NLP︱中文分词技术小结几大分词引擎的介绍与比较
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP︱中文分词技术小结几大分词引擎的介绍与比较相关的知识,希望对你有一定的参考价值。
笔者想说:觉得英文与中文分词有很大的区别,毕竟中文的表达方式跟英语有很大区别,而且语言组合形式丰富,如果把国外的内容强行搬过来用,不一样是最好的。所以这边看到有几家大牛都在中文分词以及NLP上越走越远。哈工大以及北大的张华平教授(NLPIR)的研究成果非常棒!
但是商业应用的过程中存在的以下的问题:
1、是否先利用开源的分词平台进行分词后,再自己写一些算法进行未登录词、歧义词的识别?
2、或者直接调用下文介绍的分词引擎来进行分词呢?缴费使用固然很棒,但是是否值得?
——————————————————————————————————————————
来看一下这篇论文一些中文分词工具的性能比较《开源中文分词器的比较研究_黄翼彪,2013》
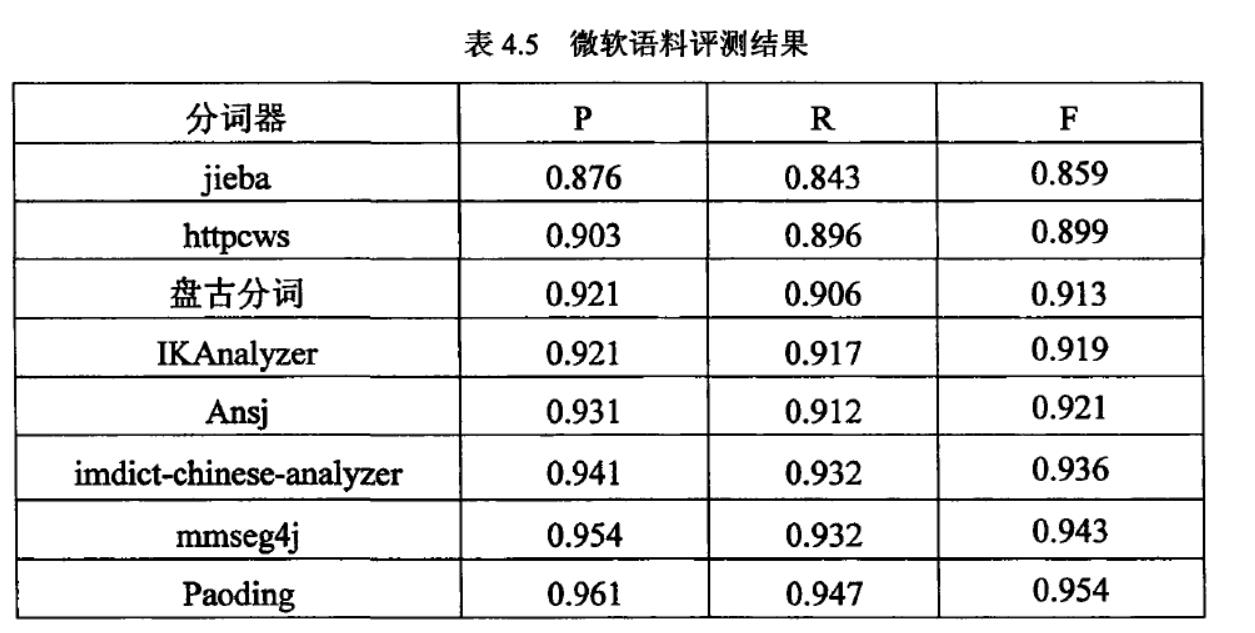
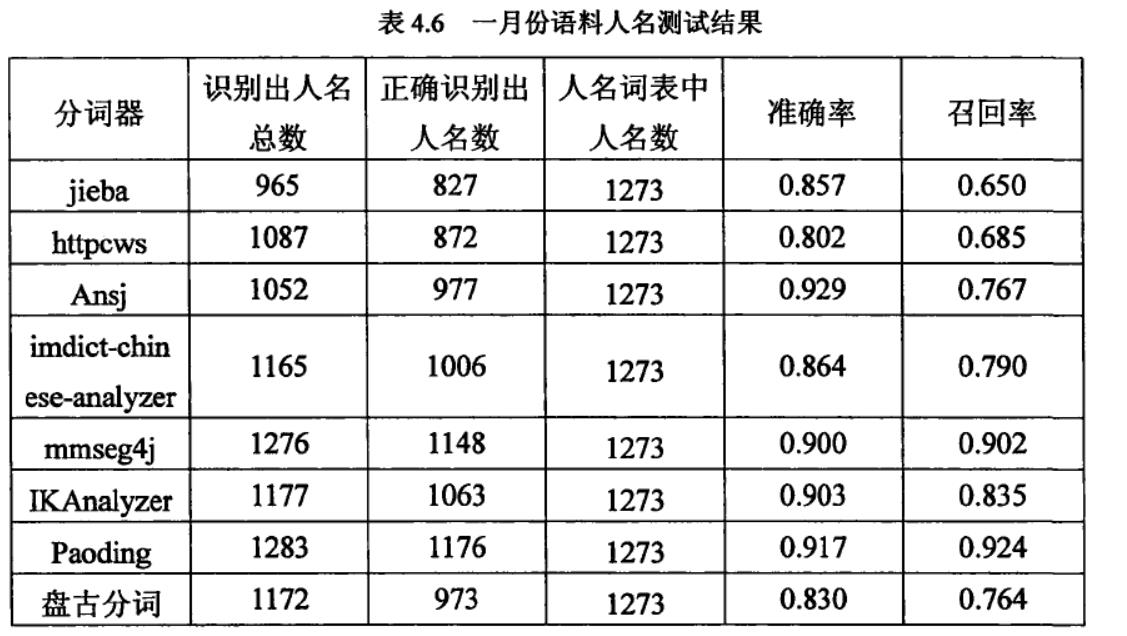
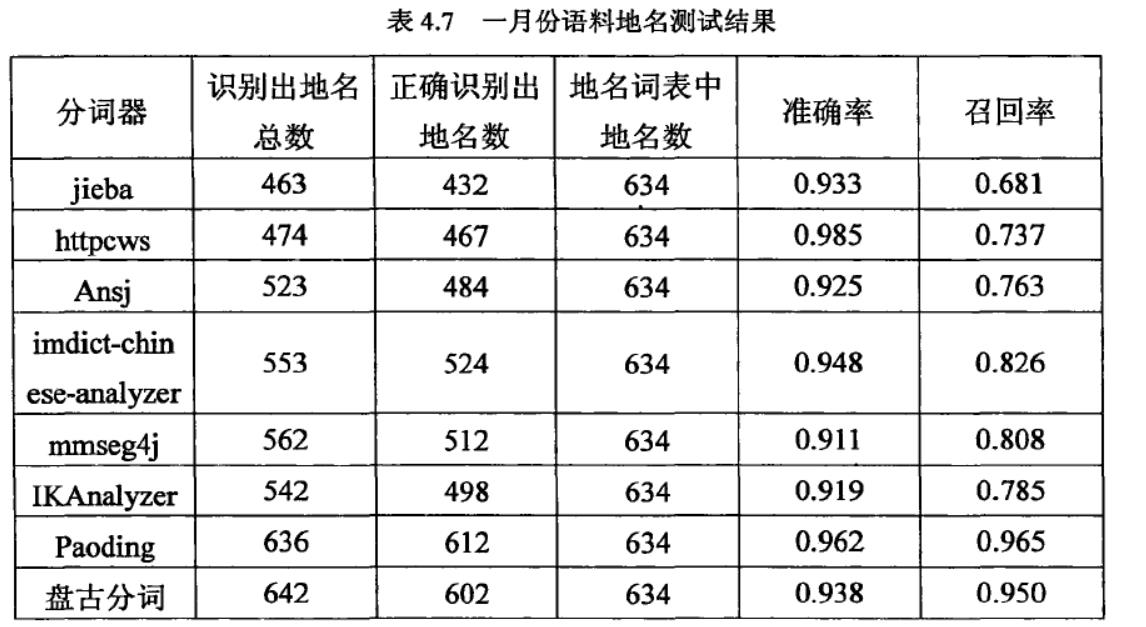
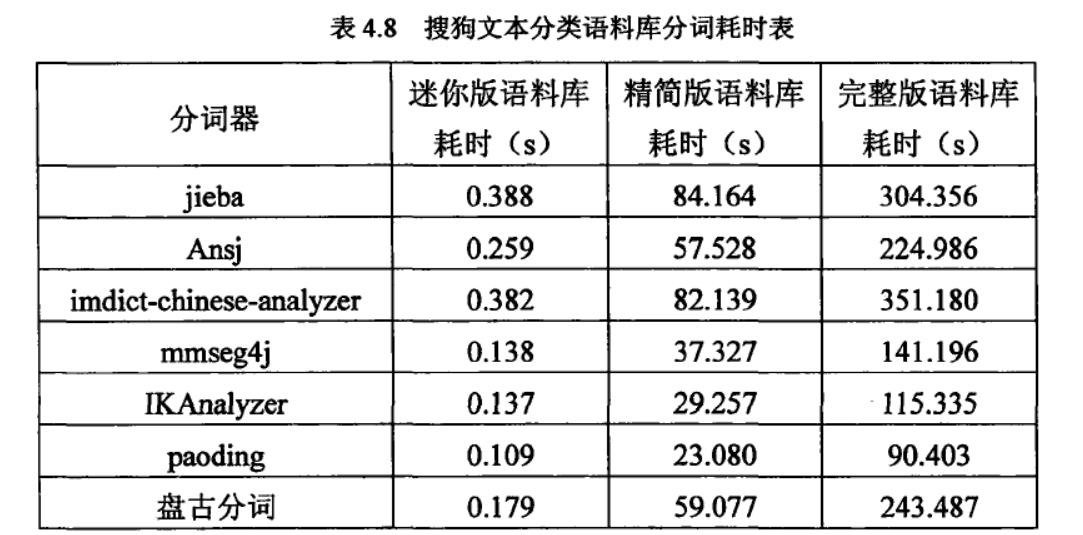
8款中文分词器的综合性能排名:
Paoding(准确率、分词速度、新词识别等,最棒)
mmseg4j(切分速度、准确率较高)
IKAnalyzer
Imdict-chinese-analyzer
Ansj
盘古分词
Httpcws
jieba
——————————————————————————————————————————
一、中文分词技术
1、常见的两类中文分词技术
中文分词技术常见的有两大类:机械分词技术、基于统计的序列标注技术。
机械分词技术操作简单、方便,比较省心,但是对于歧义词以及未登录词的效果并不是很好;
统计模型的序列标注方法,对于识别未登录词拥有较好的识别能力,而且分词精度也比较大,同时这个方法可以不分中文、英语,着重看在语言前后顺序。
以下是思维导图的形式展示两大区别:

2、深度学习在分词、找词中的应用
(1)word2vec词向量
虽然word2vec只有三层神经网络,但是已经取得非常好的效果。通过word2vec,可以将一个词表示为词向量,将文字数字化,更好的让计算机理解。使word2vec模型,我们可以方便的找到同义词或联系紧密的词,或者意义相反的词等。
