sql中count函数的使用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql中count函数的使用相关的知识,希望对你有一定的参考价值。
碰见一条SQL语句(存储过程中的)
DECLARE @TempID int
SELECT @TempID = count(1) FROM t_ChanalInfo WHERE [Ch] = @Ch
我对这里面的count(1)不太明白,一般碰到的count都是写成count(*),哪位高手帮我讲一个这里面的1和*各代表什么
COUNT() 函数返回匹配指定条件的行数。
SQL COUNT(column_name) 语法
COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入):
SELECT COUNT(column_name) FROM table_name;
SQL COUNT(*) 语法
COUNT(*) 函数返回表中的记录数:
SELECT COUNT(*) FROM table_name;
SQL COUNT(DISTINCT column_name) 语法
COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目:
SELECT COUNT(DISTINCT column_name) FROM table_name;
注释:COUNT(DISTINCT) 适用于 ORACLE 和 Microsoft SQL Server,但是无法用于 Microsoft Access。
SQL COUNT(column_name) 实例
下面的 SQL 语句计算 "access_log" 表中 "site_id"=3 的总访问量:
实例
SELECT COUNT(count) AS nums FROM access_log
WHERE site_id=3;
SQL COUNT(*) 实例
下面的 SQL 语句计算 "access_log" 表中总记录数:
实例
SELECT COUNT(*) AS nums FROM access_log;
执行以上 SQL 输出结果如下:

SQL COUNT(DISTINCT column_name) 实例
下面的 SQL 语句计算 "access_log" 表中不同 site_id 的记录数:
实例
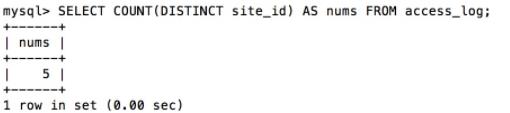
SELECT COUNT(DISTINCT site_id) AS nums FROM access_log;
执行以上 SQL 输出结果如下:
例如:
select
*
from
student
where
name
like
'张%';
//查询所有姓张的学生信息
select
count(*)
from
student
where
name
like
'张%'
//查询姓张的学生的人数
而count(列名)在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数。
select
count(en_score)
from
student
where
name
like
'张%'
//查询姓张的学生中有英语成绩的学生人数 参考技术B 给你发一个链接
有实例,就是一个mysql
的手册。http://www.w3school.com.cn/sql/sql_func_count.asp 参考技术C count(1)--等於count(*)
数据库引擎会把count(1)改为count(*)
主要是个人习惯
补充一下查看方法:
以下方式查看,楼上的不要误导.
SET SHOWPLAN_TEXT on ;
go
select count(1) from 表名
go
SET SHOWPLAN_TEXT off ;本回答被提问者采纳 参考技术D count是统计的函数 count是统计表中所有字段满足where里条件的行数,
这里的count (1)=count(*)应该是统计这个表中满足where里条件的行数 并把值赋给@tempID
如何在 SQL Server 中使用带有框架的窗口函数执行 COUNT(DISTINCT)
【中文标题】如何在 SQL Server 中使用带有框架的窗口函数执行 COUNT(DISTINCT)【英文标题】:How to do a COUNT(DISTINCT) using window functions with a frame in SQL Server 【发布时间】:2020-12-11 02:04:46 【问题描述】:捎带这个可爱的问题: Partition Function COUNT() OVER possible using DISTINCT
我希望计算不同值的移动计数。 大致如下:
Count(distinct machine_id) over(partition by model order by _timestamp rows between 6 preceding and current row)
显然,SQL Server 不支持该语法。不幸的是,我不太了解(没有内化会更准确)dense_rank 绕行是如何工作的:
dense_rank() over (partition by model order by machine_id)
+ dense_rank() over (partition by model order by machine_id)
- 1
因此我无法调整它以满足我对移动窗口的需要。
如果我按 machine_id 订购,是否也可以按 _timestamp 订购并使用rows between?
