unity3d 怎样优化大场景模型
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了unity3d 怎样优化大场景模型相关的知识,希望对你有一定的参考价值。
把大场景分成很多小场景。把地形跟建筑分开加载。比如有一个大场景,把他地形单独拿出来,分成比如10个小场景。然后把场景上的建筑用代码动态加载。
当你进入第一个场景,加载跟第一个场景连接的第二个场景,当你快走到第二个场景,显示第二个场景,并用代码加载场景里的建筑,再把第一个场景隐藏,同时加载第三个场景。然后如果你走向第一个场景则再次显示第一个场景,同时可以销毁第三个场景。以此类推。 参考技术A 第一,实际项目中一般不会直接把一个完整的场景导入Unity3D中,就像 @周华 所说,因为这样会增加Culling和Occlusion的难度,你把整个场景作为一个模型整体导入这样是没法做剔除的,这样对效率可能会有所影响。 第二、如果你希望将场景导入到Unit。本回答被提问者采纳 参考技术B 把模型导出FBX或者OBJ格式,然后上传到老子云平台上,一键优化
5大经典排序算法在淘宝“有好货”场景的实践

本文将介绍有好货推荐场景下的排序算法。有好货作为淘宝典型的内容导购场景,产品的定位是帮助消费升级人群发现口碑好货。排序作为推荐场景链路中重要环节,很大程度决定了推荐效率。过去一年,我们在排序算法的超长序列建模、多目标排序、模型结构优化、Loss优化、LTR等多个方向进行了持续迭代,并取得了一些进展,在这里分享给大家。
超长序列建模
用户兴趣序列建模一直是推荐系统排序算法优化的重点,使用用户的历史行为序列能够精准的预估用户对当前内容的兴趣偏好程度。受限于线上打分性能,难以对超长的用户兴趣序列进行attention建模,如果只是简单对超长序列进行mean pooling操作又会损失很多信息。针对这些问题,我们使用超长序列子序列提取+Attention,以及多个子序列Mean Pooling的建模方案。
▐ 类目检索序列 + Attention
介绍类目检索序列之前,我们先回顾下attention计算的公式:

当q和k不相关时,score(q,k)的值会近似为0,基于此我们可以事先筛选出超长序列中与当前商品相关的内容作为候选集进行Attention建模。
类目检索序列采取的筛选方案是使用融合类目(大类目下使用二级类目,小类目下使用一级类目)进行筛选,然后进行Attention建模,筛选的过程如下图所示:

类目检索序列在精排中的应用
在精排中,当前待打分商品对应的类目检索序列会进行在线获取,生成特征后输入模型中进行打分。精排中使用target attention对类目检索序列进行建模,模型结构如下图所示(真实模型中使用了多个序列进行建模,这里为方便表示,只列举了两个序列),其中“cate click seq”表示在线实时获取的类目检索序列。

