Spark数据传输及ShuffleClient(源码阅读)
Posted 超大的皮卡丘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark数据传输及ShuffleClient(源码阅读)相关的知识,希望对你有一定的参考价值。
我们都知道Spark的每个task运行在不同的服务器节点上,map输出的结果直接存储到map任务所在服务器的存储体系中,reduce任务有可能不在同一台机器上运行,所以需要远程将多个map任务的中间结果fetch过来。那么我们就来学习下shuffleClient。shuffleClient存在于每个exeuctor的BlockManager中,它不光是将shuffle文件上传到其他executor或者下载到本地的客户端,也提供了可以被其他exeuctor访问的shuffle服务.当有外部的(其他节点)shuffleClient时,新建ExternalShuffleClient,默认为BlockTransferService.那么真正init的实现方法在NettyBlockTransferService中。
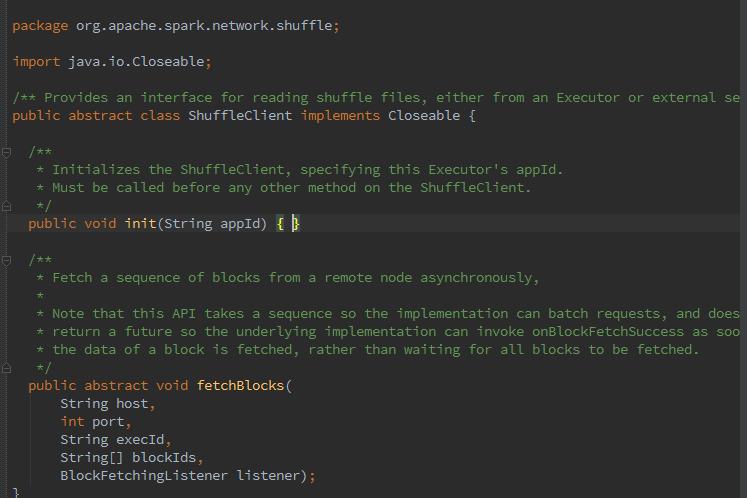
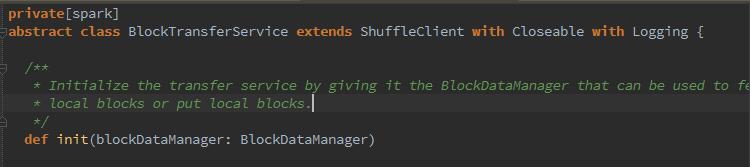
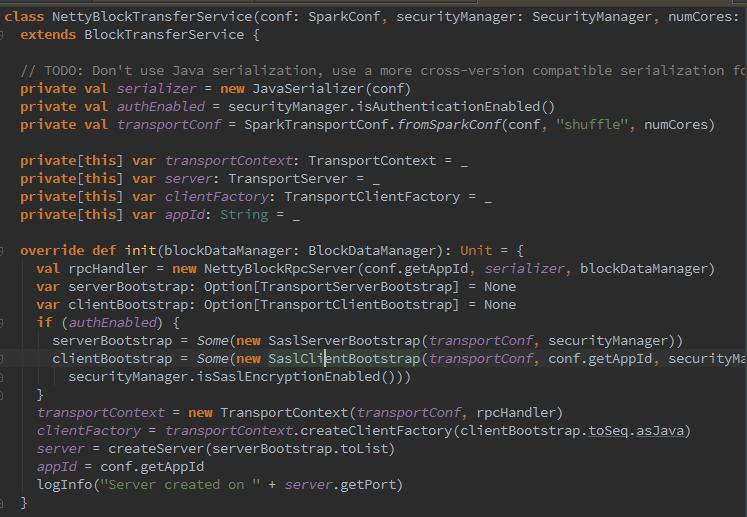
