Nutch + Hbase
Posted 无名氏0428
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Nutch + Hbase相关的知识,希望对你有一定的参考价值。
本文主要讲解内容包括:ant及ivy的搭建、Nutch + Hbase搭建
1、ant及ivy的搭建
1-1)ant下载地址http://ant.apache.org/bindownload.cgi
1-2)环境变量配置,修改linux /etc/profile文件内容,添加如下:
export ANT_HOME=/usr/ant
export PATH=$ANT_HOME/bin:$PATH1-3)下载ivy build.xml http://ant.apache.org/ivy/history/latest-milestone/samples/build.xml
1-4)在下载的路径下执行 ant 命令,成功后在ant的安装路径下新增ivy文件夹,并将ivy下的ivy.jar拷贝到ANT_HOME/lib目录下
2、Nutch + Hbase搭建
2-1)Nutch下载路径http://nutch.apache.org/downloads.html,选择对应的版本,本文选用apache-nutch-2.3.1-src.tar.gz
2-2)修改conf/nutch-site.xml,内容如下:
<configuration>
<property>
<name>http.agent.name</name>
<value>hbase_nutch</value>
</property>
<property>
<name>storage.data.store.class</name>
<value>org.apache.gora.hbase.store.HBaseStore</value>
<description>Default class for storing data</description>
</property>
<property>
<name>plugin.includes</name>
<value>protocol-httpclient|urlfilter-regex|parse-(html|tika)|index-(basic|anchor)|indexer-solr|scoring-opic|urlnormalizer-(pass|regex|basic)</value>
</property>
</configuration>2-3)conf/regex-urlfilter.txt,用来过滤抓取网站的URL规则,读者可以根据个人需求进行定制。
2-4)修改 ivy/ivy.xml,主要用来设置所依赖的版本,改动有如下:
添加Hbase支持,这里需要注意,由于版本兼容问题,这里使用0.98.13版本,笔者测试Hbase1.2版本,出现错误。
<dependency org="org.apache.hbase" name="hbase-client" rev="0.98.13-hadoop2" conf="*->default"/>
<dependency org="org.apache.hbase" name="hbase-common" rev="0.98.13-hadoop2" conf="*->default"/>
<dependency org="org.apache.hbase" name="hbase-protocol" rev="0.98.13-hadoop2" conf="*->default"/>
<dependency org="org.apache.gora" name="gora-hbase" rev="0.6.1" conf="*->default" />2-5)拷贝hbase集群配置文件,cp $HBASE_HOME/conf/hbase-site.xml $NUTCH_HOME/conf/
2-6)修改conf/gora.properties,添加如下配置
gora.datastore.default=org.apache.gora.hbase.store.HBaseStore2-7)配置抓取链接,在conf目录下创建urls目录,用来保存抓取链接,然后初始化种子文件seed.txt,内容添加如下:
http://www.csdn.net/ 
第一次时间比较长,需要下载jar包等等。
2-9)抓取内容,在runtime/local/bin下执行如下命令:
./crawl /usr/apache-nutch-2.3.1/conf/urls/ numberOfRounds 10 Usage: crawl <seedDir> <crawlID> [<solrUrl>] <numberOfRounds>
<seedDir>:放置种子文件的目录
<crawlID> :抓取任务的ID
<solrURL>:用于索引及搜索的solr地址
<numberOfRounds>:迭代次数,即抓取深度2-10)查看hbase监控页面网址为:http://lenovo1:16010/master-status,获取到 表名称为numberOfRounds_webpage,通过Spark代码读取如下:
// please ensure HBASE_CONF_DIR is on classpath of spark driver
// e.g: set it through spark.driver.extraClassPath property
// in spark-defaults.conf or through --driver-class-path
// command line option of spark-submit
val conf = HBaseConfiguration.create()
val args = Array[String]("numberOfRounds_webpage")
// Other options for configuring scan behavior are available. More information available at
// http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/mapreduce/TableInputFormat.html
conf.set(TableInputFormat.INPUT_TABLE, args(0))
// Initialize hBase table if necessary
val admin = new HBaseAdmin(conf)
if (!admin.isTableAvailable(args(0))) {
println("不存在该表")
return
//sc.stop()
}
val pool = new HTablePool(conf, 1000)
val table = pool.getTable(args(0))
try {
val rs: ResultScanner = table.getScanner(new Scan())
var r = rs.next()
while (r != null) {
System.out.println("获得到rowkey:" + new String(r.getRow))
for (keyValue <- r.raw()) {
System.out.println("(" + new String(keyValue.getFamily()) + "," + new String(keyValue.getQualifier()) + "):" + new String(keyValue.getValue()));
}
r = rs.next()
}
} catch {
case e => e.printStackTrace()
}
//sc.stop()
admin.close()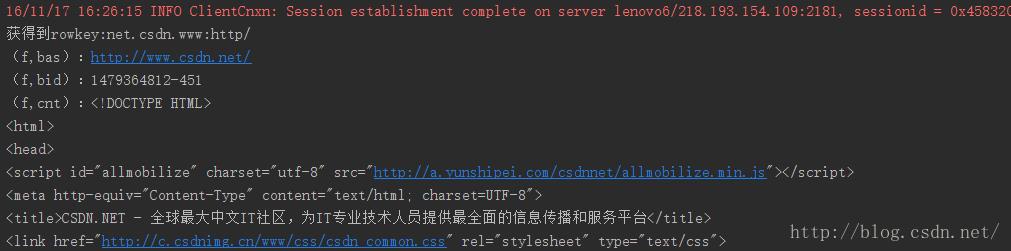
至此一个简单的示例完成了,读者可以在此基础上添加复杂业务逻辑。
以上是关于Nutch + Hbase的主要内容,如果未能解决你的问题,请参考以下文章
使用 Hbase 运行 Nutch 爬虫 2.2 时出现空指针异常
无法在 Hadoop2 上运行 Nutch2(Nutch 2.x + Hadoop 2.4.0 + HBase 0.94.18 + Gora 0.5 + Avro 1.7.6)
Apache Nutch、HBase、Hadoop、Solr、Gora 的困惑
软件Nutch2.3 + HBase 0.94 + Solr 搭建网络数据采集器