自然语言处理(NLP)的基础难点:分词算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理(NLP)的基础难点:分词算法相关的知识,希望对你有一定的参考价值。
参考技术A自然语言处理(NLP,Natural Language Processing)是人工智能领域中的一个重要方向,主要研究人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理的底层任务由易到难大致可以分为词法分析、句法分析和语义分析。分词是词法分析(还包括词性标注和命名实体识别)中最基本的任务,也是众多NLP算法中必不可少的第一步,其切分准确与否往往与整体结果息息相关。
金融领域分词的难点
分词既简单又复杂。简单是因为分词的算法研究已经很成熟了,大部分的算法(如HMM分词、CRF分词)准确率都可以达到95%以上;复杂则是因为剩下的5%很难有突破,主要可以归结于三点:
▲粒度,即切分时的最小单位,不同应用对粒度的要求不一样,比如“融资融券”可以是一个词也可以是两个词
▲歧义,比如“恒生”一词,既可指恒生公司,又可指恒生指数
▲未登录词,即未出现在算法使用的词典中的词,比如不常见的专业金融术语,以及各种上市公司的名称
在金融领域中,分词也具有上述三个难点,并且在未登录词方面的难点更为突出,这是因为金融类词汇本来就多,再加上一些专有名词不仅有全称还有简称,这就进一步增大了难度。
在实际应用中,以上难点时常会造成分词效果欠佳,进而影响之后的任务。尤其是在一些金融业务中,有许多需要与用户交互的场景,某些用户会用口语化的词汇描述业务,如果分词错误会影响用户意图的解析,这对分词的准确性提出了更高的要求。因此在进行NLP上层应用开发时,需要对分词算法有一定的了解,从而在效果优化时有能力对分词器进行调整。接下来,我们介绍几种常用的分词算法及其应用在金融中的优劣。
几种常见的分词算法
分词算法根据其核心思想主要分为两种:
第一种是基于字典的分词,先把句子按照字典切分成词,再寻找词的最佳组合方式,包括最大匹配分词算法、最短路径分词算法、基于N-Gram model的分词算法等;
第二种是基于字的分词,即由字构词,先把句子分成一个个字,再将字组合成词,寻找最优的切分策略,同时也可以转化成序列标注问题,包括生成式模型分词算法、判别式模型分词算法、神经网络分词算法等。
最大匹配分词寻找最优组合的方式是将匹配到的最长词组合在一起,主要的思路是先将词典构造成一棵Trie树(也称为字典树),Trie树由词的公共前缀构成节点,降低了存储空间的同时可以提升查找效率。
最大匹配分词将句子与Trie树进行匹配,在匹配到根结点时由下一个字重新开始进行查找。比如正向(从左至右)匹配“他说的确实在理”,得出的结果为“他/说/的确/实在/理”。如果进行反向最大匹配,则为“他/说/的/确实/在理”。
这种方式虽然可以在O(n)时间对句子进行分词,但是只单向匹配太过绝对,尤其是金融这种词汇较丰富的场景,会出现例如“交易费/用”、“报价单/位”等情况,所以除非某些词的优先级很高,否则要尽量避免使用此算法。
最短路径分词算法首先将一句话中的所有词匹配出来,构成词图(有向无环图DAG),之后寻找从起始点到终点的最短路径作为最佳组合方式,例:
我们认为图中每个词的权重都是相等的,因此每条边的权重都为1。
在求解DAG图的最短路径问题时,总是要利用到一种性质:即两点之间的最短路径也包含了路径上其他顶点间的最短路径。比如S->A->B->E为S到E到最短路径,那S->A->B一定是S到B到最短路径,否则会存在一点C使得d(S->C->B)<d(S->A->B),那S到E的最短路径也会变为S->C->B->E,这就与假设矛盾了。利用上述的最优子结构性质,可以利用贪心算法或动态规划两种求解算法:
(1)基于Dijkstra算法求解最短路径,该算法适用于所有带权有向图,求解源节点到其他所有节点的最短路径,并可以求得全局最优解;
(2)N-最短路径分词算法,该方法是对Dijkstra算法的扩展,在每一步保存最短的N条路径,并记录这些路径上当前节点的前驱,在最后求得最优解时回溯得到最短路径。这种方法的准确率优于Dijkstra算法,但在时间和空间复杂度上都更大。
