使用Python统计深圳市公租房申请人省份年龄统计
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Python统计深圳市公租房申请人省份年龄统计相关的知识,希望对你有一定的参考价值。
使用Python,htmlParser来统计深圳市保障房申请人的原籍省份分布,年龄分布等。从侧面可以反映鹏城人的地域分布。以下python代码增大了每一次获取的记录数,从而少提交几次请求。如果按照WEB主页设定的每一次请求最多50个记录,那就得提交数千次请求,显然费时。另外,也可以使用多线程处理,快速获得数据,解析数据,然后使用pandas,matplotlib等工具进行数据处理和绘制。查询了系统,截止2016年2月,轮候系统的保障房人数大概4万多,公租房轮候人数大概5万,以下数据仅作学习使用,统计结果如下:
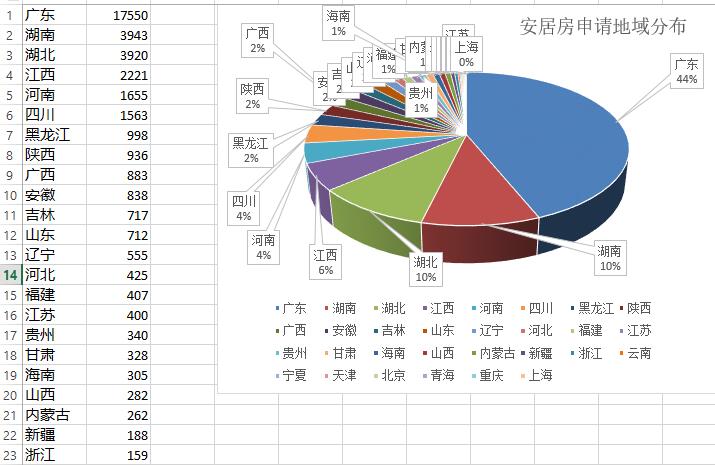
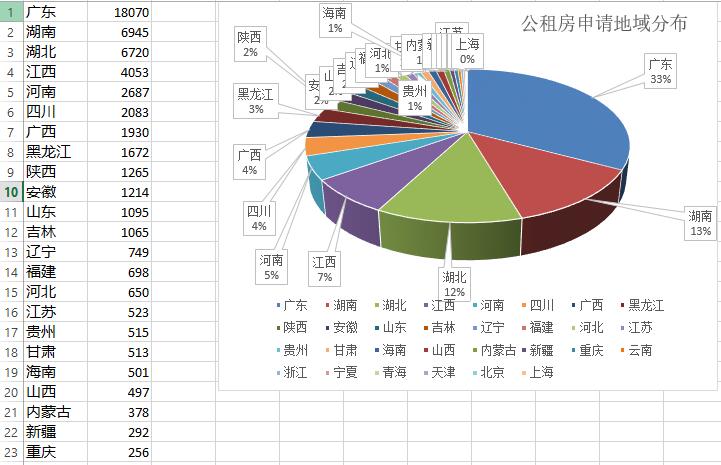
毫无疑问,广东本地人申请的占多数。前十名当中,和广东接壤的省份也占了不少比例,特别是两湖,江西,剩下的由人口大省占据。深圳保障房建设速度和规模居全国首位,但是因为人数众多,所以需要排队等候。远离XX的房东,避免年年涨的房租,那就加入排队轮候大军吧。


1 # -*- coding:utf-8 -*- 2 import time 3 import json 4 import lxml.html 5 from lxml import etree 6 from HTMLParser import HTMLParser #使用beautifulsoup也可以 7 8 #http://www.crummy.com/software/BeautifulSoup/ 9 #http://blog.csdn.net/my2010sam/article/details/14526223 10 11 try: 12 from urllib.request import urlopen,Request 13 except: 14 from urllib2 import urlopen, Request 15 16 17 area={"11":"北京","12":"天津","13":"河北","14":"山西","15":"内蒙古","21":"辽宁","22":"吉林","23":"黑龙江","31":"上海", 18 "32":"江苏","33":"浙江","34":"安徽","35":"福建","36":"江西","37":"山东","41":"河南","42":"湖北","43":"湖南", 19 "44":"广东","45":"广西","46":"海南","50":"重庆","51":"四川","52":"贵州","53":"云南","54":"西藏","61":"陕西", 20 "62":"甘肃","63":"青海","64":"宁夏","65":"新疆","71":"台湾","81":"香港","82":"澳门","91":"国外"} 21 ages =[0]*11 22 provinceCnt=[0]*91 23 RECORD_BY_EACH_PAGE = [10,15,30,50,5000] 24 currentYear=time.localtime()[0]#get year 25 URL_BY_PAGESIZE=‘http://bzflh.szjs.gov.cn/TylhW/lhmcAction.do?pageSize=%s&method=queryYgbLhmcInfo&waittype=2‘ 26 27 #http://XXX.cn?pageSize=XXX&page=XXX,waittype=2 公租房,waittype=1 安居房 28 URL_BY_PAGE_PAGESIZE =‘http://bzflh.szjs.gov.cn/TylhW/lhmcAction.do?pageSize=%s&method=queryYgbLhmcInfo&waittype=%s&page=%s‘ 29 30 #Social_Housing_Items=[URL_BY_PAGE_PAGESIZE_GongZuFang,URL_BY_PAGE_PAGESIZE_AnJuFang] 31 32 def getHomePage(url,pagesize): 33 try: 34 request = Request(url) 35 lines=urlopen(request,timeout=10).read() 36 if len(lines)<20: 37 return None #no data 38 except Exception as e: 39 print e 40 else: 41 if pagesize!=10 and pagesize!=15 and pagesize!=30 and pagesize!=50 and pagesize !