SparkConf加载与SparkContext创建(源码阅读三)
Posted 超大的皮卡丘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparkConf加载与SparkContext创建(源码阅读三)相关的知识,希望对你有一定的参考价值。
sparkContext创建还没完呢,紧接着前两天,我们继续探索。。作死。。。
紧接着前几天我们继续SparkContext的创建:
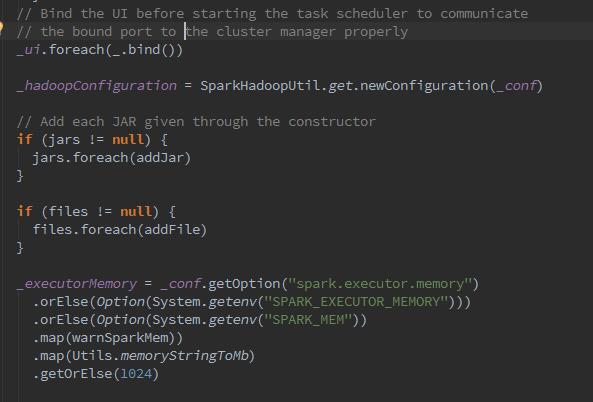
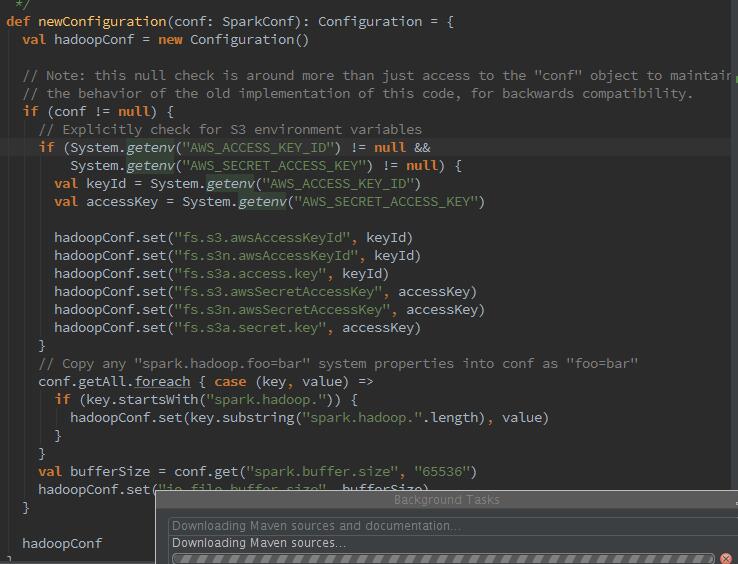
接下来从这里我们可以看到,spark开始加载hadoop的配置信息,第二张图中 new出来的Configuration正是hadoop的Configuration。同时,将所有sparkConf中所有以spark.hadoop.开头的属性都复制到了Hadoop的Configuration.同时又将spark.buffer.size复制为Hadoop的Configuration的配置的Io.file.buffer.size.随之加载相关jar包。再下来,我们可以看到:
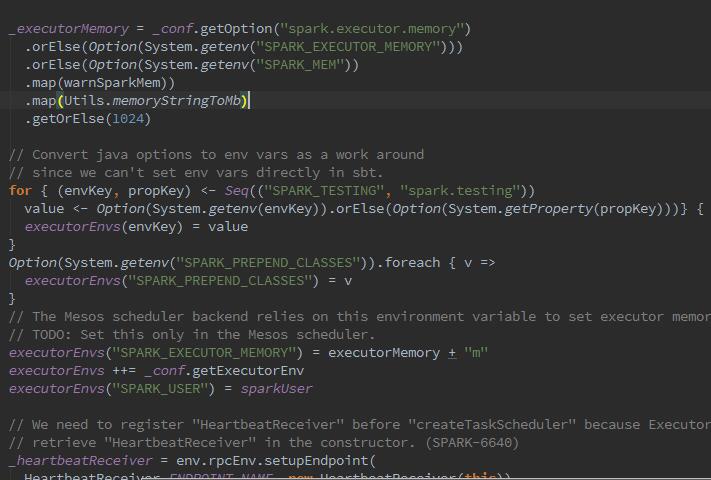
