自然语言17_Chinking with NLTK
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言17_Chinking with NLTK相关的知识,希望对你有一定的参考价值。
https://www.pythonprogramming.net/chinking-nltk-tutorial/?completed=/chunking-nltk-tutorial/
Chinking with NLTK
You may find that, after a lot of chunking, you have some words in your chunk you still do not want, but you have no idea how to get rid of them by chunking. You may find that chinking is your solution.
Chinking is a lot like chunking, it is basically a way for you to remove a chunk from a chunk. The chunk that you remove from your chunk is your chink.
The code is very similar, you just denote the chink, after the chunk, with }{ instead of the chunk‘s {}.
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized[5:]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
chunked.draw()
except Exception as e:
print(str(e))
process_content()
With this, you are given something like:
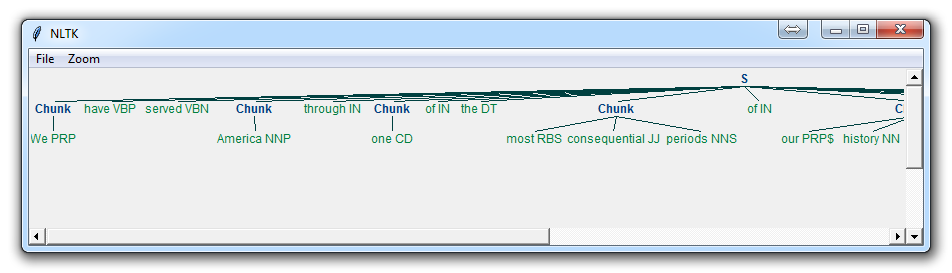
Now, the main difference here is:
}<VB.?|IN|DT|TO>+{
This means we‘re removing from the chink one or more verbs, prepositions, determiners, or the word ‘to‘.
Now that we‘ve learned how to do some custom forms of chunking, and chinking, let‘s discuss a built-in form of chunking that comes with NLTK, and that is named entity recognition.
以上是关于自然语言17_Chinking with NLTK的主要内容,如果未能解决你的问题,请参考以下文章