如代码中所示,抽象类blockTransferservice继承自shuffleClient,NettyBlockTransferService实现了shuffleClient的init抽象方法(竟然是java写的)进行初始化提供服务。初始化的过程为:创建NettyBlockRpcServer,构造TransportContext上下文,同时创建了clientFactory,最终创建了Netty服务器TransportServer,可修改属性spark.blockManager.port改变TransportServer的端口。
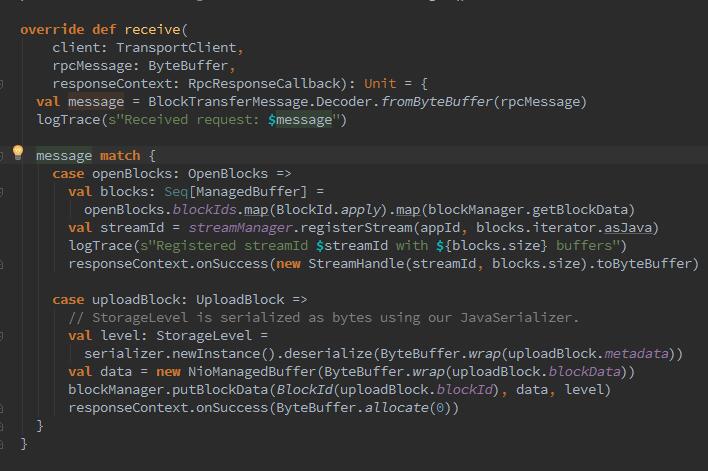
我们会有疑问,上面那一坨,是干嘛的?我们都知道,map和reduce任务处于不同节点时,reduce任务需要从远端fetch map任务的中间结果输出,NettyBlockRpcServer提供打开,下载Block文件的功能(中间结果在backet中)。NettyBlockRpcServer为了容错,还会将数据备份到其他节点。在new 了之后会根据接收到的message消息,匹配是打开block还是上传block进行容错。如图:
在new完NettyBlockRpcServer后,开始构造传输的上下文TransportContext.构造它的主要作用是,它将既可以创建Netty服务,也可以创建Netty访问客户端,主要包含:
1、TransportConf,控制Netty框架提供的shuffle I/O交互的客户端和服务端线程数量(又发现新的参数)。

2、RpcHandler,负责shuffle的I/O服务端在接受到客户端的RPC请求后,提供打开Block或者上传Block的RPC处理,就是刚才new的NettyBlockRpcServer,可以看到receive。