添加类目检索序列后,精排模型离线AUC+1.1%、PV_GAUC+1.7%、CLICK_GAUC+1.7%,在线实验pctr+5.31%、uctr+1.60%、uclick+7.27%、dpv+7.32%。
类目检索序列在粗排中的应用
有好货粗排模型使用的是多塔的模型结构,无法进行Target Attention建模。另外粗排打分的内容接近一万个,在线获取近万个待打分商品对应的类目检索序列,性能开销大。针对这几个问题,粗排采取了以下解决方案:
Ø 使用self-attention对类目检索序列进行建模
Ø 离线计算类目向量、在线获取用户类目向量,输入模型进行打分
模型结构图如下:
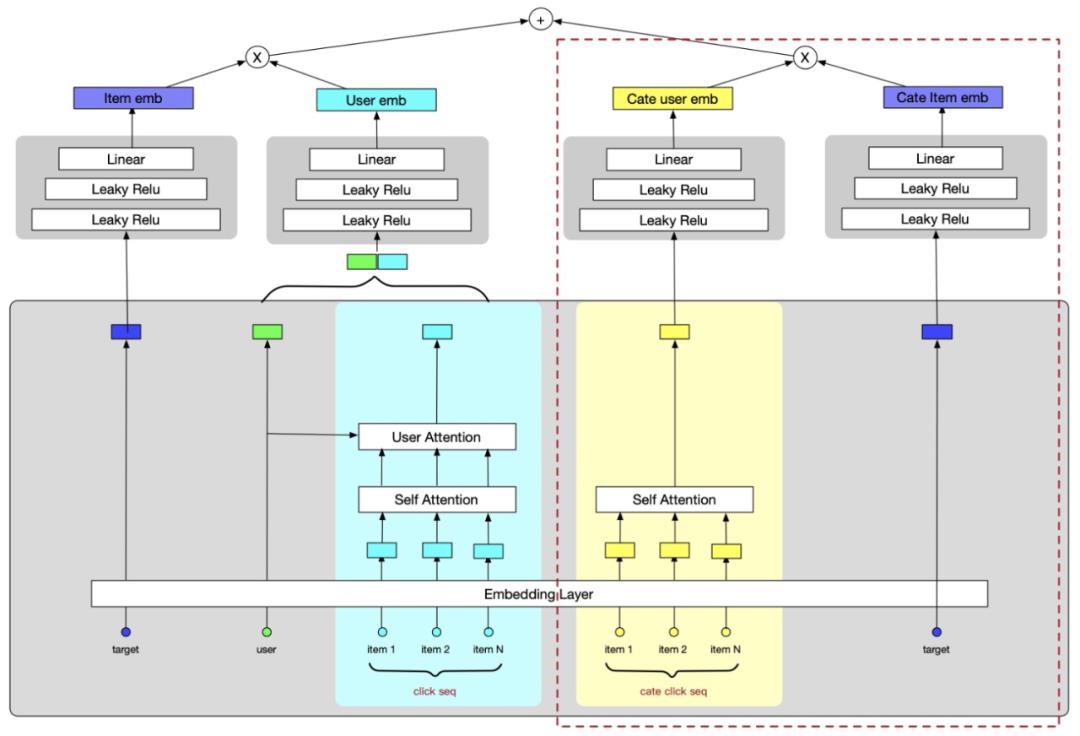
由于资源限制,离线计算得到所有用户的类目检索向量无法供在线获取。因此我们又进一步尝试了 1)只预测60d活跃用户以及 2)缩减维度预测所有用户 两种方案,最后我们线上使用的是缩减维度的方案。
各方案AUC和GAUC提升如下图所示:

缩减维度预测所有用户的在线实验,pctr+2.19%、uctr+2.48%、uclick+4.73%、dpv+4.83%。
▐ 原始超长点击序列建模
类目检索序列只考虑了target item类目下的长期兴趣,而忽视了其他类目的长期兴趣。为了补充其他类目的长期兴趣,我们尝试对用户的原始超长点击序列进行建模,我们主要尝试了以下四种方法:
Ø mean pooling:对序列中每个商品的特征concat后,直接做mean pooling
Ø 全连接 + mean pooling:用全连接层对序列中每个商品的特征进行融合后,直接mean pooling
Ø 子序列提取 + mean pooling:根据用户产生行为的时间,将原始序列拆分为不同的子序列,表示用户不同维度的兴趣,分别mean pooling后concat起来
Ø 动态路由 + target attention:利用动态路由算法提取超长点击序列的k个兴趣簇,构成新的序列,再做target attention
离线实验效果如下表所示:

出于性能与效果的综合考量,我们最后线上使用子序列提取+mean pooling的方案,作用于粗排和精排模型,在线实验效果如下表所示:

多目标排序
场景的优化目标过去一直关注在用户的一跳点击和二跳点击行为,而忽视了用户的种草行为。从导购场景角度来看,种草行为相比点击行为也更能反应用户的心智,因此场景的优化目标进一步升级为提高用户的种草效率,这里种草指在场景内的加购和收藏。
▐ 多目标排序模型结构
为了提高用户种草效率,有几种建模方案,一种是直接预估种草效率,还有一种是同时预估多个目标,然后融合多个目标分进行排序。为了保证一跳目标不会下降太多,我们选取了第二种方案,具体建模方案如下:
1)其他目标使用user_id、content_id为key,复用一跳样本,从而可以使用一跳埋点解析的实时特征提高预估效果
2)复用一跳模型参数,解决其他目标数据稀疏(Data Sparsity)问题,同时降低模型大小
3)通过梯度阻隔,只有CTR任务更新embedding层、attention层,防止点击率任务受其他任务影响
多目标精排模型
多目标精排的模型结构如下图所示,其中红色虚线框内的参数由CTR任务更新,其他任务只更新各自MLP层参数。
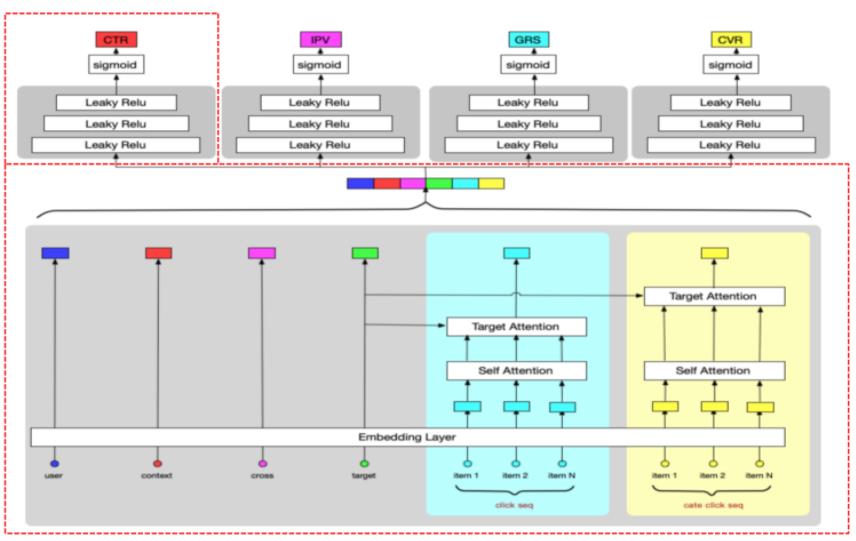
多目标精排上线实验效果:人均点击-5.38%,pctr-3.46%,人均IPV+1.46%,人均加购+8.79%,人均收藏+7.74%,加购uv比率+6.72%,收藏uv比率+3.86%。
多目标粗排模型
多目标粗排的模型结构如下图所示,每个目标构建单独的user tower,多个目标的双塔内积得到每个目标的得分,然后通过公式进行分数融合。
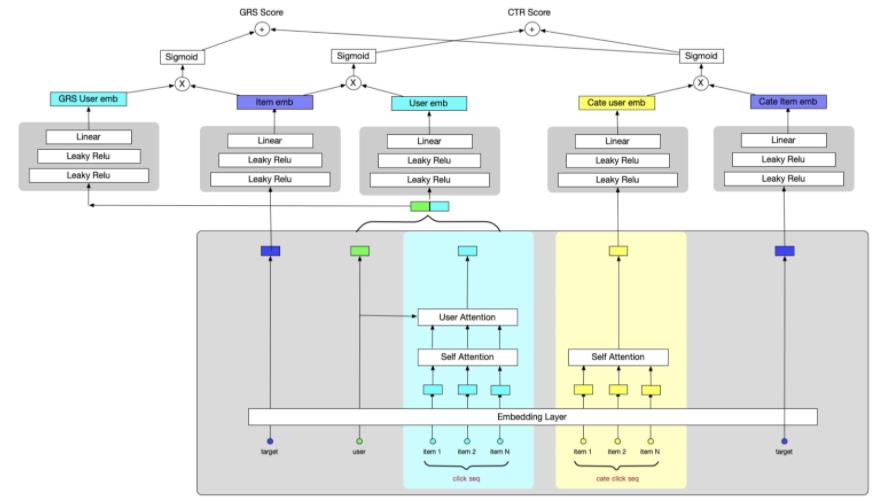
多目标粗排模型上线实验效果:人均点击-0.02%,pctr-0.47%,人均IPV+3.28%,人均加购+7.31%,人均收藏+4.39%。
▐ 多目标融合公式
多目标排序中比较常见的问题就是选择适合场景目标的融合排序公式,我们分别尝试了加法公式、乘法公式、混合公式。
1. 加法公式
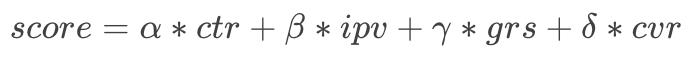
2. 乘法公式
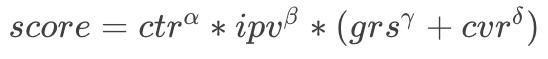
3. 混合公式

