Shallow copy and Deep copy
Posted 繁华遗世
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Shallow copy and Deep copy相关的知识,希望对你有一定的参考价值。
Shallow copy and Deep copy
第一部分:
一、来自wikipidia的解释:
Shallow copy
One method of copying an object is the shallow copy. In that case a new object B is created, and the fields values of A are copied over to B. This is also known as a field-by-field copy,field-for-field copy, or field copy. If the field value is a reference to an object (e.g., a memory address) it copies the reference, hence referring to the same object as A does, and if the field value is a primitive type it copies the value of the primitive type. In languages without primitive types (where everything is an object), all fields of the copy B are references to the same objects as the fields of original A. The referenced objects are thus shared, so if one of these objects is modified (from A or B), the change is visible in the other. Shallow copies are simple and typically cheap, as they can be usually implemented by simply copying the bits exactly.
复制对象的一种方法是浅拷贝。 在这种情况下,将创建一个新对象B,并将A的字段值复制到B.这也称为逐字段复制,或字段复制。 如果字段值是对对象(例如,存储器地址)的引用,则它复制引用,因此引用与A相同的对象,并且如果字段值是原始类型,则它复制原始类型的值。 在没有原始类型的语言(其中一切都是对象)中,副本B的所有字段都引用与原始A的字段相同的对象。因此,共享引用的对象,因此如果这些对象中的一个被修改(从A 或B),变化在另一个中可见。 浅拷贝很简单,通常很便宜,因为它们通常可以通过简单地复制这些位来实现。
Deep copy
An alternative is a deep copy, meaning that fields are dereferenced: rather than references to objects being copied, new copy objects are created for any referenced objects, and references to these placed in B. The result is different from the result a shallow copy gives in that the objects referenced by the copy B are distinct from those referenced by A, and independent. Deep copies are more expensive, due to needing to create additional objects, and can be substantially more complicated, due to references possibly forming a complicated graph.
另一种方法是深拷贝,意思是字段被解引用:而不是对被拷贝的对象的引用,为任何引用的对象创建新的拷贝对象,并且将这些对象的引用放置在B.结果不同于浅拷贝给出的结果 因为副本B引用的对象与A引用的对象不同,并且是独立的。 由于需要创建附加对象,深拷贝更加昂贵,并且由于可能形成复杂图形的引用,可能显着更复杂。


A deep copy in progress. A deep copy having been completed.
In Python, the library\'s copy module provides shallow copy and deep copy of objects through the copy() and deepcopy() functions, respectively.Programmers may define special methods __copy__() and __deepcopy__() in an object to provide custom copying implementation.
二、来自Python的List实例
在Python中,引用是指从变量到对象的连接,即保存的值为对象的地址,它是一种关系,以内存中的指针形式实现。
在Python中,一个变量保存的值除了基本类型保存的是值外,其它都是引用。
变量:是一个系统表的元素,拥有指向对象连接的空间。
对象:是被分配的一块内存,有足够的空间去表现它们所代表的值。
引用:自动形成的从变量到对象的指针。
共享引用:
>>> L1 = [1, 2, 3] >>> L2 = L1 >>> L1.append(4)
>>> L2 >>> [1, 2, 3, 4]
L1与L2指向内存中的同一对象,对其中一个对象的修改都会影响另一个对象的值,即L1与L2共享引用对象。
解决方法:
>>> L1 = [1, 2, 3]
>>> L2 = L1.copy() #list.copy()-->Return a shallow copy of the list. Equivalent toa[:].
>>> L1.append(4)
>>> L1
>>> [1, 2, 3, 4]
>>> L2
>>> [1, 2, 3]
以上例子只适用于简单列表,也就是列表中的元素都是基本类型,如果列表元素还存在列表的话,这种方法就不再适用了。原因就是,像a.copy()这种处理方法,只是将列表元素的值生成一个新的列表,如果列表元素是一个子列表,例如:a=[1,2,3,4,[\'a\',\'b\']],那么这种复制对于元素[\'a\',\'b\']的处理只是复制[\'a\',\'b\']的引用,而并未生成 [\'a\',\'b\']的一个新的列表复制。代码如下:
>>> a = [1, 2, 3, 4, [\'a\', \'b\']] >>> b = a.copy() >>> a[4].append(\'c\') >>> b >>> [1, 2, 3, 4, [\'a\', \'b\', \'c\']]
解决方法:copy模块,请参考第三节。
三、来自Python的模块copy
copy — Shallow and deep copy operations
Assignment statements in Python do not copy objects, they create bindings between a target and an object. For collections that are mutable or contain mutable items, a copy is sometimes needed so one can change one copy without changing the other. This module provides generic shallow and deep copy operations (explained below).
