十四、fileinput模块
十五、shutil模块
十六、zipfile模块
十七、getpass模块
十八、bisect模块
十九、logging模块
二十、loguru模块---管理日志
二十一、schedule模块--定时任务
二十二、yagmail模块--自动发邮件
十四、fileinput模块
===========================================================================
使用过python内置的open方法处理文件的同学都知道,它没有直接修改文件内容的方法。这个fileinput可以帮助我们轻松的实现文件内容的修改功能。fileinput模块中的重要方法如下:
input([files[, inplace[, backup]])
最重要的方法,用于遍历打开的文件,inplace为True的时候,会将修改写入文件,backup为True的时候会进行备份操作。
filename()
返回当前文件的名字
lineno()
返回当前(累计)的行数。同时处理多个文件时,行数会累计。
filelineno()
返回当前文件的总行数。处理新文件时,行数会重置为1,重新计数。
isfirstline()
检查当前行是否是文件的第一行
isstdin()
检查最后一行是否来自sys.stdin
nextfile()
关闭当前文件,移动到下一个文件(fileinput是可以同时处理多个文件的!)
close()
关闭整个文件链,结束迭代。
为了演示fileinput的使用,假设编写了如下的一个脚本,想要为其代码进行编号。为了让脚本在进行代码编号后仍然能够正常运行,我们只能在每一行的右侧加上#来注释行号。其中,我们假定每个代码行最多有40个字符。具体代码如下:
import fileinput
f = fileinput.input(inplace=True)
for line in f:
line = line.rstrip()
num = fileinput.lineno()
print("%-40s # %2i" % (line, num))
f.close()
注意,只能使用rstrip,不能直接用strip,那样会把左边的缩进也给去掉了。
请在终端环境下,使用python fileinput_test.py fileinput_test.py的方式执行程序,结果如下:
import fileinput # 1
# 2
f = fileinput.input(inplace=True) # 3
for line in f: # 4
line = line.rstrip() # 5
num = fileinput.lineno() # 6
print("%-40s # %2i" % (line, num)) # 7
f.close() # 8
要小心使用inplace参数,它会修改文件。应该在不适用inplace设置的情况下仔细测试自己的程序(这样只会打印出结果),在确保程序工作正常后再修改文件。
十五、shutil模块
====================================================================
shutil模块是python为我们封装的一个高级的高级的文件、文件夹、压缩包 处理模块,它本质上是调用open方法对文件进行读写。模块相对比较简单,记住几个常用的方法即可。
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中。这个是基本方法,其他的拷贝方法都是在后台调用这个方法。
import shutil
shutil.copyfileobj(open(\'old.xml\',\'r\'), open(\'new.xml\', \'w\'))
shutil.copyfile(src, dst)
拷贝文件
shutil.copyfile(\'f1.log\', \'f2.log\')
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copymode(\'f1.log\', \'f2.log\')
4、shutil.copystat(src, dst)
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat(\'f1.log\', \'f2.log\')
5、 shutil.copy(src, dst)
拷贝文件和权限
shutil.copy(\'f1.log\', \'f2.log\')
6、shutil.copy2(src, dst)
拷贝文件和状态信息
shutil.copy2(\'f1.log\', \'f2.log\')
7、shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹。ignor_patterns是指忽略不拷贝的文件
shutil.copytree(\'folder1\', \'folder2\', ignore=shutil.ignore_patterns(\'*.pyc\', \'tmp*\'))
8、shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
shutil.rmtree(\'folder1\')
9、shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
shutil.move(\'folder1\', \'folder3\')
10、shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
创建压缩包并返回文件路径,例如:zip、tar
● base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如:www =>保存至当前路径
