爬取网贷之家的数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取网贷之家的数据相关的知识,希望对你有一定的参考价值。
代码还是借鉴数据之魂大大的,有兴趣的可以去看看他的博客,不多说直接上代码:


1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 import urllib 4 import urllib.request 5 import re 6 import random 7 #抓取所需内容 8 user_agent = ["Mozilla/5.0 (Windows NT 10.0; WOW64)", ‘Mozilla/5.0 (Windows NT 6.3; WOW64)‘, 9 ‘Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (Khtml, like Gecko) Chrome/23.0.1271.64 Safari/537.11‘, 10 ‘Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko‘, 11 ‘Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36‘, 12 ‘Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; rv:11.0) like Gecko)‘, 13 ‘Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1‘, 14 ‘Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3‘, 15 ‘Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12‘, 16 ‘Opera/9.27 (Windows NT 5.2; U; zh-cn)‘, 17 ‘Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0‘, 18 ‘Opera/8.0 (Macintosh; PPC Mac OS X; U; en)‘, 19 ‘Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.12) Gecko/20080219 Firefox/2.0.0.12 Navigator/9.0.0.6‘, 20 ‘Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)‘, 21 ‘Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)‘, 22 ‘Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E)‘, 23 ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Maxthon/4.0.6.2000 Chrome/26.0.1410.43 Safari/537.1 ‘, 24 ‘Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E; QQBrowser/7.3.9825.400)‘, 25 ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 ‘, 26 ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 Safari/537.1 LBBROWSER‘, 27 ‘Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; BIDUBrowser 2.x)‘, 28 ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/3.0 Safari/536.11‘] 29 url=‘http://shuju.wdzj.com‘ 30 request=urllib.request.Request(url=url,headers={"User-Agent":random.choice(user_agent)})#随机从user_agent列表中抽取一个元素 31 response=urllib.request.urlopen(request) 32 content=response.read().decode(‘utf8‘) #读取网页内容 33 pattern=re.compile(r‘\\/\\w{4}\\-\\w{4}\\-\\d*\\.\\w{4}\\S{2}[\\u4e00-\\u9fa5]{2,6}|\\/\\w{4}\\-\\w{4}\\-\\d*\\.\\w{4}\\S{2}\\S{2,7}|<div>\\d*.\\d*</div>‘) 34 match = re.findall(pattern,content) 35 a=[] #第一步数据处理存放地址 36 b=[] #第二步数据处理存放地址 37 for i in match: 38 try: 39 (n,m)=i.split(">") 40 a.append(m) 41 except: 42 (n, m,g) = i.split(">", 3) 43 a.append(m) #数据处理第一步 44 for q in a: 45 try: 46 (q1,q2)=q.split("<") 47 b.append(q1) 48 except: 49 b.append(q) #数据处理第二步 50 print(‘平台‘,‘\\t‘,‘成交量‘,‘ ‘,‘\\t‘,‘平均收益率‘,‘\\t‘,‘平均借款期限‘,‘\\t‘,‘待还余额‘) 51 for v in range(0,len(b),5): #原网页有5列数据,所以步长为5 52 print(b[v],‘\\t‘,b[v+1],‘ ‘,‘\\t‘,b[v+2],‘ ‘,‘\\t‘,b[v+3],‘ ‘,‘\\t‘,b[v+4])
正则表达式不是太熟,写的有点烂,不过基本能得出结果,下面附上部分爬取结果:
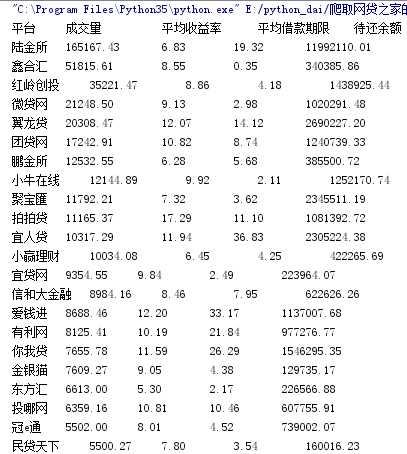
以上是关于爬取网贷之家的数据的主要内容,如果未能解决你的问题,请参考以下文章