceDriver
(2)创建 /usr/local/bin/neutron-lbaas-agent 可执行文件
import sys from neutron_lbaas.services.loadbalancer.agent.agent import main if __name__ == "__main__": sys.exit(main())
(3)创建 neutron-lbaas-agent 服务
创建 /etc/init.d/neutron-lbaas-agent 文件
ln -s /lib/init/upstart-job /etc/init.d/neutron-lbaas-agent
创建 /etc/init/neutron-lbaas-agent.conf 文件:
start on starting neutron-linuxbridge-agent stop on stopping neutron-linuxbridge-agent env REQUESTS_CA_BUNDLE=/etc/ssl/certs/ca-certificates.crt respawn exec start-stop-daemon --start --chuid neutron --exec /usr/local/bin/neutron-lbaas-agent -- --config-dir /etc/neutron --config-file /etc/neutron/neutron.conf --config-file /etc/neutron/services/loadbalancer/haproxy/lbaas_agent.ini --config-file /etc/neutron/neutron_lbaas.conf
(4)在控制节点重启 neutron-server 服务,在网络节点启动 neutron-lbaas-agent 服务
neutron 2257 1 0 08:36 ? 00:01:04 /opt/bbc/openstack-11.0-bbc148/neutron/bin/python /usr/local/bin/neutron-lbaas-agent --config-dir /etc/neutron --config-file /etc/neutron/neutron.conf --config-file /etc/neutron/services/loadbalancer/haproxy/lbaas_agent.ini --config-file /etc/neutron/neutron_lbaas.conf
需要注意的是:
(1)设置 service_plugins 和 service_provider 需要注意 V1 所使用的类的路径。neutron-lbaas 项目中,V1 和 V2 代码混杂在一起,所有到处都是同样名称的文件和类,在不同的目录下,分别被V1 和 V2 使用。
(2)Neutron 的 V1 和 V2 lbaas agent 不可以同时运行。
(3)neutron-lbaas-agent 服务文件的创建,可以参考 neutron-lbaasv2-agent 的各文件
(4)neutron-server 和 neutron-lbaas(v2)-agent 的修改必须同步,否则会出现 agent 和 server 无法通信的情况
3.1.4 综合例子:使用 Heat + Ceilometer + Neutron LBaaS V1
(1)几个 Heat HOT 文件
simple. yaml:
heat_template_version: 2014-10-16 description: A simple auto scaling group. resources: group: type: OS::Heat::AutoScalingGroup properties: cooldown: 60 desired_capacity: 2 max_size: 5 min_size: 1 resource: type: OS::Nova::Server::Cirros #在 lb_server.yaml 中定义的一个新类型 properties: image: ‘cirros‘ metadata: {"metering.stack": {get_param: "OS::stack_id"}} flavor: m1.tiny pool_id: {get_resource: pool} network_id: sammynet1 scaleup_policy: type: OS::Heat::ScalingPolicy properties: adjustment_type: change_in_capacity auto_scaling_group_id: {get_resource: group} cooldown: 60 scaling_adjustment: 1 scaledown_policy: #新增资源收缩策略 type: OS::Heat::ScalingPolicy properties: adjustment_type: change_in_capacity auto_scaling_group_id: {get_resource: group} cooldown: 60 scaling_adjustment: -1 #虚机数据减一
cpu_alarm_high: type: OS::Ceilometer::Alarm properties: meter_name: cpu_util statistic: avg period: 60 evaluation_periods: 1 threshold: 50 alarm_actions: - {get_attr: [scaleup_policy, alarm_url]} matching_metadata: {‘metadata.user_metadata.stack‘: {get_param: "OS::stack_id"}} comparison_operator: gt cpu_alarm_low: #新增检测值低于阈值告警 type: OS::Ceilometer::Alarm properties: description: Scale-down if the max CPU < 30% for 60 secs meter_name: cpu_util statistic: avg period: 60 evaluation_periods: 1 threshold: 30 #阈值为 30 alarm_actions: - {get_attr: [scaledown_policy, alarm_url]} matching_metadata: {‘metadata.user_metadata.stack‘: {get_param: "OS::stack_id"}} comparison_operator: lt #比较方法为”小于“ monitor: # 定义 Neutron LbaaS 的 health monitor type: OS::Neutron::HealthMonitor properties: type: TCP #注意 HAProxy 其实是不支持 PING 的 delay: 10 max_retries: 5 timeout: 10
pool: #定义 Neutron LbaaS Pool type: OS::Neutron::Pool properties: protocol: HTTP monitors: [{get_resource: monitor}] #关联 monitor 和 pool subnet_id: 66a47602-f419-4e40-bec8-929ee0c99302 lb_method: ROUND_ROBIN vip: protocol_port: 80 subnet: sammysubnet1 lb: type: OS::Neutron::LoadBalancer properties: protocol_port: 80 pool_id: {get_resource: pool} #关联 lb(vip)和 pool # assign a floating ip address to the load balancer pool. #给 vip(lb)分配一个浮动IP lb_floating: type: OS::Neutron::FloatingIP properties: floating_network_id: 8f361a34-52bf-4504-a11b-30c53c0a7bb8 port_id: {get_attr: [pool, vip, port_id]}