Interface summary:
copy.copy(x) -->Return a shallow copy of x.- Shallow copy operation on arbitrary Python objects.
See the module\'s __doc__ string for more info.
copy.deepcopy(x) -->Return a deep copy of x.
deepcopy(x, memo=None, _nil=[])
Deep copy operation on arbitrary Python objects.
See the module\'s __doc__ string for more info.
- exception
copy.error -->Raised for module specific errors.
The difference between shallow and deep copying is only relevant for compound objects (objects that contain other objects, like lists or class instances):
- A shallow copy constructs a new compound object and then (to the extent possible) inserts references into it to the objects found in the original.
- A deep copy constructs a new compound object and then, recursively, inserts copies into it of the objects found in the original.
Two problems often exist with deep copy operations that don’t exist with shallow copy operations:
- Recursive objects (compound objects that, directly or indirectly, contain a reference to themselves) may cause a recursive loop.
- Because deep copy copies everything it may copy too much, e.g., administrative data structures that should be shared even between copies.
The deepcopy() function avoids these problems by:
- keeping a “memo” dictionary of objects already copied during the current copying pass; and
- letting user-defined classes override the copying operation or the set of components copied.
This module does not copy types like module, method, stack trace, stack frame, file, socket, window, array, or any similar types. It does “copy” functions and classes (shallow and deeply), by returning the original object unchanged; this is compatible with the way these are treated by the pickle module.
Shallow copies of dictionaries can be made using dict.copy(), and of lists by assigning a slice of the entire list, for example, copied_list = original_list[:].
Classes can use the same interfaces to control copying that they use to control pickling. See the description of module pickle for information on these methods. In fact, the copy module uses the registered pickle functions from the copyreg module.
In order for a class to define its own copy implementation, it can define special methods __copy__() and __deepcopy__(). The former is called to implement the shallow copy operation; no additional arguments are passed. The latter is called to implement the deep copy operation; it is passed one argument, the memo dictionary. If the __deepcopy__() implementation needs to make a deep copy of a component, it should call the deepcopy() function with the component as first argument and the memo dictionary as second argument.
See also
- Module
pickle - Discussion of the special methods used to support object state retrieval and restoration.
实例:
>>> import copy >>> a = [1, 2, 3, 4, [\'a\', \'b\']] >>> b = a >>> c = copy.copy(a) >>> d = copy.deepcopy(a)
>>> a.append(5) >>> a[4].append(\'c\')
>>> a
>>> [1, 2, 3, 4, [\'a\', \'b\', \'c\'], 5] >>> b >>> [1, 2, 3, 4, [\'a\', \'b\', \'c\'], 5] >>> c >>> [1, 2, 3, 4, [\'a\', \'b\', \'c\']] >>> d >>> [1, 2, 3, 4, [\'a\', \'b\']]
第二部分:
在写第二部分之前,先来熟悉Pyhton的一个内置函数:id()
id(object):Return the “identity” of an object. This is an integer which is guaranteed to be unique and constant for this object during its lifetime. Two objects with non-overlapping lifetimes may have the same id() value.