相较于最大匹配分词算法,最短路径分词算法更加灵活,可以更好地把词典中的词组合起来,能更好地解决有歧义的场景。比如上述“他说的确实在理”这句话,用最短路径算法的计算结果为“他/说/的/确实/在理”,避免了正向最大匹配的错误。但是对于词典中未存在的词基本没有识别能力,无法解决金融领域分词中的“未登录词”难点。
N-Gram(又称N元语法模型)是基于一个假设:第n个词出现与前n-1个词相关,而与其他任何词不相关。在此种假设下,可以简化词的条件概率,进而求解整个句子出现的概率。
现实中,常用词的出现频率或者概率肯定比罕见词要大。因此,可以将求解词图最短路径的问题转化为求解最大概率路径的问题,即分词结果为“最有可能的词的组合“。
计算词出现的概率,仅有词典是不够的,还需要充足的语料,所以分词任务已经从单纯的“算法”上升到了“建模”,即利用统计学方法结合大数据挖掘,对“语言”(句子出现的概率)进行建模。
我们将基于N-gram模型所统计出的概率分布应用到词图中,可以得到词的概率图。对该词图用最短路径分词算法求解最大概率的路径,即可得到分词结果。
相较于前两种分词算法,基于N-Gram model的分词算法对词频进行了统计建模,在切分有歧义的时候力求得到全局最优值,比如在切分方案“证券/自营/业务”和“证券/自/营业/务”中,统计出“证券/自营/业务”出现的概率更大,因此结果有更高的准确率。但也依然无法解决金融场景中未登录词的问题。
生成式模型主要有隐马尔可夫模型(HMM,Hidden Markov Model)、朴素贝叶斯分类等。HMM是常用的分词模型,基于Python的jieba分词器和基于Java的HanLP分词器都使用了HMM。
HMM模型认为在解决序列标注问题时存在两种序列,一种是观测序列,即人们显性观察到的句子,另一种是隐状态序列,即观测序列的标签。假设观测序列为X,隐状态序列是Y,则因果关系为Y->X。因此要得到标注结果Y,必须对X的概率、Y的概率、P(X|Y)进行计算,即建立P(X,Y)的概率分布模型。
HMM算法可以在一定程度上解决未登录词的问题,但生成式模型的准确率往往没有接下来要谈到的判别式模型高。
判别式模型主要有感知机、支持向量机(SVM,Support Vector Machine)、条件随机场(CRF,Conditional Random Field)、最大熵模型等,其中感知机模型和CRF模型是常用的分词模型。
(1)平均感知机分词算法
感知机是一种简单的二分类线性模型,通过构造超平面,将特征空间(输入空间)中的样本分为正负两类。通过组合,感知机也可以处理多分类问题。但由于每次迭代都会更新模型的所有权重,被误分类的样本会造成很大影响,因此采用平均的方法,在处理完一部分样本后对更新的权重进行平均。
(2)CRF分词算法
CRF可以看作一个无向图模型,假设给定的标注序列为Y,观测序列为X,CRF对条件概率P(Y|X)进行定义,而不是对联合概率建模。
平均感知机算法虽然速度快,但仍不够准确。适合一些对速度要求高、对准确性要求相对不那么高的场景。CRF分词算法可以说是目前最常用的分词、词性标注和实体识别算法,它对未登陆词也有很好的识别能力,是目前在速度、准确率以及未登录词识别上综合表现最突出的算法,也是我们目前所采用的解决方案,但速度会比感知机慢一些。
在NLP中,最常用的神经网络为循环神经网络(RNN,Recurrent Neural Network),它在处理变长输入和序列输入问题中有着巨大的优势。LSTM(Long Short-Term Memory,长短期记忆网络)为RNN变种的一种,在一定程度上解决了RNN在训练过程中梯度消失和梯度爆炸的问题。
目前对于序列标注任务,业内公认效果最好的模型是BiLSTM+CRF。相比于上述其它模型,双向循环神经网络BiLSTM,可以更好地编码当前字等上下文信息,并在最终增加CRF层,核心是用Viterbi算法进行解码,以得到全局最优解,避免B,S,E这种不可能的标记结果的出现,提高准确率。
神经网络分词虽然能在准确率、未登录词识别上有更好的表现,但RNN无法并行计算,在速度上没有优势,所以该算法通常在算法研究、句子精确解析等对速度要求不高的场景下使用。
分词作为NLP底层任务之一,既简单又重要,很多时候上层算法的错误都是由分词结果导致的。因此,对于底层实现的算法工程师,不仅需要深入理解分词算法,更需要懂得如何高效地实现和调试。
