C语言写的链表。明明没有错误,为啥编译器还会报错,?而且还爆出100+的错误,求解。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C语言写的链表。明明没有错误,为啥编译器还会报错,?而且还爆出100+的错误,求解。相关的知识,希望对你有一定的参考价值。
太长没有办法发过来,http://tieba.baidu.com/p/2077544469百度贴把的连接
参考技术A 就是前面和后面有点问题,直接用下面的替换掉对应的部分就行了。你去私信里复制代码吧,私信里复制粘贴后不是一整行。
#include<malloc.h>
#include<stdio.h>
#include<stdlib.h>
/*-----------------------------------数据类型定义----------------------------------------*/
typedef struct node
int data; //链表结构,链表的数据域
struct node *next; //链表的结构,链表的指针域
LINKLIST;
LINKLIST * set(); //声明将要用到的建立链表的函数
void insert(LINKLIST*); //这里声明了一个插入添加数据的函数!!!声明一个带有参数的函数的时候记得传递参数!
void output(LINKLIST*); //声明一个输出函数
void del(LINKLIST*); //删除一个数据的声明
void alter(LINKLIST*); //修改一个结点的数据
void select(LINKLIST*); //查询某个位置的数据
void select1(LINKLIST*); //高级查询,查询数据所在的位置
/*------------------------------------主函数----------------------------------------*/
void main() //主函数
...............................
...............................
...............................
...............................
/*---------------------------------------------查询某个结点在哪几个位置上出现---------------------------------------------*/
void select1(LINKLIST *SQ)
LINKLIST *q;
LINKLIST *p;
q = (LINKLIST*)malloc(sizeof(LINKLIST));
p = (LINKLIST*)malloc(sizeof(LINKLIST));
p->data = -1;
q = p;
printf("Please input the query node data:");
int data;
// int sum[100];
// sum[0] = -1;
scanf("%d",&data);
for(int i = 1,j = 0;SQ->data!=NULL;i++) //如果SQ不是空的则一直检索下去
if(SQ->data == data) //如果检索到相同的就将这个结点的位置保存到sum数组中。
q->data = i;
q = q->next;
//sum[j+1] = sum[j];
//sum[j] = i;
//j++; SQ = SQ->next;
if(p->data == -1) //如果检索完之后sum[0]还是-1那么就输出没有找到
printf("Did not find the same data");
else //否则输出数据
while(p->data!=NULL)
printf("%d",p->data);
p = p->next;
//int j =1;
//while(sum[0]!=-1)
//
// printf("%d\t",sum[j]);
// j++;
//
/*------------------------------------定义插入结点链表函数----------------------------------------*/
LINKLIST *set() //定义插入结点链表函数
printf("please input the integer to inster :\n");
/*Q 是用来返回的头结点,P用来新建结点,Prep用来设置表尾结点。Prep*/
LINKLIST *P,*Q,*Prep;
int x = 0;
Q = (LINKLIST*)malloc(sizeof(LINKLIST)); //为要输入的链表指针定义空间。
Q->data = -1;
Q->next = NULL;
Prep = Q; //把Q给了Prep Q依旧是头结点,以后输入每一次都给Prep赋值。 scanf("%d",&x); //输入要插入的数值。
while(x!=-1)
P = (LINKLIST *)malloc(sizeof(LINKLIST));
P->data = x; //使用P作为一个中转链结点,
P->next = NULL;
Prep->next = P; //链表的最后一个结点的后一个结点为P
Prep = Prep->next; //保证Prep一直是最后。因为每次插入表尾结点都是在最后。
scanf("%d",&x);
P = P->next; //这样的话可以随时释放临时的P结点,节约空间。
Prep->next = NULL; //结点的最后一个为空
free(P);
/*如果没有P = P->next;这里的P不可以释放。
因为当时P的值是给了Prep->next的。
又执行Prep = Prep->next 导致现在得P是链表中的最后一个结点。*/
return(Q);
追问
后一段也发下私信好吗?还有告诉我为什么好吗?那一段出了问题?
倒数第二个函数的大括号那不是刚刚好吗?
不是,已经发了。选择一段代码,然后按Alt+F8,就会帮助对齐代码,这样看就比较清楚了。
追问问题检查出来了。我用的是C编译的,一开始用的是C++,C++中变量的定义可以在语句的中间,而C却不可以,导致出现了现在的情况。
本回答被提问者采纳 参考技术B 会不会是编译器的版本不同啊 你写的是哪个版本的C语言追问一开始的时候编译好好的,就是这个代码,后来我想放到每个头文件一个函数,结果没弄好,我又把各个函数拷贝回来,当时没有做备份,然后就悲剧了,换了VS2008编译也不能。
我这里还有编译成功的exe文件可以运行呢
Java千问:Java语言中为byte和short类型变量赋值为啥会报错?