(2)RNN(Recurrent Neural Networks,循环神经网络)——seq2seq
在自然语言处理中,上下文关系非常重要,一个句子中前后词并不独立,不同的组合会有不同的意义,比如”优秀”这个词,如果前面是”不”字,则意义完全相反。RNN则考虑到网络前一时刻的输出对当前输出的影响,将隐藏层内部的节点也连接起来,即当前时刻一个节点的输入除了上一层的输出外,还包括上一时刻隐藏层的输出。RNN在理论上可以储存任意长度的转态序列,但是在不同的场景中这个长度可能不同。比如在词的预测例子中:
1,“他是亿万富翁,他很?”;
2,“他的房子每平米物业费40元,并且像这样的房子他有十几套,他很?”。
从这两个句子中我们已经能猜到?代表“有钱”或其他类似的词汇,但是明显,第一句话预测最后一个词时的上线文序列很短,而第二段话较长。如果预测一个词汇需要较长的上下文,随着这个距离的增长,RNN将很难学到这些长距离的信息依赖,虽然这对我们人类相对容易。在实践中,已被证明使用最广泛的模型是LSTM(Long Short-Term Memory,长短时记忆)很好的解决了这个问题。
LSTM最早由Hochreiter及 Schmidhuber在1997年的论文中提出。首先LSTM也是一种RNN,不同的是LSTM能够学会远距离的上下文依赖,能够存储较远距离上下文对当前时间节点的影响。
所有的RNN都有一串重复的神经网络模块。对于标准的RNN,这个模块都比较简单,比如使用单独的tanh层。LSTM拥有类似的结构,但是不同的是,LSTM的每个模块拥有更复杂的神经网络结构:4层相互影响的神经网络。在LSTM每个单元中,因为门结构的存在,对于每个单元的转态,使得LSTM拥有增加或减少信息的能力。
(来源文章:基于Deep Learning的中文分词尝试)(3)深度学习库
Keras(http://keras.io)是一个非常易用的深度学习框架,使用python语言编写,是一个高度模块化的神经网络库,后端同时支持Theano和TensorFlow,而Theano和TensorFlow支持GPU,因此使用keras可以使用GPU加速模型训练。