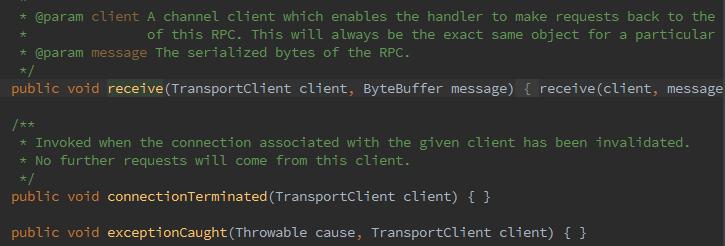 3、decoder,在shuffle的I/O服务端对客户端传来的ByteBuf进行解析,防止丢包和解析错误。
3、decoder,在shuffle的I/O服务端对客户端传来的ByteBuf进行解析,防止丢包和解析错误。
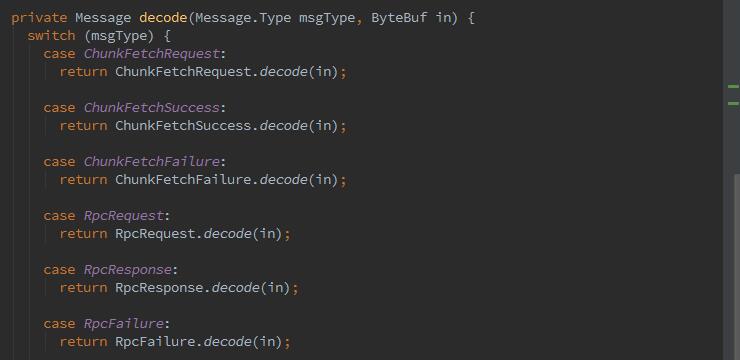
4、encoder,在shuffle的I/O客户端对消息内容进行编码,防止服务端丢包和解析错误。
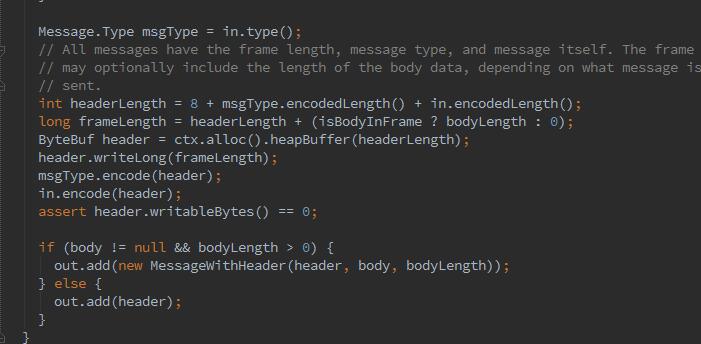
那么为什么需要decoder、encoder呢,这里要补习下传输原理,一般基于TCP/IP的流传输中,接收到的数据首先会被存储到一个socket缓冲区中,基于流的传输并不是一个数据包的队列,而是一个字节队列。即使发送两个独立的数据包,操作系统也不会作为2个消息处理,而作为一连串的字节。也就是说 发送的数据可能是 ABC UID GDI ,应用程序读取的时候数据很可能被分成了 AB CUID G DI,所以应该把接收到的数据整理成一个或多个有意义能让程序的逻辑更好理解的数据。
接下来,开始创建RPC客户端工程ClientFactory,它主要:1、缓存客户端列表。2、缓存客户端连接。3、节点之间取数据的连接数,通过spark.shuffle.io.numConnectionsPerPeer来配置,默认为1。4、客户端channel被创建时使用的类,可以使用属性spark.shuffle.io.mode来配置,默认为NioSocketChannel.(NIO还没仔细学习过,它的特点为所有的原始类型提供(Buffer)缓存支持,字符集编码解决方案,提供一个新的原始的I/O抽象Channel,支持锁和内存映射文件的文件访问接口;提供多路非阻塞的高伸缩性网络I/O)