如:/Users/wupeiqi/www =>保存至/Users/wupeiqi/
● format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
● root_dir: 要压缩的文件夹路径(默认当前目录)
● owner: 用户,默认当前用户
● group: 组,默认当前组
● logger: 用于记录日志,通常是logging.Logger对象
#将 /Users/wupeiqi/Downloads/test 下的文件打包放置当前程序目录
import shutil
ret = shutil.make_archive("wwwwwwwwww", \'gztar\', root_dir=\'/Users/wupeiqi/Downloads/test\')
#将 /Users/wupeiqi/Downloads/test 下的文件打包放置 /Users/wupeiqi/目录
import shutil
ret = shutil.make_archive("/Users/wupeiqi/wwwwwwwwww", \'gztar\', root_dir=\'/Users/wupeiqi/Downloads/test\')
shutil 对压缩包的处理本质上是调用 ZipFile 和 TarFile 两个模块来进行的,但封装的比较简单,不是很好用,建议还是使用ZipFile 和 TarFile 模块。
十六、zipfile模块
==========================================================
当你需要压缩文件的时候,使用这个模块会比较方便。
import zipfile
# 压缩
z = zipfile.ZipFile(\'laxi.zip\', \'w\')
z.write(\'a.log\')
z.write(\'data.data\') # 可以一个一个添加文件进压缩包
z.close()
# 解压
z = zipfile.ZipFile(\'laxi.zip\', \'r\')
z.extractall() # 这是一次性将压缩包内的文件全部解压出来
z.close()
要单独解压压缩包内的某个文件就需要先获得压缩包内的文件名列表。zipfile提供了一个namelist方法。
import zipfile
z = zipfile.ZipFile(\'laxi.zip\', \'r\')
ret = z.namelist()
print(ret)
z.close()
运行结果:
[\'testfile.bak\', \'testfile.dat\']
然后通过具体的文件名去解压某个文件。zipfile提供了extract方法。
import zipfile
z = zipfile.ZipFile(\'laxi.zip\', \'r\')
z.extract("testfile.bak")
z.close()
十七、getpass模块
===============================================================
getpass模块非常简单,它能够让你在输入密码的时候不会在屏幕上显示密码,安全性更高。注意:在pycharm环境里这个模块用不了!
getpass模块只有2个常用方法:getpass和getuser。参考下面的例子:
import getpass
pwd = getpass.getpass("请输入密码: ") # 可代替input方法,接收用户输入的密码
print(getpass.getuser()) # getuser方法会返回当前执行程序的用户名
十八、bisect模块
===================================================================
这是一个python内置的二分查找法模块,模块内只有4个方法:bisect_right、bisect_left、insort_right和insort_left。然后通过将bisect_right赋值给bisect,将insort_right赋值给insort实现向后兼容。实际使用中,是需要记住bisect和insort两个方法即可。
bisect模块的使用方法通常是:bisect.bisect(list,x),其中x表示要查找的值,list是一个默认已经排好序的列表。
bisect():返回值是x在列表中应处的位置下标,并不修改列表本身。
import bisect
x = 200
list1 = [1, 3, 6, 24, 55, 78, 454, 555, 1234, 6900]
ret = bisect.bisect(list1, x)
print("返回值: ", ret)
print("list1 = ", list1)
运行结果:
返回值: 6
list1 = [1, 3, 6, 24, 55, 78, 454, 555, 1234, 6900]
insort():返回值是None,但是会将x插入到列表中生成新的列表。x插在它的大小排序所在位置。
import bisect
x = 200
list1 = [1, 3, 6, 24, 55, 78, 454, 555, 1234, 6900]
ret = bisect.insort(list1, x)
print("返回值: ", ret)
print("list1 = ", list1)
运行结果:
返回值: None
list1 = [1, 3, 6, 24, 55, 78, 200, 454, 555, 1234, 6900]
十九、logging模块
===========================================================================