【问题讨论】:
试过dense_rank() over (partition by model order by _timestamp, machine_id rows between CURRENT ROW and 6 following) + dense_rank() over (partition by model order by _timestamp, machine_id rows between CURRENT ROW and 6 following) - 1但无济于事:“函数'dense_rank'可能没有窗口框架。” :-(
样本数据和预期输出会有所帮助。可能有更简单的方法
【参考方案1】:
只需使用outer apply:
select t.*, t2.num_machines
from t outer apply
(select count(distinct t2.machine_id) as num_machines
from (select top (6) t2.*
from t t2
where t2.model = t.model and
t2.timestamp <= t.timestamp
order by t2.timestamp desc
) t2
) t2;
如果每个模型有很多行,您还可以使用lag() 的(繁琐的)技巧:
select t.*, v.num_machines
from (select t.*,
lag(machine_id, 1) over (partition by model order by timestamp) as machine_id_1,
lag(machine_id, 2) over (partition by model order by timestamp) as machine_id_2,
lag(machine_id, 3) over (partition by model order by timestamp) as machine_id_3,
lag(machine_id, 4) over (partition by model order by timestamp) as machine_id_4,
lag(machine_id, 5) over (partition by model order by timestamp) as machine_id_5
from t
) t cross apply
(select count(distinct v.machine_id) as num_machines
from (values (t.machine_id),
(t.machine_id_1),
(t.machine_id_2),
(t.machine_id_3),
(t.machine_id_4),
(t.machine_id_5)
) v(machine_id)
) v;
在许多情况下,这可能在 SQL Server 中具有最佳性能。
【讨论】:
【参考方案2】:dense_rank() 给出当前记录的密集排名。当您首先使用ASC 排序顺序运行它时,您会从第一个元素中获得当前记录的密集排名(唯一值排名)。当您使用DESC 命令运行时,您会从最后一条记录中获得当前记录的密集排名。然后你删除 1 因为当前记录的密集排名被计算了两次。这给出了整个分区中的总唯一值(并为每一行重复)。
由于dense_rank不支持frames,所以不能直接使用这个方案。您需要通过其他方式生成frame。一种方法可能是JOIN 使用适当的unique id 比较同一张表。然后,您可以在组合版本上使用dense_rank。
请查看以下解决方案建议。假设您的表中有一个唯一的记录键 (record_id)。如果您没有唯一键,请在第一个 CTE 之前添加另一个 CTE 并为每条记录生成一个唯一键(使用 new_id() 函数或使用 concat() 组合多列,并在其间使用分隔符以说明 NULLs)
; WITH cte AS (
SELECT
record_id
, record_id_6_record_earlier = LEAD(machine_id, 6, NULL) OVER (PARTITION BY model ORDER BY _timestamp)
, .... other columns
FROM mainTable
)
, cte2 AS (
SELECT
c.*
, DistinctCntWithin6PriorRec = dense_rank() OVER (PARTITION BY c.model, c.record_id ORDER BY t._timestamp)
+ dense_rank() OVER (PARTITION BY c.model, c.record_id ORDER BY t._timestamp DESC)
- 1
, RN = ROW_NUMBER() OVER (PARTITION BY c.record_id ORDER BY t._timestamp )
FROM cte c
LEFT JOIN mainTable t ON t.record_id BETWEEN c.record_id_6_record_earlier and c.record_id
)
SELECT *
FROM cte2
WHERE RN = 1
此解决方案有 2 个限制:
如果帧中的记录少于 6 条,则 LAG() 函数将为 NULL,因此此解决方案将不起作用。这可以通过不同的方式处理:我能想到的一种快速方法是生成 6 个 LEAD 列(1 条记录之前,2 条记录之前等),然后将 BETWEEN 子句更改为类似 BETWEEN COALESCE(c.record_id_6_record_earlier, c.record_id_5_record_earlier, ...., c.record_id_1_record_earlier, c.record_id) and c.record_id 的内容
COUNT() 不计入NULL。但是DENSE_RANK 可以。如果它适用于您的数据,您也需要考虑这一点
【讨论】:
以上是关于sql中count函数的使用的主要内容,如果未能解决你的问题,请参考以下文章
如何在 SQL Server 中使用带有框架的窗口函数执行 COUNT(DISTINCT)