聊一聊Elasticsearch的健康状态
Posted Thinkgamer_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊一聊Elasticsearch的健康状态相关的知识,希望对你有一定的参考价值。
转载请注明出处:http://blog.csdn.net/gamer_gyt
博主微博:http://weibo.com/234654758
Github:https://github.com/thinkgamer
前言
其实一直以来都没有太关注elsticsearch的健康状态,只是单纯的部署完成,然后es能正常工作就OK了,然而事实却并非如此,elasticsearch得索引状态和集群状态得不同传达着不同得意思,下面我们就来看看
集群状态
Rest API:
root@c2dbf1f9da5d:/# curl 'http://localhost:9200/_cat/health?v'
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1479536615 06:23:35 elasticsearch yellow 1 1 931 931 0 0 930 0 - 50.0%
我当前得elasticsearch时单机版得,由于加载得索引数据比较多索引显示为yellow,正常情况下,集群得健康状态分为三种:
- green
最健康得状态,说明所有的分片包括备份都可用 - yellow
基本的分片可用,但是备份不可用(或者是没有备份) - red
部分的分片可用,表明分片有一部分损坏。此时执行查询部分数据仍然可以查到,遇到这种情况,还是赶快解决比较好
从上边查看的集群状态中还包括一些其他信息:
集群名字时elasticsearch,集群的节点个数为1,分片数量为930,活动分片百分比为 50%
查看各个索引状态
Rest API:
root@c2dbf1f9da5d:/# curl -k -u admin:admin 'https://localhost:9200/_cat/indices' | grep raoxing-*
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 11033 100 11033 0 0 43611 0 --:--:-- --:--:-- --:--:-- 43608
yellow open raoxing-2016.01.03 5 1 1 0 7.1kb 7.1kb
yellow open raoxing-2016.01.02 5 1 1 0 7kb 7kb
yellow open raoxing-2015.11.09 5 1 4 0 20.4kb 20.4kb
yellow open raoxing-2015.11.05 5 1 1 0 7kb 7kb
yellow open raoxing-2015.11.03 5 1 1 0 7kb 7kb
我这里过滤了raoxing-*的索引数据,可以看到raoxing-* 的健康状态全部为yellow,所以我的集群(单机版称为空集群)的健康状态也为yellow
索引的健康状态也有三种,yellow、green、red与集群的健康状态解释是一样的
状态为yellow的解决办法
分片与副本分片
分片用于Elasticsearch在你的集群中分配数据。想象把分片当作数据的容器。文档存储在分片中,然后分片分配给你集群中的节点上。
当你的集群扩容或缩小,Elasticsearch将会自动在你的节点间迁移分片,以使集群保持平衡。
一个分片(shard)是一个最小级别的“工作单元(worker unit)”,它只是保存索引中所有数据的一小片.我们的文档存储和被索引在分片中,但是我们的程序不知道如何直接与它们通信。取而代之的是,他们直接与索引通信.Elasticsearch中的分片分为主分片和副本分片,复制分片只是主分片的一个副本,它用于提供数据的冗余副本,在硬件故障之后提供数据保护,同时服务于像搜索和检索等只读请求,主分片的数量和复制分片的数量都可以通过配置文件配置。但是主切片的数量只能在创建索引时定义且不能修改.相同的分片不会放在同一个节点上。
###分片算法
shard = hash(routing) % number_of_primary_shards
routing值是一个任意字符串,它默认是_id但也可以自定义,这个routing字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是0到number_of_primary_shards - 1,这个数字就是特定文档所在的分片。
这也解释了为什么主切片的数量只能在创建索引时定义且不能修改:如果主切片的数量在未来改变了,所有先前的路由值就失效了,文档也就永远找不到了。