python提供logging日志记录模块,以下是logging模块配置参数
logging.basicConfig()函数可更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
logging简单测试
import logging
logging.debug(\'debug message\')
logging.info(\'info message\')
logging.warning(\'warning message\')
logging.error(\'error message\')
logging.critical(\'critical message\'
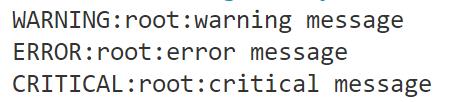
默认情况下logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),
默认的日志格式为日志级别:Logger名称:用户输出消息。
logging自定义格式输出
import logging
logging.basicConfig(level=logging.DEBUG,
format=\'%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s\',
datefmt=\'%a, %d %b %Y %H:%M:%S\',
filename=\'test.log\',
filemode=\'w\')
logging.debug(\'debug message\')
logging.info(\'info message\')
logging.warning(\'warning message\')
logging.error(\'error message\')
logging.critical(\'critical message\')
生成test.log文件,内容如下

logging对象配置
import logging
logger = logging.getLogger()
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler(\'test.log\',encoding=\'utf-8\')
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
formatter = logging.Formatter(\'%(asctime)s - %(name)s - %(levelname)s - %(message)s\')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(ch)
logger.debug(\'logger debug message\')
logger.info(\'logger info message\')
logger.warning(\'logger warning message\')
logger.error(\'logger error message\')
logger.critical(\'logger critical message\')
控制台:

log文件:

logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug)设置级别,当然,也可以通过fh.setLevel(logging.Debug)单对文件流设置某个级别。
二十、loguru模块---管理日志
安装:pip3 install loguru
loguru默认的输出格式是上面的内容,有时间、级别、模块名、行号以及日志信息,不需要手动创建 logger,直接使用即可,另外其输出还是彩色的,看起来会更加友好。
from loguru import logger
logger.add(\'my_log.log\') #加上该句会输出到文件,去掉则无
logger.info(\'普通信息\')
logger.debug(\'调试消息\')
logger.info(\'普通消息\')
logger.warning(\'警告消息\')
logger.error(\'错误消息\')
logger.critical(\'严重错误\')
logger.success(\'成功信息\')

运行之后会发现目录下 my_log.log 出现了刚刚控制台输出的 DEBUG 信息,并且控制台也会显示。
logurr详细使用
比如支持输出到多个文件,分级别分别输出,过大创建新文件,过久自动删除等等。
add 方法的定义
def add(
self,
sink: Union[str, PathLike[str]],
*,
level: Union[str, int] = ...,
format: Union[str, FormatFunction] = ...,
filter: Optional[Union[str, FilterFunction, FilterDict]] = ...,
colorize: Optional[bool] = ...,
serialize: bool = ...,
backtrace: bool = ...,
diagnose: bool = ...,
enqueue: bool = ...,
catch: bool = ...,
rotation: Optional[Union[str, int, time, timedelta, RotationFunction]] = ...,
retention: Optional[Union[str, int, timedelta, RetentionFunction]] = ...,
compression: Optional[Union[str, CompressionFunction]] = ...,
delay: bool = ...,