Keras中包括了构建模型常用的模块,如Optimizers优化方法模块,Activations激活函数模块,Initializations初始化模块,Layers多种网络层模块等,可以非常方便快速的搭建一个网络模型,使得开发人员可以快速上手,并将精力放在模型设计而不是具体实现上。常见的神经网络模型如CNN,RNN等,使用keras都可以很快搭建出来,开发人员只需要将数据准备成keras需要的格式丢进网络训练即可。如果对keras中自带的layer有更多的需求,keras还可以自己定制所需的layer。
——————————————————————————————————————————
二、常见的中文分词引擎的介绍
1、11款中文分词引擎大比拼
测试了11家中文分词引擎(各家分词系统链接地址),同时从分词准确度、歧义词切分、未登陆词(新涌现的通用词、专业术语、专有名词)三个方面进行论证。
BosonNLP:http://bosonnlp.com/dev/center
IKAnalyzer:http://www.oschina.net/p/ikanalyzer
NLPIR:http://ictclas.nlpir.org/docs
SCWS中文分词:http://www.xunsearch.com/scws/docs.php
结巴分词:https://github.com/fxsjy/jieba
盘古分词:http://pangusegment.codeplex.com/
庖丁解牛:https://code.google.com/p/paoding/
搜狗分词:http://www.sogou.com/labs/webservice/
腾讯文智:http://www.qcloud.com/wiki/API%E8%AF%B4%E6%98%8E%E6%96%87%E6%A1%A3
新浪云:http://www.sinacloud.com/doc/sae/python/segment.html
语言云:http://www.ltp-cloud.com/document
最终的结果显示:
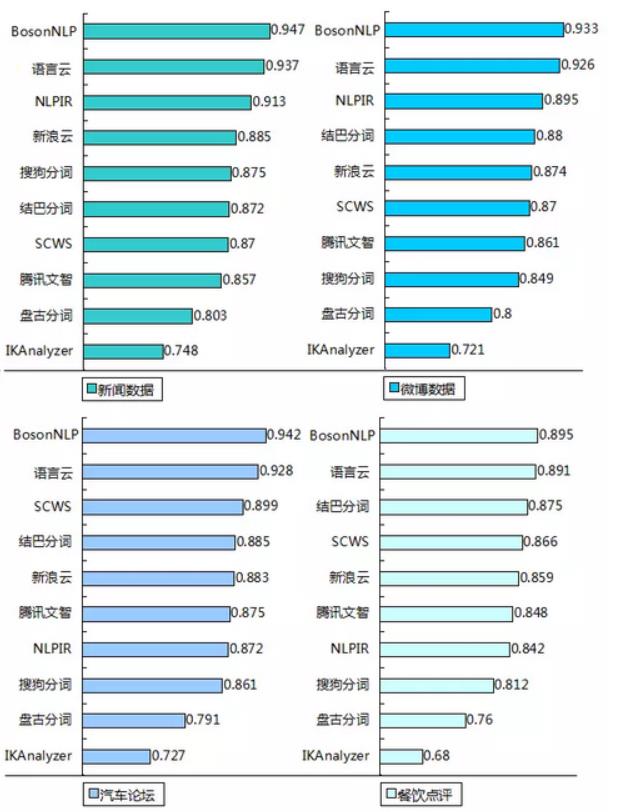
从分词精度来看,哈工大的语言云表现的稳定一直在第二,BostonNLP分词更好,一直在这个领域保持第一。

评测数据地址:http://bosonnlp.com/dev/resource(来源bostonNLP微信公众号)
2、哈工大语言云
语言技术平台(LTP) 提供包括中文分词、词性标注、命名实体识别、依存句法分析、语义角色标注等丰富、 高效、精准的自然语言处理技术。经过 哈工大社会计算与信息检索研究中心 11 年的持续研发和推广,LTP 已经成为国内外最具影响力的中文处理基础平台。