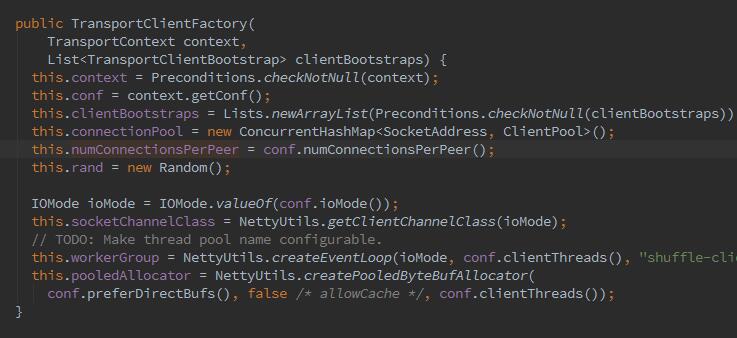
最终,createServer,看不懂NIO,回头恶补下。。
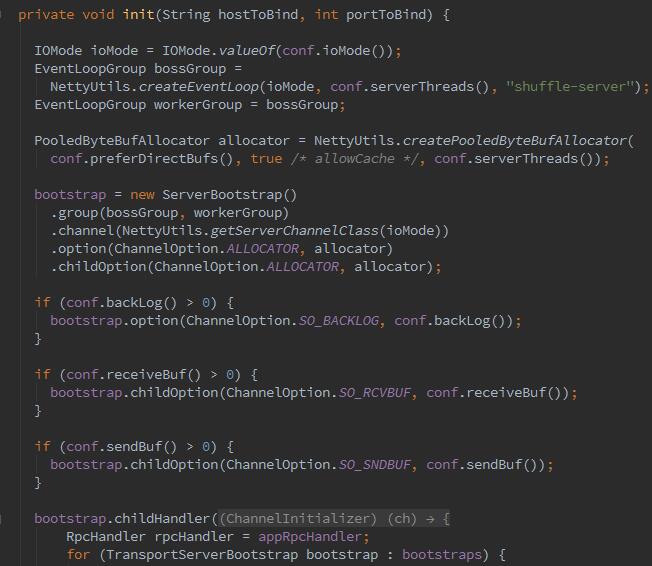
那么下来,到了最重要的环节,获取远程shuffle文件,也就是fetch数据的过程。这个过程就是之前上面NettyBlockTransferService中的fetchBlocks方法(在shuffle过程中,可以通过container日志查看到fetch数据):
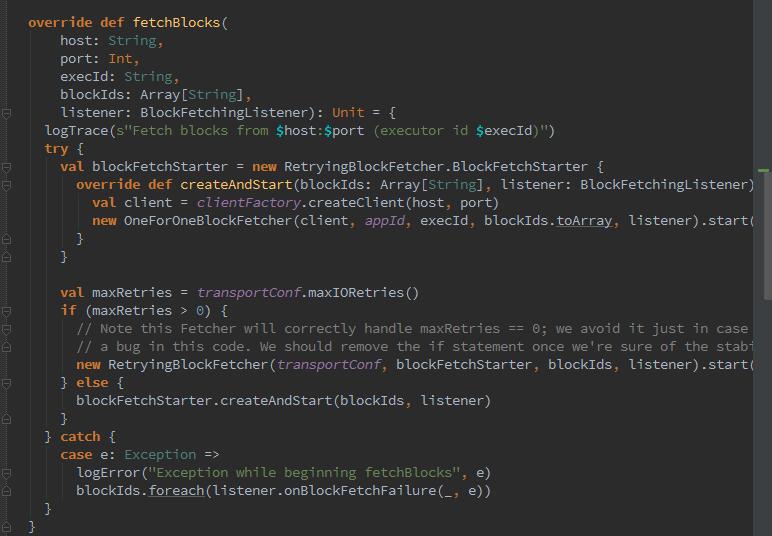
可以从传入的参数中看到,会传入拉取节点的IP与PORT以及blockId信息,进行数据的拉取。
那么之前,我们提到的上传shuffle文件,以便之前的拉取,也是先创建了Netty服务的客户端,同时我们可以看到它进行了serializer序列化并转化为了array()数组。随之将blockId、appId、execId等一起封装,调用Netty客户端的sendRpc方法将字节数组上传,同时毁掉函数RpcResponse-CallBack根据RPC的结果更改了上传状态。如下代码:
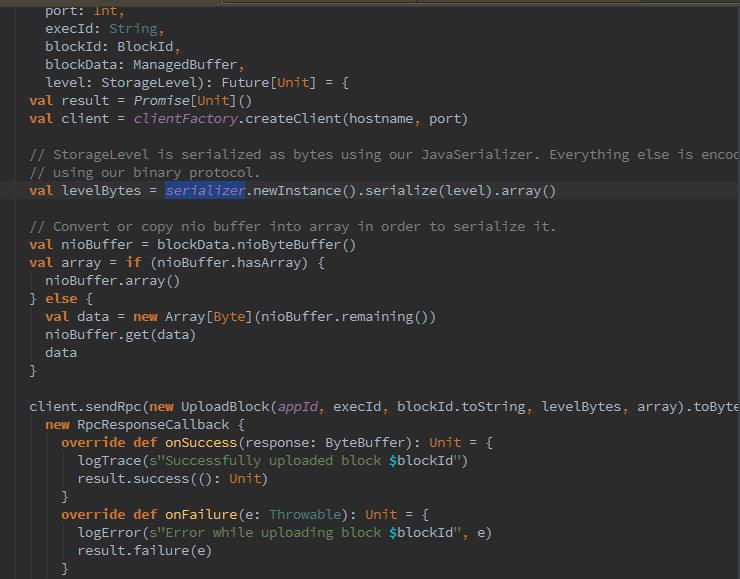
今天到此为止,开始敲代码~
以上是关于Spark数据传输及ShuffleClient(源码阅读)的主要内容,如果未能解决你的问题,请参考以下文章