=5000: 42 pagesize = 15 #default as 15 record each page 43 lines=lines.decode(‘utf-8‘) 44 splitLines=lines.split(‘\r\n‘) 45 for line in splitLines: 46 #if "pageSize" in line: 47 #print line[:50] 48 if "pagebanner" in line: 49 totalPage= line[:50].split(‘>‘)[1].split(‘ ‘)[0] 50 totalPage=totalPage.split(‘,‘) 51 if len(totalPage)>1: 52 pages=(int(totalPage[0])*1000+int(totalPage[1]))/pagesize 53 return pages 54 55 def getRawData(url): 56 try: 57 request = Request(url) 58 lines=urlopen(request,timeout=10).read() 59 if len(lines)<20: 60 return None #no data 61 except Exception as e: 62 print e 63 else: 64 return lines.decode(‘utf-8‘) 65 66 def getIdentityInfo(code): 67 """ 68 :param code: identity code showing province and date 69 :return: province,date 70 """ 71 provinceCode=code[:2] 72 cityCode = code[2:6] 73 date=code[6:10] 74 return provinceCode,date 75 76 class Dataparser(HTMLParser): 77 def __init__(self): 78 HTMLParser.__init__(self) 79 self.tr=False 80 self.td =0 81 self.data =False 82 def handle_starttag(self,tag,attrs): 83 """ 84 参数tag是标签名,比如td,tr‘,attrs为标签所有属性(name,value)列表,这里是[(‘class‘,‘para‘)] 85 :param tag: 86 :param attrs: 87 :return: 88 """ 89 if tag==‘tr‘: 90 self.tr=True 91 if tag ==‘td‘and self.tr==True: 92 self.data = True 93 for name,value in attrs: 94 print "name and value are",name,value 95 def handle_endtag(self,tag): 96 if tag==‘td‘: 97 self.data = False 98 #print "a end tag:",tag,self.getpos() 99 100 def handle_data(self,data): 101 if self.data and len(data)==18 and ‘\r\n‘ not in data: 102 #print data #ID card NO 103 provinceCode,date=getIdentityInfo(data) 104 ageRange=currentYear - int(date) 105 if ageRange>=100: 106 print ‘test‘,ageRange 107 #ages[ageRange/10] +=1 108 #temp=area[provinceCode].decode(‘utf-8‘) 109 PC=int(provinceCode) 110 provinceCnt[PC]+=1 111 112 if __name__ ==‘__main__‘: 113 #计算总共页数,每页可以自己限定 114 for type in range(2): 115 pages=getHomePage(URL_BY_PAGE_PAGESIZE%(RECORD_BY_EACH_PAGE[0],type+1,1),RECORD_BY_EACH_PAGE[4]) 116 parse=Dataparser() 117 while pages>=1: 118 #for page in range(pages): 119 lines=getRawData(URL_BY_PAGE_PAGESIZE%(RECORD_BY_EACH_PAGE[4],type+1,pages)) 120 parse.feed(lines) 121 #parse.close() 122 pages-=1 123 parse.close() 124 if type==0: 125 print "深圳安居房申请人全国分布情况统计:" 126 for i in provinceCnt: 127 if i>0: #只打印有数据的省份 128 pIndex=str(provinceCnt.index(i)) 129 print area[pIndex],i 130 provinceCnt =[0]*91 131 elif type==1: 132 print "深圳公租房申请人全国分布情况统计:" 133 for i in provinceCnt: 134 if i>0: #只打印有数据的省份 135 pIndex=str(provinceCnt.index(i)) 136 print area[pIndex],i 137 provinceCnt =[0]*91
以上是关于使用Python统计深圳市公租房申请人省份年龄统计的主要内容,如果未能解决你的问题,请参考以下文章