切分歧义是分词任务中的主要难题。 LTP的分词模块基于机器学习框架,可以很好地解决歧义问题。 同时,模型中融入了词典策略,使得LTP的分词模块可以很便捷地加入新词信息。
3、张华平NLPIR
对原始语料进行分词、自动识别人名地名机构名等未登录词、新词标注以及词性标注。并可在分析过程中,导入用户定义的词典。
NLPIR/ICTCLAS分词系统,采用层叠隐马模型(算法细节请参照:张华平,高凯,黄河燕,赵燕平,《大数据搜索与挖掘》科学出版社。2014.5 ISBN:978-7-03-040318-6),分词准确率接近98.23%,具备准确率高、速度快、可适应性强等优势。
它能够真正理解中文,利用机器学习解决歧义切分与词性标注歧义问题。张博士先后倾力打造十余年,内核升级10次,全球用户突破30万。(博客中科院分词系统整理笔记)
《大数据搜索与挖掘》张华平:在线看书网址
4、bostonNLP
玻森采用的结构化预测分词模型是传统线性条件随机场(Linear-chain CRF)的一个变种。
分词与词性标注中,新词识别与组合切分歧义是两个核心挑战。玻森在这方面做了不少的优化,包括对特殊字符的处理,对比较有规律的构词方式的特征捕捉等。
例如,近些年比较流行采用半监督的方式,通过使用在大规模无标注数据上的统计数据来改善有监督学习中的标注结果,也在我们的分词实现上有所应用。比如通过使用Accessory Variety作为特征,能够比较有效发现不同领域的新词,提升泛化能力。
怎样确定两个词是否是固定的搭配呢?我们通过计算两个词间的归一化逐点互信息(NPMI)来确定两个词的搭配关系。逐点互信息(PMI),经常用在自然语言处理中,用于衡量两个事件的紧密程度。归一化逐点互信息(NPMI)是逐点互信息的归一化形式,将逐点互信息的值归一化到-1到1之间。如果两个词在一定距离范围内共同出现,则认为这两个词共现。
筛选出NPMI高的两个词作为固定搭配,然后将这组固定搭配作为一个组合特征添加到分词程序中。如“回答”和“问题”是一组固定的搭配,如果在标注“回答”的时候,就会找后面一段距离范围内是否有“问题”,如果存在那么该特征被激活。
可以看出,如果我们提取固定搭配不限制距离,会使后面偶然出现某个词的概率增大,降低该统计的稳定性。在具体实现中,我们限定了成为固定搭配的词对在原文中的距离必须小于一个常数。具体来看,可以采用倒排索引,通过词找到其所在的位置,进而判断其位置是否在可接受的区间。这个简单的实现有个比较大的问题,即在特定构造的文本中,判断两个词是否为固定搭配有可能需要遍历位置数组,每次查询就有O(n)的时间复杂度了,并且可以使用二分查找进一步降低复杂度为O(logn)。