而对于上层应用的算法工程师,在实际分词时,需要根据业务场景有选择地应用上述算法,比如在搜索引擎对大规模网页进行内容解析时,对分词对速度要求大于精度,而在智能问答中由于句子较短,对分词的精度要求大于速度。
NLP | NLP基础之中文分词
今天我们来讲一讲,自然语言处理中的最基础的技术,中文分词。
什么是中文分词
中文分词(Chinese Word Segmentation)指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序的过程。
主要的分词算法
基于词表的分词算法
1)、正向最大匹配算法(FMM):对于输入的一段文本从左至右、以贪心的方式切分出当前位置上长度最大的词。
分词原理是:单词的颗粒越大,所能表示的含义越确切。
该算法主要分为以下步骤:
(1).从左到右取待切分的前m个字符(m为词典里最长的词的字符数),如果序列不足最大词长,则选择全部序列。
(2).若这m个字符属于词典里的词,则匹配成功,然后将这m个字符切分出来,剩下的词语作为新的待切分的语句,如果这m个字符不属于词典里的词,则从右边开始,减少一个字符,剩余的m-1个字符继续匹配看是否在词典中,依次循环,逐到只剩下一个字。
(3). 重复以上步骤,直到句子切分完。
#使用正向最大匹配算法实现中文分词 FMMwords_dic = []def init():"""读取词典文件载入词典"""with open("dic/dic.txt","r",encoding="utf8") as dic_input:for word in dic_input:words_dic.append(word.strip())#实现正向匹配算法中的切词方法def cut_words(raw_sentence,words_dic):#统计词典中最长的词max_length = max(len(word) for word in words_dic)sentence = raw_sentence.strip()#统计序列长度words_length = len(sentence)#存储切分好的词语cut_word_list = []while words_length > 0:max_cut_length = min(max_length,words_length)subSentence = sentence[0:max_cut_length]while max_cut_length > 0:if subSentence in words_dic:cut_word_list.append(subSentence)breakelif max_cut_length == 1:cut_word_list.append(subSentence)breakelse:max_cut_length = max_cut_length - 1subSentence = subSentence[0:max_cut_length]sentence = sentence[max_cut_length:]words_length = words_length - max_cut_lengthword = "/".join(cut_word_list)return cut_word_listdef main():"""用于用户交互接口"""init()while True:input_str = '我在学习自然语言处理'result = cut_words(input_str,words_dic)print("分词结果")print(result)if __name__ == "__main__":main()
输出结果如下:
我/在/学习/自然语言处理
2)、逆向最大匹配算法(RMM):基本原理与正向最大匹配算法类似,只是分词顺序变为从右至左。
RMM.py