咱们先来看一段很简单的Java代码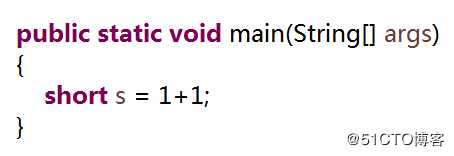
这段代码非常简单,没有任何技术含量。但是,如果我们把这段代码改成下面的样子
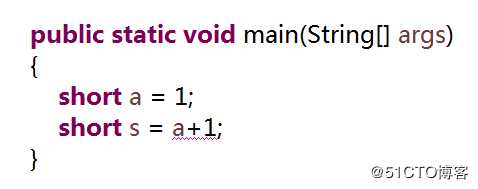
大家可以看到,我们只是用一个变量a代替了原来赋值表达式当中的常量1,就会出现语法错误,这是为什么呢?今天我们就用一篇短文来聊聊这个话题。
我们知道,Java语言中有4种整数类型,分别是byte、short、int和long。其中,Java编译器对byte和short类型的变量在赋值的时候,做了一点点“特殊检查”。那么编译器如何“特殊检查”这两种类型的变量呢?当编译器看到为这两种类型的变量进行赋值的时候,要进行“超范围检查”,也就是说,会检查一下给变量所赋的值会不会有可能超过范围。如果编译器认为所赋的值有可能超过这个变量所能存储的最大值或最小值,那么就会报语法错误。但是很多人都会问,程序中给变量s所赋的值并没有超过范围,为什么会报错呢?
这就要说说编译器的检查机制。当编译器看到程序中并不是用一个简单的数值对变量s进行赋值,而是把一个算术表达式赋值给了s,并且算术表达式中还出现了变量。这时候编译器就会认为这次赋值操作有可能会把一个超范围的值赋值给s,所以就报错。
可能有读者会问:第1段代码当中,也是用算术表达式给变量s赋值,为什么会就没有出现语法错呢?问题就在于:第2段程序中,给变量s赋值的算术表达式里出现了变量。编译器认为,既然是“变量”,就有可能发生改变,是一种不确定因素。编译器并不去管变量当前的值到底是多少,它认为只要是变量参与了运算,变量值有可能变化,从而可能导致赋值超范围,因此报出了语法错误。
如果我们把第2段程序中的变量a前面加上一个final关键字会如何呢?请看下面的代码
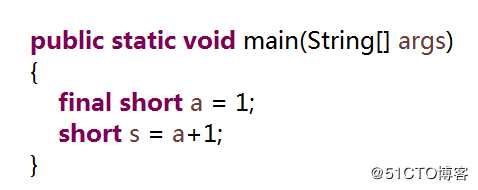
当a前面加上了final关键字,a的值不能再发生变化,它变成了一个常量。编译器就会认定这次赋值是安全的,因为a的值永远都是1,赋值肯定不会超过范围。
那么,是不是给s赋值的算术表的时候中不出现变量,赋值操作就一定不会报错呢?其实并不是这样,请看下面的例子
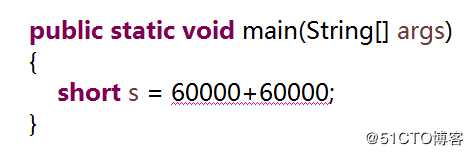
这次赋值操作,“=”右边的算术表达式中并没有出现变量,但是仍然会报语法错误,原因就是,编译器会提前把算术表达式的值算出来,如果发现算出来的值已经超过了byte或short的数据范围,也会报错。因此第4段程序也不能通过编译。
到这里,大家可以记住两个结论:
1.给byte或short变量进行赋值时,“=”右边如果是一个算术表达式,并且表达式中出现变量,肯定无法通过编译。
2.即使用常量给byte或short变量进行赋值,如果在“编译阶段”就能确定所赋的值已经超过了范围,同样会报错。
另外还要提醒大家,对int和long类型的变量进行赋值的时候,编译器并不采用这样的特殊检查措施。

大家可以看到,在上面的程序中,我们给int类型变量i1赋值时,“=”右边也是一个算术表达式,并且表达式中也有变量,但不会出现语法错误。而给i2进行赋值时,“=”右边的值已经超过了int类型的范围,也不会有问题。
通过这篇短文,相信小伙伴一定能弄明白为什么给byte和short变量赋值的时候会出错的原因。
如想系统学习Java编程,可以点击这里观看视频课程,有问题也可以加入我的QQ群291839907一起讨论!
以上是关于C语言写的链表。明明没有错误,为啥编译器还会报错,?而且还爆出100+的错误,求解。的主要内容,如果未能解决你的问题,请参考以下文章
在VS2019中编写C语言的链表程序出现了C4473等错误,怎么修改?