其实这个词对检索问题有一个更高效的算法实现。我们采用滑动窗口的方法进行统计:在枚举词的同时维护一张词表,保存在当前位置前后一段距离中出现的可能成词的字符序列;当枚举词的位置向后移动时,窗口也随之移动。
这样在遍历到“回答”的时候,就可以通过查表确定后面是否有“问题”了,同样在遇到后面的“问题”也可以通过查表确定前面是否有“回答”。当枚举下一个词的时候,词表也相应地进行调整。采用哈希表的方式查询词表,这样计算一个固定搭配型时间复杂度就可以是O(1)了。
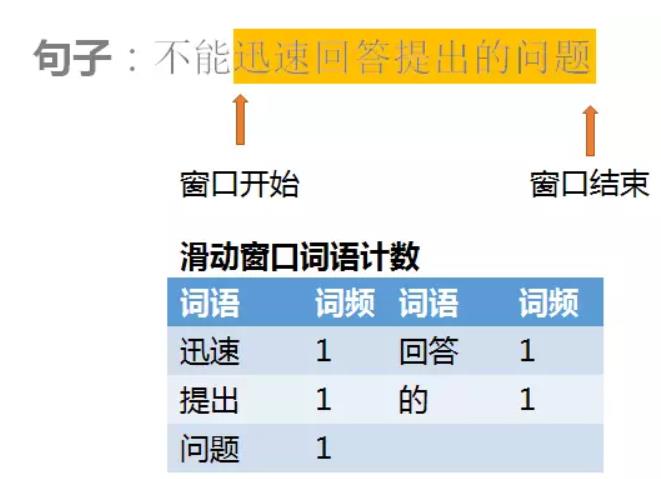
通过引入上述的上下文的信息,分词与词性标注的准确率有近1%的提升,而对算法的时间复杂度没有改变。我们也在不断迭代升级以保证引擎能够越来越准确,改善其通用性和易用性。
——bostanNLP公众号推文5、NLTK——斯坦福中文分词器
斯坦福大学自然语言处理组是世界知名的NLP研究小组,他们提供了一系列开源的Java文本分析工具,包括分词器(Word Segmenter),词性标注工具(Part-Of-Speech Tagger),命名实体识别工具(Named Entity Recognizer),句法分析器(Parser)等,可喜的事,他们还为这些工具训练了相应的中文模型,支持中文文本处理。
在使用NLTK的过程中,发现当前版本的NLTK已经提供了相应的斯坦福文本处理工具接口,包括词性标注,命名实体识别和句法分析器的接口,不过可惜的是,没有提供分词器的接口。在google无果和阅读了相应的代码后,我决定照猫画虎为NLTK写一个斯坦福中文分词器接口,这样可以方便的在Python中调用斯坦福文本处理工具,详情可见该公众号分享文。
(来源公众号分享)
——————————————————————————————————————————
三、中文分词工具测评
来自于paperweekly的张俊,文章《专栏 | 中文分词工具测评》
本文选择了4个常见的分词工具,分别是:哈工大LTP、中科院计算所NLPIR、清华大学THULAC和jieba,为了对比分词速度,选择了这四个工具的c++版本进行评测。
1、LTP https://github.com/HIT-SCIR/ltp
2、NLPIR https://github.com/NLPIR-team/NLPIR