mode: str = ...,
buffering: int = ...,
encoding: str = ...,
**kwargs: Any
)
1 sink参数
它有个非常重要的参数 sink,通过 sink 我们可以传入多种不同的数据结构:
- sink 可以传入一个 file 对象,例如 sys.stderr 或者 open(‘file.log’, ‘w’) 都可以。
- sink 可以直接传入一个 str 字符串或者 pathlib.Path 对象,其实就是代表文件路径的,如果识别到是这种类型,它会自动创建对应路径的日志文件并将日志输出进去。
- sink 可以是一个方法,可以自行定义输出实现。
- sink 可以是一个 logging 模块的 Handler,比如 FileHandler、StreamHandler 等等。
sink 还可以是一个自定义的类。
刚才我们所演示的输出到文件,仅仅给它传了一个 str 字符串路径,他就给我们创建了一个日志文件,就是这个原理。
2 format、filter、level参数
这里使用 format、filter、level 来规定输出的格式:
logger.add(\'runtime.log\', format="{time} {level} {message}", filter="my_module", level="INFO")
3 rotation 配置
用了 loguru 我们还可以非常方便地使用 rotation 配置,我们可以直接使用 add 方法的 rotation 参数进行配置。
from loguru import logger
#每500MB 存储一个文件,log文件过大就会新创建一个log文件。在log名字时加上了一个time占位符,生成时可以自动生成一个文件名包含时间的log文件。
logger.add(\'runtime_{time}.log\', rotation="500 MB")
logger.add(\'runtime_{time}.log\', rotation=\'00:00\') #这样就可以实现每天 0 点新创建一个 log 文件输出了。
logger.add(\'runtime_{time}.log\', rotation=\'1 week\') #配置 log 文件的循环时间,每隔一周创建一个 log 文件
4 retention 配置
retention 这个参数可以配置日志的最长保留时间。比如我们想要设置日志文件最长保留 10 天,这样 log 文件里面就会保留最新 10 天的 log:
from loguru import logger
logger.add(\'runtime.log\', retention=\'10 days\')
5 compression 配置
loguru 还可以配置文件的压缩格式,比如使用 zip 文件格式保存:
from loguru import logger
logger.add(\'runtime.log\', compression=\'zip\')
6 删除 sink
另外添加 sink 之后我们也可以对其进行删除,相当于重新刷新并写入新的内容。
删除的时候根据刚刚 add 方法返回的 id 进行删除即可,看下面的例子:
from loguru import logger
trace = logger.add(\'my_log.log\')
logger.debug(\'调试信息\')
logger.remove(trace)
logger.debug(\'另一个调试信息\')
终端显示的内容:
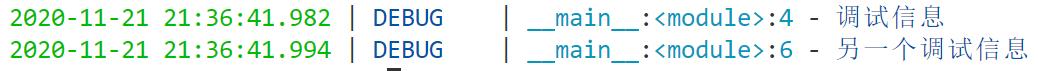
日志文件 my_log.log 内容如下:
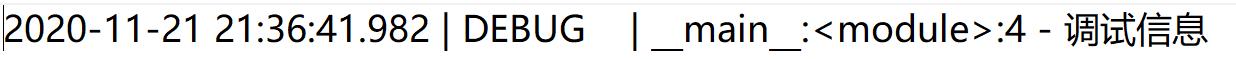
7 字符串格式化
loguru 在输出 log 的时候还提供了非常友好的字符串格式化功能:
from loguru import logger
logger.info(\'If you are using Python {}, prefer {feature} of course!\', 3.6, feature=\'f-strings\')
logger.debug(\'If you are using Python {}, prefer {feature} of course!\', 3.6, feature=\'f-strings\')
二十一、APScheduler定时任务调度框架
APScheduler简介
APScheduler(Advanced Python Scheduler)是一个轻量级的Python定时任务调度框架(Python库)。
使用pip安装:pip install apscheduler
APScheduler有三个内置的调度系统,其中包括:
- cron式调度(可选开始/结束时间)
- 基于间隔的执行(以偶数间隔运行作业,也可以选择开始/结束时间)
- 一次性延迟执行任务(在指定的日期/时间内运行作业一次)
APScheduler可以任意混合和匹配调度系统和作业存储的后端,其中支持后端存储作业包括:
- Memory
- SQLAlchemy
- MongoDB
- Redis
- RethinkDB
- ZooKeeper
APScheduler组件
APScheduler共有4种组件,分别是:
- 触发器(trigger),触发器中包含调度逻辑,每个作业都有自己的触发器来决定下次运行时间。除了它们自己初始配置以外,触发器完全是无状态的。
- 作业存储器(jobstore)存储被调度的作业,默认的作业存储器只是简单地把作业保存在内存中,其他的作业存储器则是将作业保存在数据库中,当作业被保存在一个持久化的作业存储器中的时候,该作业的数据会被序列化,并在加载时被反序列化,需要说明的是,作业存储器不能共享调度器。
