用正则表示式分析网页
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用正则表示式分析网页相关的知识,希望对你有一定的参考价值。
昨晚现学现卖了一下正则表达式,记录一下
爬的网页:http://www.qiushibaike.com/hot/page/1/?s=4930745
首先来看源码
<a href="/users/13145907/" target="_blank" rel="nofollow"> <img src="http://pic.qiushibaike.com/system/avtnew/1314/13145907/medium/20140731141650.jpg" alt="一个小时的好汉"/> </a> <a href="/users/13145907/" target="_blank" title="一个小时的好汉"> <h2>一个小时的好汉</h2> </a> <div class="articleGender manIcon">28</div> </div> <a href="/article/117979974" target="_blank" class=‘contentHerf‘ > <div class="content"> <span>今天给儿子去买小笼包,旁边有个拾荒的老大爷手里就拿着一块钱问,包子怎么卖,老板说五块一笼,抬头看老大爷愣了一下,老大爷转身缓缓的走了,就听见老板在后面喊,老大爷,小笼包五块一笼,这里的包子一块钱三个,老板从别的大笼里面,夹出三个热腾腾的大肉包,当时有点莫名的感动!老板你是个好人</span> </div> </a> <div class="stats"> <span class="stats-vote"><i class="number">13550</i> 好笑</span> <span class="stats-comments"> <span class="dash"> · </span> <a href="/article/117979974" data-share="/article/117979974" id="c-117979974" class="qiushi_comments" target="_blank"> <i class="number">457</i> 评论
获取的源码里还有很多空格,这里为了显示方便手动删去了,其中加粗的部分,就是要获得的作者、内容、点赞数、评论数,这里首先强调一下一个很有用的表达式:
.*?
.*可以匹配任意多个字符,?指非贪婪模式,即会在满足条件的情况下尽可能短,经过多次实验,要匹配这种整段的还是不能偷懒,多用一些有特征的语句,比如
<div class="stats">,这种具有特殊性,多用几个就可以限定整段,需要注意的是换行符也需要匹配一下,现在详细说明一下
1. <a href="/users.*?title=" 匹配
<a href="/users/13145907/" target="_blank" rel="nofollow"> <img src="http://pic.qiushibaike.com/system/avtnew/1314/13145907/medium/20140731141650.jpg" alt="一个小时的好汉"/> </a> <a href="/users/13145907/" target="_blank" title="
开始用的是<a.*?title=",发现<a开头的太多了,匹配了过多的内容,记得勾选正则表示式和.匹配新行,效果如下:
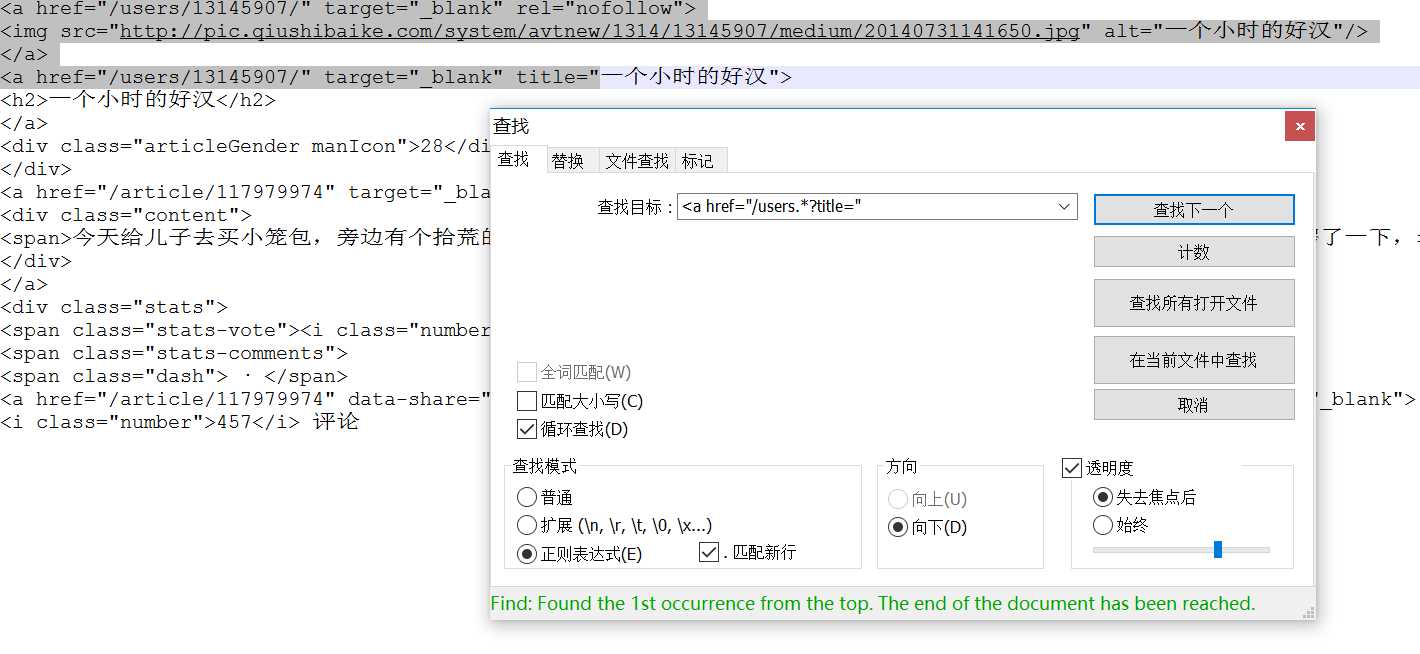
2.<a href="/users.*?title=".*?">.*?<div class="content">
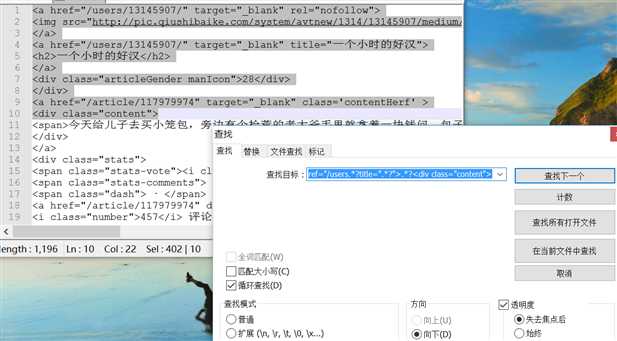
3. <a href="/users.*?title=".*?">.*?<div class="content">.*?<span>.*?</span>.*?"number">.*?</i>.*?number">.*?</i> 匹配全部