#使用逆向最大匹配算法实现中文分词RMMwords_dic = []def init():"""读取词典文件载入词典"""with open("dic/dic.txt","r",encoding="utf8") as dic_input:for word in dic_input:words_dic.append(word.strip())#实现逆向匹配算法中的切词方法def cut_words(raw_sentence,words_dic):#统计词典中词的最长长度max_length = max(len(word) for word in words_dic)sentence = raw_sentence.strip()#统计序列长度words_length = len(sentence)#存储切分好的词语cut_word_list = []#判断是否需要继续切词while words_length > 0:max_cut_length = min(max_length,words_length)subSentence = sentence[-max_cut_length:]while max_cut_length > 0:if subSentence in words_dic:cut_word_list.append(subSentence)breakelif max_cut_length == 1:cut_word_list.append(subSentence)breakelse:max_cut_length = max_cut_length - 1subSentence = subSentence[-max_cut_length:]sentence = sentence[0:-max_cut_length:]words_length = words_length - max_cut_lengthcut_word_list.reverse()word = "/".join(cut_word_list)return cut_word_listdef main():"""用于用户交互接口"""init()while True:input_str = '我在学习自然语言处理'result = cut_words(input_str,words_dic)print("分词结果")print(result)if __name__ == "__main__":main()
输出结果如下:
3)、 双向最大匹配算法(Bi-MM):即正向与反向相结合,实现双向最大匹配。对分词结果进一步处理,比较两个结果。筛选出两者中更确切的分词结果。
import RMMimport FMM#使用双向最大匹配算法实现中文分词words_dic = []def init():"""读取词典文件载入词典"""with open("dic/dic.txt","r",encoding="utf8") as dic_input:for word in dic_input:words_dic.append(word.strip())#实现双向匹配算法中的切词方法def cut_words(raw_sentence,words_dic):bmm_word_list = BMM.cut_words(raw_sentence,words_dic)fmm_word_list = FMM.cut_words(raw_sentence,words_dic)bmm_word_list_size = len(bmm_word_list)fmm_word_list_size = len(fmm_word_list)if bmm_word_list_size != fmm_word_list_size:if bmm_word_list_size < fmm_word_list_size:return bmm_word_listelse:return fmm_word_listelse:FSingle = 0BSingle = 0isSame = Truefor i in range(len(fmm_word_list)):if fmm_word_list[i] not in bmm_word_list:isSame = Falseif len(fmm_word_list[i]) == 1:FSingle = FSingle + 1if len(bmm_word_list[i]) == 1:BSingle = BSingle + 1if isSame:return fmm_word_listelif BSingle > FSinglereturn fmm_word_listelse:return bmm_word_listdef main():"""用于用户交互接口"""init()while True:print("请输入要分词的序列")input_str = input()if not input_str:breakresult = cut_words(input_str,words_dic)print("分词结果")print(result)if __name__ == "__main__":main()