其中加法公式线上有一定效果,一跳点击下降较少,种草行为提升较多,乘法公式一跳下降较多,种草行为提升也没加法公式高,而混合公式能够在加法公式的基础上进一步提升种草行为,最后我们选择了混合公式作为场景的多目标融合排序公式。
在混合公式的基础上我们又尝试了几组参数,各参数的实验效果(本次实验是在叠加召回、粗排等优化后进行的参数探索实验,所以各项指标都有比较明显的提升)如下图所示:

其中实验三效果会比较好,即α=1,β=2.5,γ=15,δ=15。如果进一步提高种草系数,各指标会有所下降。
在实验三的基础上我们统计了线上埋点得到的各目标分在融合分中的占比,发现CTR、IPV、GRS、CVR比重呈现递减趋势,其中CTR指标比重最高,由于当前业务阶段更关注种草,所以支付权重占比较低。

结构优化
在模型结构上我们也尝试了一些优化工作,如CAN、MMoE、ESMM、模型重构、CrossAttention、加宽加深、Special Layer(各任务拥有独立的Attention参数)、模型拆解等。这里重点介绍CAN、MMoE、ESMM、模型重构等相关的工作。
▐ CAN
关于CAN的详细介绍可以参考相关文献,介绍CAN之前我们先介绍下特征交叉的两种常见形式:
Ø 笛卡尔积:强记忆性,缺点是组合特征量大,多数低频,学习过程不稳定
Ø FM:强泛化性,缺点是特征交叉容易受各自单独学习的过程影响,导致过度泛化
而CAN通过引入Co-Action Unit结构,能够在保证提高泛化性的同时增强记忆性Co-Action Unit的结构中,item特征在look up后通过reshape操作得到weights和bias,作为Co-Action结构中MLP层的参数,user特征在look up后对一阶、二阶、三阶操作求和得到高阶表达,作为MLP层的输入。离线进行了笛卡尔积和FM的实验:
Ø CAN实验离线CTR AUC+0.3%,在线人均点击+0.87%,种草指标几乎持平。
Ø 笛卡尔积,将target与序列的item id进行拼接作为的新的hash key,由于构造后序列过于稀疏,离线auc-0.2%。
▐ MMoE + ESMM
MMoE和ESMM的详细介绍可以参考具体论文,这里主要介绍引入MMoE和ESMM的目的,引入后的模型结构以及实验效果。
引入MMoE主要是为了让各任务能够共享更复杂的高阶特征,引入ESMM主要是为了将子空间的学习上升到全空间学习,缓解其他任务的样本选择偏差(Sample Selection Bias)问题 ,另外通过引入前序任务预估值,缓解其他任务正样本稀疏(Data Sparsity)问题。
引入MMoE和ESMM的模型结构如下:

实验效果:
Ø 对比base模型,MMoE离线实验,CTR AUC-0.5%,clk->ipv(子空间)AUC 持平,ipv->crt(子空间)AUC+1.0%。在线实验:人均点击+0.42%、人均ipv+0.41%、加购uv比率-0.03%、收藏uv比率+0.24%、uv转化率+1.65%。
Ø 对比base模型,ESMM离线实验(只CTR任务更新emb参数和attention层参数,各任务更新各自MLP参数),CTR AUC持平,pv->ipv(全空间)+0.1%,pv->crt(全空间)+0.2%。在线实验各指标略微提升。
其中clk表示一跳点击,ipv表示在二跳点击,crt表示三跳加购。由于实验效果只是略微提升,但上线后RT上涨较多,两个结构优化的工作未叠加上线。
Loss优化
在Loss优化方面我们尝试了Focal Loss和GHM Loss。
▐ Focal Loss
在模型训练过程中,存在很多简单易学的样本,这些样本会主导模型的训练过程。Focal Loss通过引入α、根据预估值与实际label的偏差对训练样本中的难样本增加权重,从而增强难样本的学习,大大降低简单样本的分类损失。

Focal Loss离线实验CTR AUC+0.3%,但整体CTR预估分偏高,影响多目标模型参数的设定,未上线实验。
▐ GHM Loss
GHM Loss的作者分析真实样本中的梯度分布(如下图左一所示)以及梯度贡献(如下图右一)的分布,发现Focal Loss容易关注异常样本的学习。其中梯度小的为容易学的样本,梯度大的为困难样本,这两种样本梯度密度都比较大,作者认为梯度接近1的可能是异常样本,过渡关注这部分样本的学习会导致模型学习效果变差,在模型学习过程中更应该关注梯度密度小的那部分样本的学习。

梯度计算公式如下图所示,p表示预测值,p*表示真实值。

GHM Loss离线实验AUC+0.3%,GAUC-0.3%,线上实验效果略微负向,且会导致曝光集中度上升。
LTR
业务目标升级为多目标后,需要一个灵活的排序模型进行多目标的融合,因此我们在推荐链路上添加了LTR层。我们探索了两种LTR建模方式:Stacking和Mixed Sampling。
▐ Stacking
进行Stacking建模时,我们调研了一些特征,发现在有好货场景,比较有效的是上页的曝光点击序列,user和cate的实时统计特征也会有一定效果,而user和item的实时统计特征则比较弱。
Stacking的模型结构如下图所示:

进行Stacking建模时,我们发现引入实时的用户行为特征(上一页曝光点击)后,不同Page之间的分数不可比,新请求的Page预估分会更准。为了方便进一步分析,我们使用了Page GAUC指标(按照每page作为group,计算AUC),发现引入更多实时特征后,page>1的Page GAUC提升更明显。

添加实时特征的Stacking模型离线实验AUC+1.7%,Page PV GAUC+0.5%,Page CLICK GAUC+0.4%。在线实验pctr+1.52%,upv+1.06%,uclick+2.62%,uipv+1.89%。
▐ Normalization
进行Stacking实验时,我们发现随着CTR预估分的分布发生变化,之前多目标排序融合公式的权重不一定适配新的分布。我们使用Normalization将各目标分布调整到0均值左右,再进行权重的调整。
标准化公式如下所示,标准化后各目标分布在0均值左右,更方便选择合理的权重值:

调整后的公式如下所示:

Normalization在线实验效果:

▐ Mixed Sampling
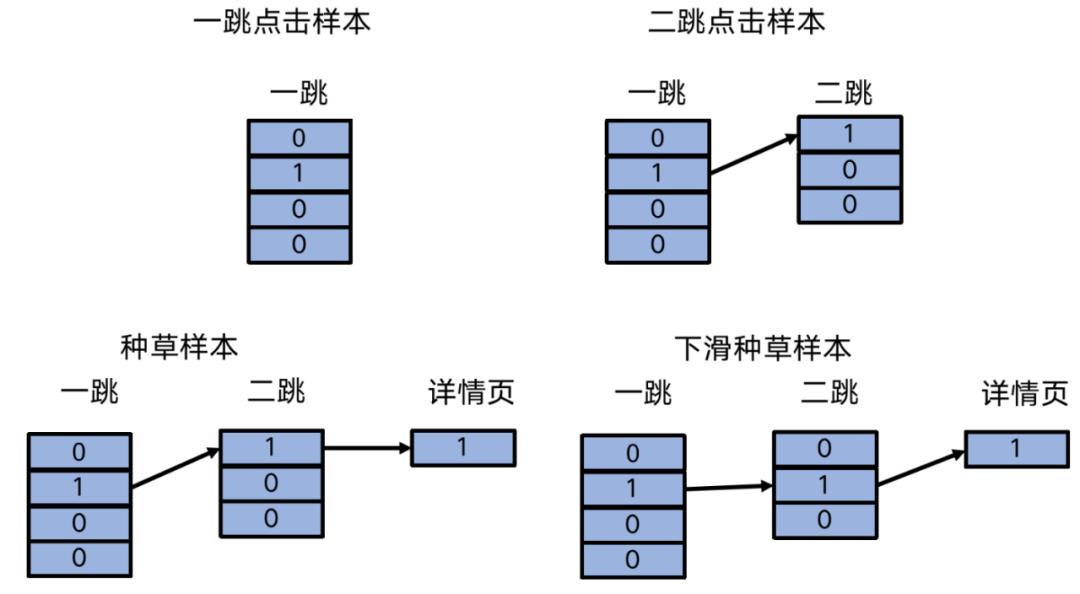
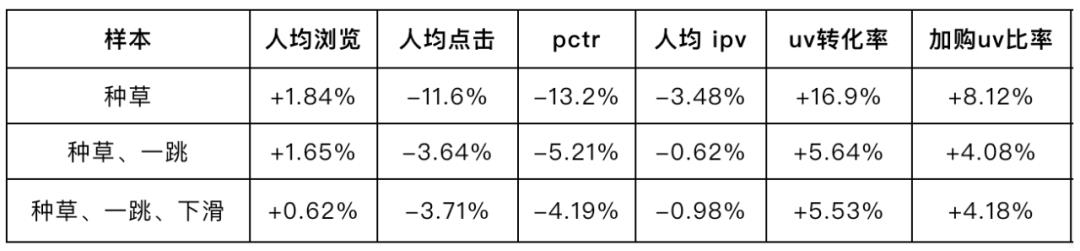
场景的优化目标升级为种草目标后,我们尝试了融合多目标预估的CTR、IPV、CRT预估分,再添加其他实时特征等,直接预估种草目标,线上排序时使用预估的种草目标分进行排序,但上线后发现一跳的人均点击下降比较多。因此我们尝试了在种草样本中添加一跳样本,来尽量减少人均点击的下降,在线也取得了一定效果。进一步添加下滑种草样本后,线上效果提升幅度不大。
各样本图示化表示:
在线实验效果:
总结
本文选取有好货过去一段时间在排序算法上的部分工作进行重点介绍,除以上工作外,我们还进行了其他尝试和探索,如精排蒸馏、粗排未曝光样本利用、首猜样本学习、多场景内容点击序列、二跳特有序列和特征、ODL等。后续我们会继续在超长序列建模、内容通用表征学习、排序结构优化、LTR建模等方面进行优化,以进一步提高场景的导购体验和导购效率。
✿ 拓展阅读



作者|鸿远、孑行、晨良、徐往、从之、肖荣
编辑|橙子君
出品|阿里巴巴新零售淘系技术


以上是关于unity3d 怎样优化大场景模型的主要内容,如果未能解决你的问题,请参考以下文章