返回对象的“标识”。这是一个整数,它保证在该对象的生命周期内是唯一的和不变的。具有不重叠生命周期的两个对象可以具有相同的id()值。
从id()函数的功能来看,它是区分两个不同对象最直接也是最根本的函数。接下来,我将使用此函数对第一部分内容进行验证。
示例1:
在解释器输入对象2,使用id(2)获取对象的标识,然后输入变量a,接着输入a=2,最后输入id(2)。
如下图所示:
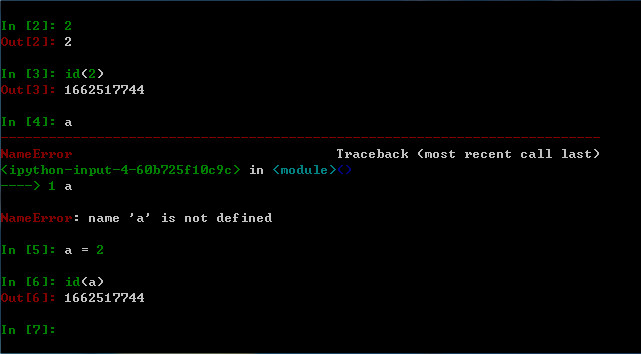
在上图中,输入对象2返回2,输入变量a后抛出NameErrorr异常,将a=2进行赋值后,a的标识与对象2的标识相同。可以看出,变量a只是对对象2的一个引用,离开对象后,变量没有什么实际意义。
从此例子中,可以这样理解:对象2相当于一个实实在在的盒子,变量a相当于一个标签,它只是为了方便找到这个指定的盒子而给他取得一个特定的名字,仅此而已。引用《python 学习手册 第三版》的话:变量永远不会有任何和它关联的类型信息或约束。类型的概念是存在于对象中而不是变量名中。变量原本是通用的,它只是在一个特定的时间点,简单地引用了一个特定的对象而已。
示例2:
a = 2; a = \'apple\'
如下图所示:

变量a最初指向了对象2,后面又指向了字符串对象apple,从对象的标识看出,对象2不见了,哪地方去了呢?如果对象2未被其他变量名或对象所引用的话,这个对象就会被pyhton自动回收了。在python中,类型是属于对象的,在每个对象中,都包含了一个头部信息,它告诉python自己是哪种类型,例如对象2就代表int类型。在内部,python是通过保持用每个对象中的计数器记录引用指向这个对象上的次数来完成回收功能的。一旦这个计数器被设置为0,这个对象的内存空间就会自动回收。在上述例子,a被赋予为一个新对象,前一个对象的引用计数器变为0,导致对象2自动被销毁了。
示例3:
a=64; b=64
a=88888888; b=88888888
a=\'apple\'; b=\'apple\'
a=\'a\' *100; b=\'a\' * 100
a = [1, 2, 3]; b = [1, 2, 3]
a = (1, 2, 3); b = (1, 2, 3)
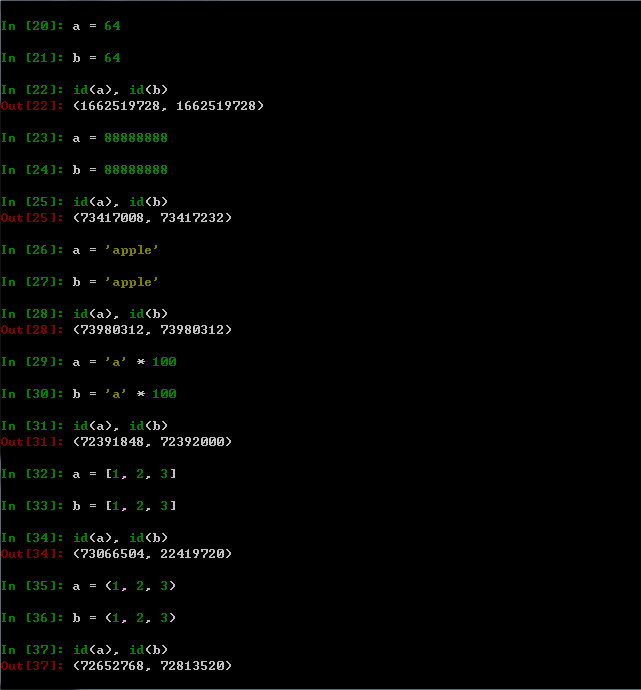