基于统计模型的分词算法
1)、基于N-gram语言模型的分词算法
如何判断一个句子是否合理,很容易想到一种很好的统计模型来解决上述问题,只需要看它在所有句子中出现的概率就行了。
第一个句子出现的概率大概是80%,第二个句子出现的概率大概是50%,第三个句子出现的概率大概是20%,第一个句子出现的可能性最大,因此这个句子最合理。
假设下一个词的出现依赖它前面的一个词或依赖它前面的两个词。
假设想知道S在文本中出现的可能性,也就是数学上所说的S的概率,既然
计算
假设一个词
现在,S的概率就变得简单了
那么,接下来的问题就变成了估计条件概率
当样本量很大的时候,基于大数定律,一个短语或者词语出现的概率可以用其频率来表示是,即
其中,count(i)表示单词i出现的次数,count表示语料库的大小。
那么
N-gram语言模型的分词算法是利用信息找出一条概率最大的路径
假设随机变量S为一个汉字序列,W是S上所有可能的切分路径。对于分词,实际上就是求解使条件概率
W^* = argmax P(w|s)
根据贝叶斯公式:
W^* = argmax P(w)P(S|W)/P(S)
由于P(S)为归一化因子,P(S|W)恒为1,因此只需求解P(W)
基于序列标注的分词算法
1)、基于HMM的分词方法
首先我们转换下思维,把分词问题做个转换:分词问题就是句子中的每个字打标注,标注要么是一个词的开始(B),要么是一个词的中间位置(M),要么是一个词的结束位置(E),还有单个字的词,用S表示。
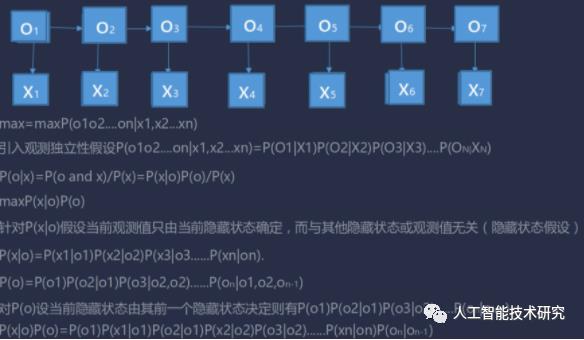
下面对中文分词进行形式化描述:
设观察集合O={
问题:已知输入的观察序列为:X =
求对应的状态序列:Y =
基于HMM的分词方法:属于由字构词的分词方法,由字构词的分词方法思想,就是将分词问题转化为字的分类问题(序列标注问题)。
从某些层面讲,由字构词的方法并不依赖于事先编制好的词表,但仍然需要分好词的训练语料。
规定每个字有4个词位:词首B、词中M、词尾E、单字成词S

由于HMM是一个生成式模型,X为观测序列,Y为隐序列
基本思路
每个字在构造一个特定的词语时都占据着一个确定的构词位置(即词位),规定每个字最多只有四个构词位置:即B(词首)、M(词中)、E(词尾)、S(单独成词)。
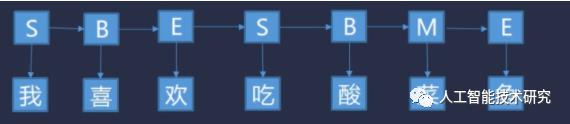
把带求解的标志用O1,O2,...,O7表示,把输入用X表示。然后观察线带来的关系。
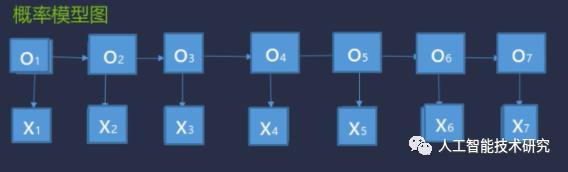
O1取B,取M,取E,取S的概率是多大.
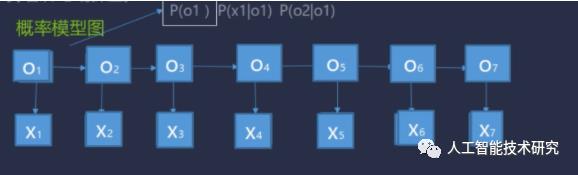
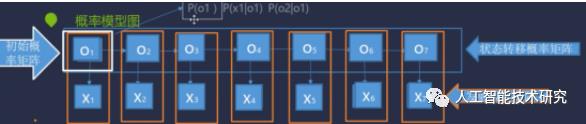
Viterbi算法讲解
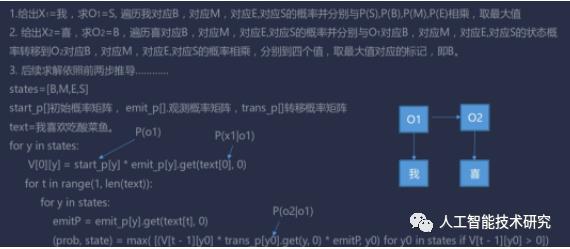
1).当前观测值只由当前隐藏状态确定,而与其他隐藏状态或观测值无关(隐藏状态假设)
2).当前隐藏状态由其前一个隐藏状态决定(一阶马尔科夫假设)
3).隐藏状态之间的转换函数概率不随时间变化(转换函数稳定性假设)
三大概率矩阵
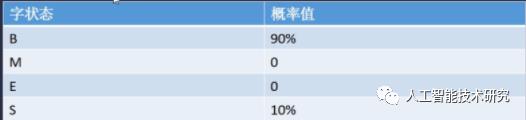
start_p[]初始概率矩阵
设语料库中有1000条句子,以B开始即以词语开始的句子有900条,以S开始的句子有100条
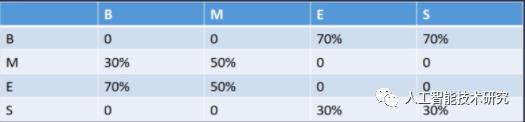
trans_p[] 转移概率矩阵
设语料库中有M标记字一共有100个,以B开始转移到M有30个,转移到E有70个
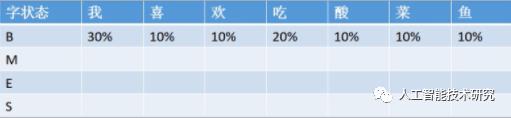
emit_p[] 观测概率矩阵
语料库中有B标记字一共有100个,以B为条件得到'我'字有30个...