我们可以看到,将所有的executor的环境变量加载于_executorMemory以及executorEnvs,后续应该在注册executor时进行调用。随之创建_taskScheduler:
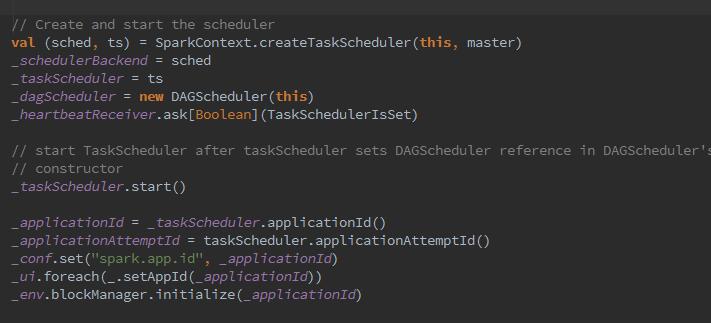
那么我们深入看下createTaskScheduler的过程:
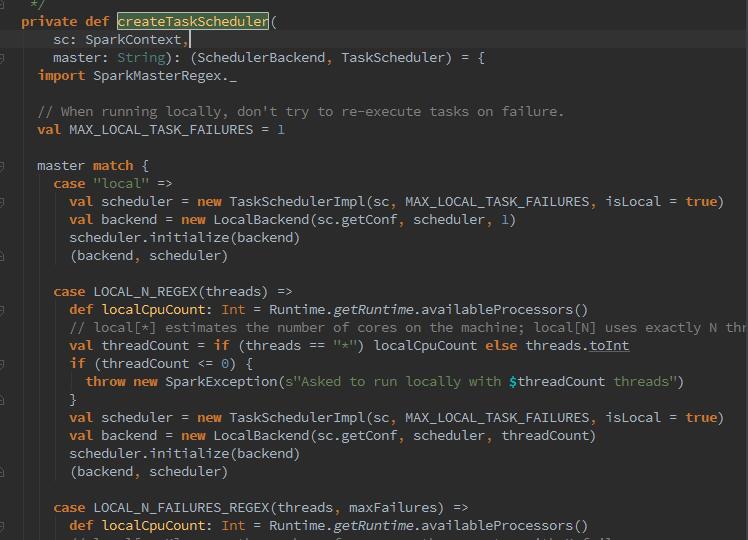
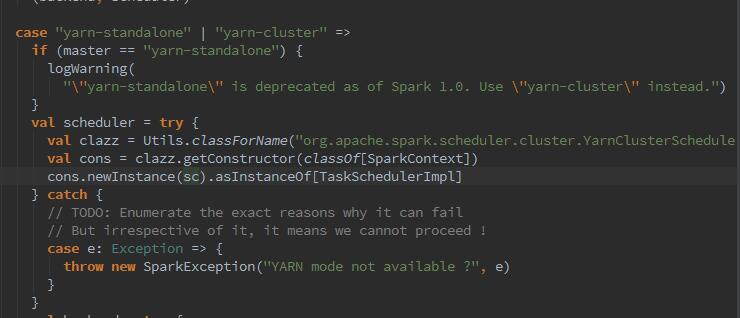
这里可以看到,它干了很多变态的事情,那么先说下,什么是TaskScheduler呢?TaskScheduler负责任务的提交,并且请求集群管理器对任务调度。TaskScheduler也可以看做任务调度的客户端。那么createTaskScheduler会根据master的配置(master match),匹配部署模式,利用反射创建yarn-cluster(本例图中为local及yarn-cluster),随之initialize了CoarseGrainedSchedulerBackend。(以后再深入了解CoarseGrainedSchedulerBackend)
代码中可以看到,创建了TaskSchedulerImpl,它是什么呢?