所有的文档API(get、index、delete、bulk、update、mget)都接收一个routing参数,它用来自定义文档到分片的映射。自定义路由值可以确保所有相关文档.比如用户的文章,按照用户账号路由,就可以实现属于同一用户的文档被保存在同一分片上。
###分片与副本交互
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上,下面我们罗列在主分片和复制分片上成功新建、索引或删除一个文档必要的顺序步骤:
1、客户端给Node 1发送新建、索引或删除请求。
2、节点使用文档的_id确定文档属于分片0。它转发请求到Node 3,分片0位于这个节点上。
3、Node 3在主分片上执行请求,如果成功,它转发请求到相应的位于Node 1和Node 2的复制节点上。当所有的复制节点报告成功,Node 3报告成功到请求的节点,请求的节点再报告给客户端。
客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片。你的修改生效了
查看分片状态
root@c2dbf1f9da5d:/# curl -X GET 'http://localhost:9200/_cluster/health?pretty'
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 931,
"active_shards" : 931,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 930,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.02686727565825
}
这里解释一下为什么集群状态为yellow
由于我们是单节点部署elasticsearch,而默认的分片副本数目配置为1,而相同的分片不能在一个节点上,所以就存在副本分片指定不明确的问题,所以显示为yellow,我们可以通过在elasticsearch集群上添加一个节点来解决问题,如果你不想这么做,你可以删除那些指定不明确的副本分片(当然这不是一个好办法)但是作为测试和解决办法还是可以尝试的,下面我们试一下删除副本分片的办法
解决办法
root@c2dbf1f9da5d:/# curl -XPUT "http://localhost:9200/_settings" -d' { "number_of_replicas" : 0 } '
{"acknowledged":true}
这个时候再次查看集群的状态状态变成了green
root@c2dbf1f9da5d:/# curl -X GET 'http://localhost:9200/_cluster/health?pretty'
{
"cluster_name" : "elasticsearch",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 931,
"active_shards" : 931,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
elasticsearch集群的一些概念
集群与节点
节点(node)是你运行的Elasticsearch实例。一个集群(cluster)是一组具有相同cluster.name的节点集合,他们协同工作,共享数据并提供故障转移和扩展功能,当有新的节点加入或者删除节点,集群就会感知到并平衡数据。集群中一个节点会被选举为主节点(master),它用来管理集群中的一些变更,例如新建或删除索引、增加或移除节点等;当然一个节点也可以组成一个集群。
节点通信
我们能够与集群中的任何节点通信,包括主节点。任何一个节点互相知道文档存在于哪个节点上,它们可以转发请求到我们需要数据所在的节点上。我们通信的节点负责收集各节点返回的数据,最后一起返回给客户端。这一切都由Elasticsearch透明的管理。
集群生态
1.同集群中节点之间可以扩容缩容,
2.主分片的数量会在其索引创建完成后修正,但是副本分片的数量会随时变化。
3.相同的分片不会放在同一个节点上.
#索引的unssigned问题
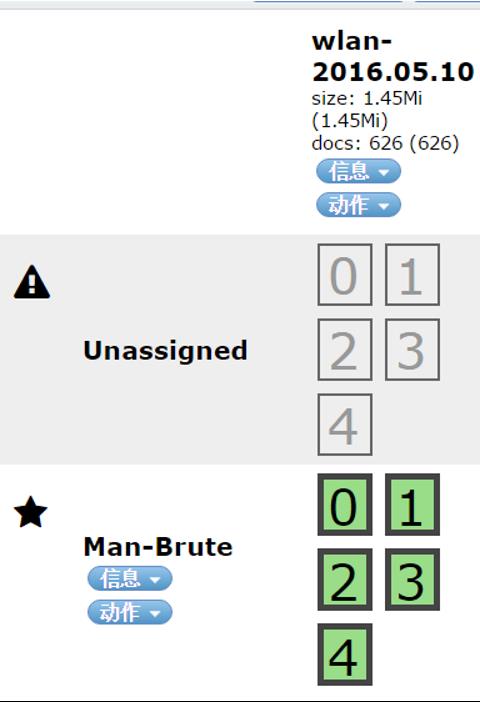
这里的unssigned就是未分配副本分片的问题,在我们执行删除副本分片是这个问题就没了
root@c2dbf1f9da5d:/# curl -XPUT "http://localhost:9200/_settings" -d' { "number_of_replicas" : 0 } '
{"acknowledged":true}

扫一扫 关注微信公众号!号主 专注于搜索和推荐系统,尝试使用算法去更好的服务于用户,包括但不局限于机器学习,深度学习,强化学习,自然语言理解,知识图谱,还不定时分享技术,资料,思考等文章!
以上是关于聊一聊Elasticsearch的健康状态的主要内容,如果未能解决你的问题,请参考以下文章