一:luecne初体验
Posted 代码改变生活
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一:luecne初体验相关的知识,希望对你有一定的参考价值。
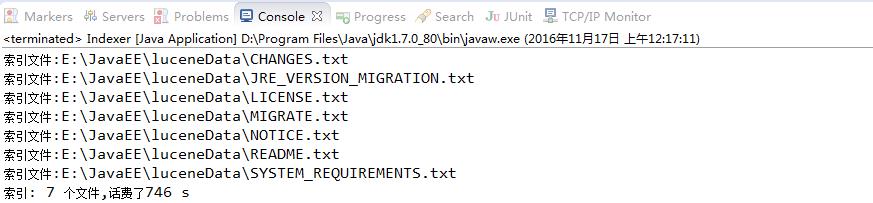
package com.cmy.lucene.lucene; import java.io.File; import java.io.FileReader; import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.TextField; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; public class Indexer { private IndexWriter writer; /** * 构造方法,实例化indexwriter * @param indexDir * @throws Exception */ public Indexer(String indexDir) throws Exception{ Directory directory = FSDirectory.open(Paths.get(indexDir)); Analyzer analyzer = new StandardAnalyzer();//标准分词器 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer); writer = new IndexWriter(directory, indexWriterConfig); } /** * * @throws Exception */ public void close() throws Exception{ writer.close(); } /** * * @param dataDir * @throws Exception */ public int index(String dataDir) throws Exception{ File []files = new File(dataDir).listFiles(); for(File file:files){ IndexFile(file); } return writer.numDocs();//返回索引文件的数量 } /** * 索引指定文件 * @param file * @throws Exception */ private void IndexFile(File file) throws Exception { System.out.println("索引文件:"+file.getCanonicalPath());//返回规范化的绝对路径 Document document = getDocument(file); writer.addDocument(document);; } /** * 获取文档,文档里再设置每个字段 * @param file * @return */ private Document getDocument(File file) throws Exception{ Document document = new Document();//定义文档对象 document.add(new TextField("contents",new FileReader(file)));//在文档中引入字段(key,value)形式 document.add(new TextField("fileName",file.getName(),Field.Store.YES)); document.add(new TextField("fullPath",file.getCanonicalPath(),Field.Store.YES)); return document; } public static void main(String[] args) { String indexDir = "D:\\\\lucene"; String dataDir = "E:\\\\JavaEE\\\\luceneData"; Indexer indexer = null; int numIndexed = 0; long start = System.currentTimeMillis(); try { indexer = new Indexer(indexDir); numIndexed = indexer.index(dataDir); } catch (Exception e) { e.printStackTrace(); e.printStackTrace(); }finally { try { indexer.close(); } catch (Exception e2) { e2.printStackTrace(); } } long end = System.currentTimeMillis(); System.out.println("索引: "+numIndexed+" 个文件,话费了"+(end-start)+" s"); } }
package com.cmy.lucene.lucene; import java.nio.channels.ScatteringByteChannel; import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; public class Searcher { public static void search(String indexDir,String qString) throws Exception{ Directory directory = FSDirectory.open(Paths.get(indexDir)); IndexReader reader = DirectoryReader.open(directory);//读取完整路径下的reader IndexSearcher iSearcher = new IndexSearcher(reader);//索引查询器,参数是Indexreader Analyzer analyzer = new StandardAnalyzer();//标准分词器 QueryParser parser = new QueryParser("contents", analyzer);//解析制定内容,使用制定分词器 Query query = parser.parse(qString); long start = System.currentTimeMillis(); TopDocs hits = iSearcher.search(query, 10);//传入query对象,返回的数据数量,此处返回前十条,哎,那总该有个顺序吧,怎么搞 long end = System.currentTimeMillis(); System.out.println("匹配"+qString+",总共花费"+(end-start)+" 毫秒"); //遍历结果集,获取文档 for(ScoreDoc scoreDoc:hits.scoreDocs){ Document document = iSearcher.doc(scoreDoc.doc);//获取结果集中的doc主键(id)并据此查询获取文档对象 System.out.println("fullPath: "+document.get("fullPath"));//获取完整的fullPath, } reader.close(); } public static void main(String[] args) { String indexDir = "D:\\\\lucene"; String dataDir = "Zygmunt Saloni"; try { search(indexDir,dataDir); } catch (Exception e) { e.printStackTrace(); } } }

以上是关于一:luecne初体验的主要内容,如果未能解决你的问题,请参考以下文章