如上图所示,当变量a,b引用小的整数和字符串(基本类型)时,a,b指向的是同一对象,但是当a,b的值变得很大或者不是基本类型时,a,b所指向的对象不是同一对象,发生这种情况是因为python将小的整数和字符串缓存并复用了。
在python中,有两种方法检查对象是否相等,分别是==操作符和is操作符。
==操作符:测试两个被引用的对象是否有相同的值,这种方法在python中用作相等的检查。
is操作符:检查对象的同一性,如果两个变量名精确地指向同一个对象。它会返回True,否则,返回False。因此,它是一种更严格形式的相等测试。
下面继续使用上面的例子,来判断两个对象是否相等。如下图所示:
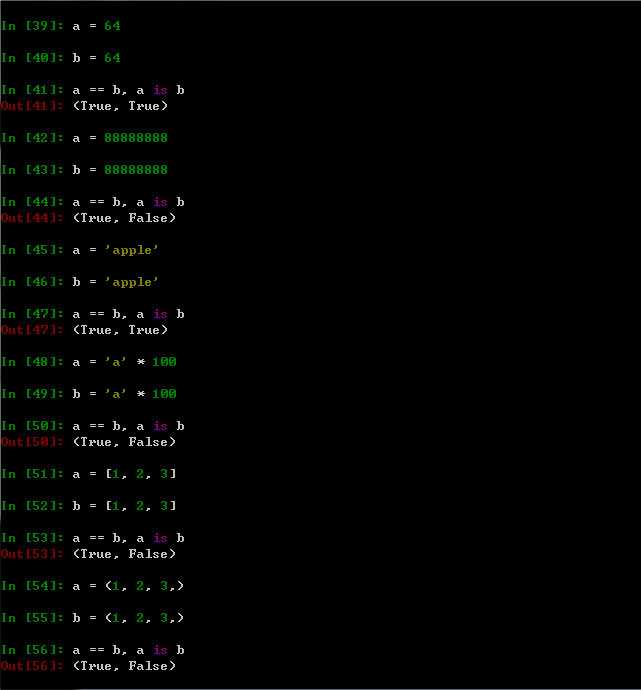
当使用==操作符判断时,都会返回True,当使用严格意义的is操作符判断时,后面一种情况返回为False。因此,在做真值判断时应注意此情况。
示例3:
a=2; b=a; a=a+2
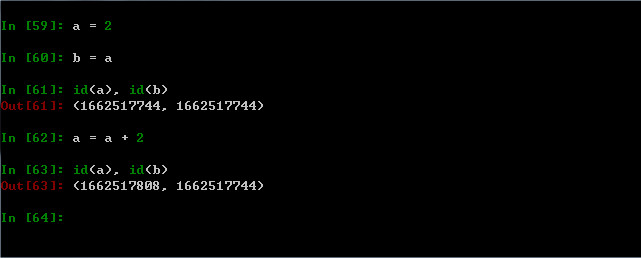
从上图可以看出,当b=a时,变量a,b指向同一对象2,当a=a+2时,a指向了新的对象4,此时b还是指向对象2。
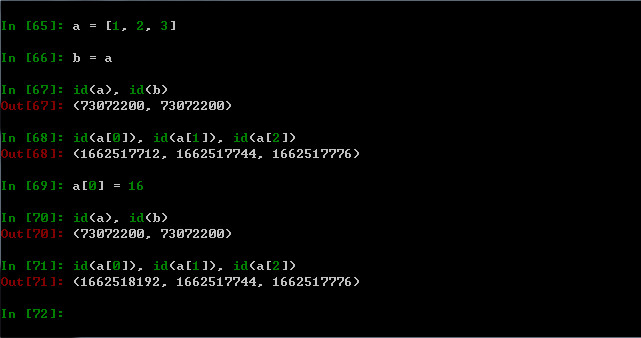
示例4:
a=[1,2,3]; b=a; a[0]=16
如下图所示:
参考文章:
[1] --> https://en.wikipedia.org/wiki/Object_copying#Shallow_copy
[2] --> http://www.jb51.net/article/64030.htm
[3] --> http://www.jb51.net/article/15714.htm
[4] --> https://docs.python.org/3/library/copy.html
[5] --> Learning Python 3rd Edition
以上是关于Shallow copy and Deep copy的主要内容,如果未能解决你的问题,请参考以下文章
Python 深浅拷贝 (Shallow copy and Deep copy in Python)
python中的shallow copy 与 deep copy
Python - 拷贝 - 浅拷贝(Shallow Copy)和深拷贝(Deep Copy)
UVa 10176 - Ocean Deep ! - Make it shallow !!