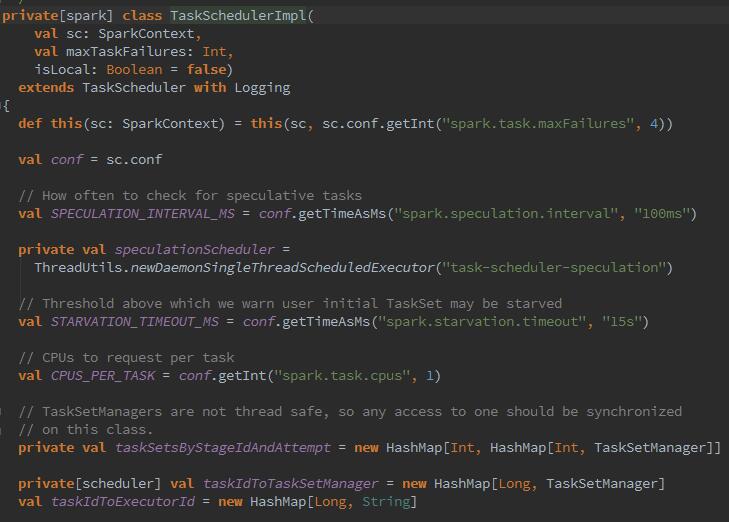
它从SparkConf中读取配置信息,包括每个任务分配的CPU数,失败task重试次数(可通过spark.task.maxFailures来配置),多久推测执行一次spark.speculation.interval(当然是在spark.speculation为true的情况下生效)等等。这里还有个调度模式,调度模式分为FIFO和FAIR两种,通过修改参数spark.scheduler.mode来改变。 最终创建TaskResultGetter,它的作用是对executor中的task的执行结果进行处理。
随之,开始创建DAG。DAGScheduler主要用于在任务正式交给TaskSchedulerImpl提交之前做一些准备工作。创建job,将DAG中的RDD划分到不同的Stage,提交Stage,等等。

我们继续深入看下它的创建过程。
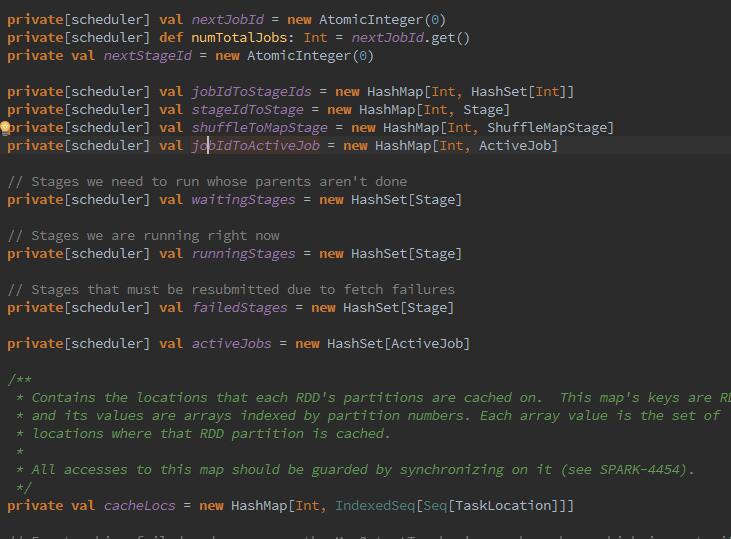
从这些变量中,我们可以看到,DAG是将所有jobId,stageId等信息之间的关系,以及缓存的RDD的partition位置等。比如getCacheLocs、getShuffleMapStage、getParentStagesAndId、newOrUsedShuffleStage。下来,通过applicationId注册并创建executor.
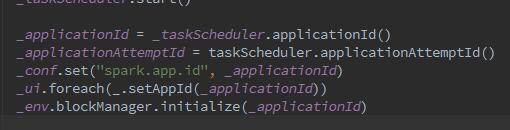
中间省略一万字(其实是没看懂),下来创建并启动ExecutorAllocationManager,它是干嘛的呢?
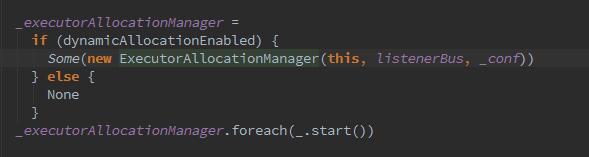
ExecutorAllocationManager是对所有的已分配的Executor进行管理。默认情况下不会创建ExecutorAllocationManager,可以修改属性spark.dynamicAllocation.enabled为true来创建。ExecutorAllocationManager可以设置动态分配最小Executor数量、动态分配最大Executor数量,每个Executor可以运行的Task数量等配置信息。(这个还真要试一下,没有配置过)ExecutorAllocationListener通过监听listenerBus里的事件、动态添加、删除exeuctor,通过Thread不断添加Executor,遍历Executor,将超时的Executor杀掉并移除。
参考文献:《深入理解Spark核心思想与源码解析》
以上是关于SparkConf加载与SparkContext创建(源码阅读三)的主要内容,如果未能解决你的问题,请参考以下文章