3、THULAC https://github.com/thunlp/THULAC
4、jieba https://github.com/yanyiwu/cppjieba
测试数据集
1、SIGHAN Bakeoff 2005 MSR, 560KB http://sighan.cs.uchicago.edu/bakeoff2005/
2、SIGHAN Bakeoff 2005 PKU, 510KB http://sighan.cs.uchicago.edu/bakeoff2005/
3、人民日报 2014, 65MB https://pan.baidu.com/s/1hq3KKXe
1、MSR测试结果

2、PKU测试结果
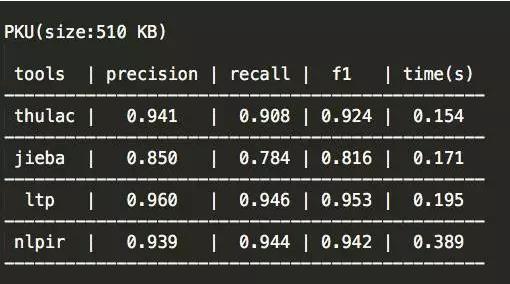
3、人民日报测试结果

一个好的分词工具不应该只能在一个数据集上得到不错的指标,而应该在各个数据集都有很不错的表现。从这一点来看,thulac和ltp都表现非常不错。特别需要强调的一点是,哈工大的ltp支持分词模型的在线训练,即在系统自带模型的基础上可以不断地增加训练数据,来得到更加丰富、更加个性化的分词模型。
——————————————————————————————————————————
四、R中的JiebaR和wordseg
jiebaR是“结巴”中文分词(Python)的R语言版本,支持最大概率法(Maximum Probability),隐式马尔科夫模型(Hidden Markov Model),索引模型(QuerySegment),混合模型(MixSegment)共四种分词模式,同时有词性标注,关键词提取,文本Simhash相似度比较等功能。项目使用了Rcpp和CppJieba进行开发。目前托管在GitHub上。
来自:http://cos.name/tag/jiebar/
可参考: R语言︱文本挖掘——jiabaR包与分词向量化的simhash算法(与word2vec简单比较)
R语言︱文本挖掘之中文分词包——Rwordseg包
————————————————————————————————————————————————————————————
五、参考文献的罗列
1、张华平老师的书,还有其论文可以在百度学术找得到一些,还有一本书《大数据搜索与挖掘》
以上是关于NLP︱中文分词技术小结几大分词引擎的介绍与比较的主要内容,如果未能解决你的问题,请参考以下文章