HMM公式推导
2)、基于CRF的分词方法
CRF分词原理
CRF把分词当做字的词位分类问题,通常定义字的词位信息如下:
词首,常用B表示
词中,常用M表示
词尾,常用E表示
单字词,常用S表示
CRF分词的过程就是对词位标注后,将B和E之间的字,以及S单字构成分词
CRF分词实例:
原始例句:我爱北京天安门
CRF标注后:我/S 爱/S 北/B 京/E 天/B 安/M 门/E
分词结果:我/爱/北京/天安门
CRF是一种判别式模型,CRF通过定义条件概率P(Y|X)来描述模型。基于CRF的分词方法,与传统的分类模型求解很相似,即给定feature(字级别的各种信息)输出label(词位)
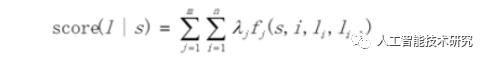
简单来说,分词所使用的是Linear-CRF,它由一组特征函数组成,包括权重和特征函数f,特征函数f的输入是整个句子s、当前posi、前一个词位Ii-1,当前词位Ii
3)、基于深度学习的端到端的分词方法
最近,基于深度神经网络的序列标注算法在词性标注、命名实体识别问题上取得了优秀的进展。词性标注、命名实体识别都属于序列标注问题,这些端到端的方法可以迁移到分词问题上,免去CRF的特征模板配置问题。但与所有深度学习的方法一样,它需要较大的训练语料才能体现优势。
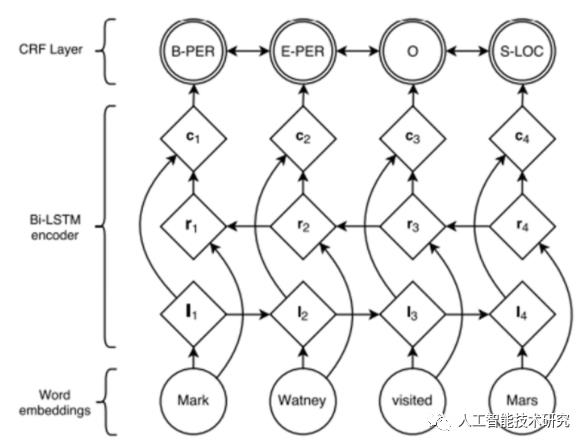
BiLSTM-CRF的网络结构如上图所示,输入层是一个embedding层,经过双向LSTM网络编码,输出层是一个CRF层。下图是BiLSTM-CRF各层的物理含义,可以看见经过双向LSTM网络输出的实际上是当前位置对于各词性的得分,CRF层的意义是对词性得分加上前一位置的词性概率转移的约束,其好处是引入一些语法规则的先验信息。
从数学公式的角度:
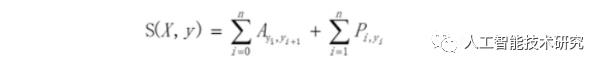
其中,A是词性的转移矩阵,P是BiLSTM网络的判别得分
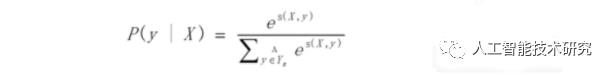
主要的分词工具
准确率中文分词评价指标
准确率
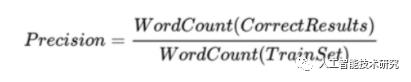
召回率
F值
结语
中文分词呈现两个发展趋势:
1、越来越多的Attention方法应用到中文分词上。
2、神经网络深入到NLP各个领域之中
3、数据科学与语言科学融合,发挥彼此优势。
以上是关于自然语言处理(NLP)的基础难点:分词算法的主要内容,如果未能解决你的问题,请参考以下文章