最大概率分词
Posted HOLD
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最大概率分词相关的知识,希望对你有一定的参考价值。
这里介绍一种分词的方法--最大概率分词,也叫1-gram分词,因为它不考虑上下文关系,只考虑当前词的概率。
我们需要有一个词典,里面记录每个词的频次,比如:

基于这个词典,我们可以将一句话用一个有向无环图(DAG)的表示出来,比如
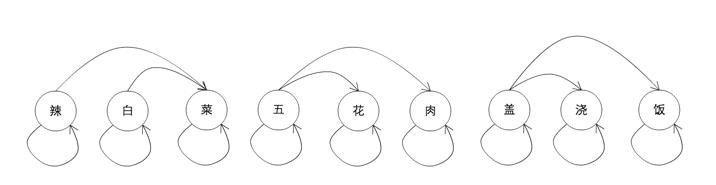
这个图里面,每个节点是一个字,边为两点构成词的概率。分词的问题,就是找出这个DAG里面概率和最大的一条从开始到结束覆盖所有字的路径。比如,辣-》菜,五-》肉,盖-》饭是一条路径,辣-》辣,白-》菜,五-》花,肉-》肉,盖-》饭也是一条路径,如何找到最大的那条呢?
设\\(\\alpha_i\\)为DAG中以i节点开始之后的部分的最优路径的累计概率,j为i的邻接点,那么容易的出\\(\\alpha_i = max_jp(w(i,j))\\alpha_{j+1}\\),w(i,j)是句子中i开始j结束的词。
这是一个动态规划问题,从最后一个字开始,基于以前的计算结果,逐步向前推移,直到第一个点,然后再从前往后得到最优路径。
python代码如下:
def build_DAG(sentence): DAG = {} #dict,key是每个word的index,value是以这个字开始能够构成的词list N = len(sentence) for k in xrange(N): tmp = [] i = k piece = sentence[k] while i < N and piece in dict.FREQ: if dict.FREQ[piece]: tmp.append(i) i += 1 piece = sentence[k:i + 1] if not tmp: tmp.append(k) DAG[k] = tmp return DAG
def calc_route(sentence, DAG, route): N = len(sentence) route[N] = (0, 0) logtotal = log(total_freq) for idx in xrange(N - 1, -1, -1): route[idx] = max((log(dict.FREQ.get(sentence[idx:x + 1]) or 1) - logtotal + route[x + 1][0], x) for x in DAG[idx])
def __cut_DAG(self, sentence): DAG = build_DAG(sentence) route = {} calc_route(DAG, route) x = 0 N = len(sentence) segs = [] while x < N: y = route[x][1] + 1 word = sentence[x,y] segs.append(word) x = y
以上是关于最大概率分词的主要内容,如果未能解决你的问题,请参考以下文章