lb-server.yaml:
description: A load-balancer server parameters:
#定义 image、flavor、pool_id、network_id、user_data 和 metadata 等几个参数
... resources: server: type: OS::Nova::Server properties: flavor: {get_param: flavor} image: {get_param: image} metadata: {get_param: metadata} networks: - network: {get_param: network_id} user_data: {get_param: user_data} user_data_format: {get_param: user_data_format} member: type: OS::Neutron::PoolMember properties: pool_id: {get_param: pool_id} #将 member 加入 pool 中 address: {get_attr: [server, first_address]} protocol_port: 80
env.yaml:
resource_registry: "OS::Nova::Server::Cirros": "lb-server.yaml"
(2)创建 heat stack
结果除了两个虚机外,还有如下的 heat resource:
[email protected]:~# heat resource-list f27cde5a-efa3-4d40-a76f-e0f69331e75b +------------------+--------------------------------------+----------------------------+-----------------+----------------------+ | resource_name | physical_resource_id | resource_type | resource_status | updated_time | +------------------+--------------------------------------+----------------------------+-----------------+----------------------+ | cpu_alarm_high | 6297a648-978f-4781-89fa-65d6492f862b | OS::Ceilometer::Alarm | CREATE_COMPLETE | 2016-02-19T13:57:46Z | | cpu_alarm_low | 50d4c4ad-7c1a-4d23-a308-0091002532f9 | OS::Ceilometer::Alarm | CREATE_COMPLETE | 2016-02-19T13:57:46Z | | group | b6a2862d-7723-40d8-b1c1-2a15f0814f58 | OS::Heat::AutoScalingGroup | CREATE_COMPLETE | 2016-02-19T13:57:46Z | | lb | | OS::Neutron::LoadBalancer | CREATE_COMPLETE | 2016-02-19T13:57:46Z | | lb_floating | 3a6e3d4e-aace-4930-b98c-7b2ac81b54ac | OS::Neutron::FloatingIP | CREATE_COMPLETE | 2016-02-19T13:57:46Z | | monitor | 939aaafd-4efc-4130-b71e-fe6caab2025a | OS::Neutron::HealthMonitor | CREATE_COMPLETE | 2016-02-19T13:57:46Z | | pool | dd41f00a-8928-4c05-bfc3-b3824d9ef7e0 | OS::Neutron::Pool | CREATE_COMPLETE | 2016-02-19T13:57:46Z | | scaledown_policy | 640e97fa3aff445aa0df086737587a12 | OS::Heat::ScalingPolicy | CREATE_COMPLETE | 2016-02-19T13:57:46Z | | scaleup_policy | 21d42d330144473dbe691d366b1fff21 | OS::Heat::ScalingPolicy | CREATE_COMPLETE | 2016-02-19T13:57:46Z | +------------------+--------------------------------------+----------------------------+-----------------+----------------------+
(3)简要自动伸缩过程
- 在2个虚机内都启动 HTTP 服务
- pool 内的2个虚机的平均 cpu_util 超过 50%,增加一个虚机,总虚机数目达到3,并加入到 Neutron LB pool 中成为一个新的 member
- 继续检测,发现3个虚机的平均 cpu_util 仍然超过 50%,增加一个虚机,总虚机数目达到4,并加入到 Neutron LB pool 中成为一个新的 member
- 继续检测,经过一段时间后,发现4个虚机的平均 cpu_util 低于 30%,减少一个虚机,总虚机数目下降为 3,并将其从 Neutron LB pool 中删除
- 继续检测,3 个虚机的瓶颈 cpu_util 稳定在 40 左右,不再执行自动伸缩
注:以上两个例子,只是测试和验证用例,真正在生产环境使用中,还有更多的事情要做。
3.2 Auto-scaling 在将来的实现
曾经和社区 Heat 人士(IBM 北京研究院 Tent Qi Ming 博士,Heat Core member,Senlin 发起人之一)进行过交流,大概意思如下:
- 目前 Heat 中的 Auto-scaling 是依照 AWS 的 Auto-scaling 实现的,在实际应用中存在不足
- Heat 认为 Auto-scaling 不是它的 mission 范围内,它的主要和唯一的任务是提供 OpenStack 资源编排接口
- Heat 在将来不会继续增加 Auto-scaling 功能,除了在 M 版本支持 Neutron LBaaS V2 外
- 将来 Auto-scaling 功能将会在新的项目 Senlin 中实现。在项目在 2015年5月发布,它提供 OpenStack Clustering(集群)功能,可以实现包括 Auto-scaling、HA、负载均衡(load-balancing) 等功能
参考链接
- 阿里云弹性伸缩服务入门指南
- AWS Auto Scaling
- 探索 OpenStack 之(16):计量模块 Ceilometer 介绍及优化
- 探索 OpenStack 之(17):计量模块 Ceilometer 中的数据收集机制
- Neutron 理解 (7): Neutron 是如何实现负载均衡器虚拟化的 [LBaaS V1 in Juno]
以上是关于OpenStack 企业私有云的几个需求:自动扩展(Auto-scaling) 支持的主要内容,如果未能解决你的问题,请参考以下文章
OpenStack 企业私有云的若干需求:混合云支持 (Hybrid Cloud Support)