- 执行器(executor),处理作业的运行,通常通过在作业中提交指定的可调用对象到一个线程或者进程池来进行,当作业完成时,执行器会将通知调度器。
- 调度器(scheduler),配置作业存储器和执行器可以在调度器中完成。例如添加、修改、移除作业,根据不同的应用场景,可以选择不同的调度器,可选的将在下一小节展示。
调度器
- BlockingScheduler : 当调度器是你应用中唯一要运行的东西时。
- BackgroundScheduler : 当你没有运行任何其他框架并希望调度器在你应用的后台执行时使用(充电桩即使用此种方式)。
- Asyncioscheduler : 当你的程序使用了asyncio(一个异步框架)的时候使用。
- GeventScheduler : 当你的程序使用了gevent(高性能的Python并发框架)的时候使用。
- TornadoScheduler : 当你的程序基于Tornado(一个web框架)的时候使用。
- TwistedScheduler : 当你的程序使用了Twisted(一个异步框架)的时候使用
- QtScheduler : 如果你的应用是一个Qt应用的时候可以使用。
作业存储器
如果你的应用在每次启动的时候都会重新创建作业,那么使用默认的作业存储器(MemoryJobStore)即可,但是如果你需要在调度器重启或者应用程序奔溃的情况下任然保留作业,你应该根据你的应用环境来选择具体的作业存储器。例如:使用Mongo或者SQLAlchemy JobStore (用于支持大多数RDBMS)
执行器
对执行器的选择取决于你使用上面哪些框架,大多数情况下,使用默认的ThreadPoolExecutor已经能够满足需求。如果你的应用涉及到CPU密集型操作,你可以考虑使用ProcessPoolExecutor来使用更多的CPU核心。你也可以同时使用两者,将ProcessPoolExecutor作为第二执行器。
触发器
当你调度作业的时候,你需要为这个作业选择一个触发器,用来描述这个作业何时被触发,APScheduler有三种内置的触发器类型:
- date 一次性指定日期,定时任务
- interval 在某个时间范围内间隔多长时间执行一次,间隔循环任务
- cron 和Linux crontab格式兼容,定时循环任务
使用
当你需要调度作业的时候,你需要为这个作业选择一个触发器,用来描述该作业将在何时被触发,APScheduler有3中内置的触发器类型:
- 新建一个调度器(scheduler)
- 添加一个调度任务(job store)
- 运行调度任务
有两种方式可以添加一个新的作业:
只执行一次
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
def job2(text):
print(\'job2\', datetime.datetime.now(), text)
scheduler = BlockingScheduler()
scheduler.add_job(job2, \'date\', run_date=datetime.datetime(2020, 11, 20, 12, 37, 6), args=[\'text\'], id=\'job2\')
scheduler.start()
上例中,只在2020-11-20 12:37:06执行一次,args传递一个text参数。
间隔执行
每5秒执行一次:
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
def job1():
print(\'job1\', datetime.datetime.now())
scheduler = BlockingScheduler()
scheduler.add_job(job1, \'interval\', seconds=5, id=\'job1\') # 每隔5秒执行一次
scheduler.start()
每几分钟执行一次:
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
def job1():
print(\'job1\', datetime.datetime.now())
scheduler = BlockingScheduler()
# 每隔1分钟执行一次
scheduler.add_job(job1, \'interval\', minutes=1, id=\'job1\')
scheduler.start()
每小时执行一次:
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
def job1():
print(\'job1\', datetime.datetime.now())
scheduler = BlockingScheduler()
# 每小时执行一次
scheduler.add_job(job1, \'interval\', hours=1, id=\'job1\')
# 每小时执行一次,上下浮动20秒区间内
# scheduler.add_job(job1, \'interval\', hours=1, id=\'job1\', jitter=20)
scheduler.start()
每天13点08分50秒执行一次
#实现1
from apscheduler.schedulers.blocking import BlockingScheduler # 后台运行
sc = BlockingScheduler()
@sc.scheduled_job(\'cron\', day_of_week=\'*\', hour=13, minute=\'08\', second=\'50\')
def check_db():
print(\'定时任务执行\')
if __name__ == \'__main__\':
try:
sc.start()
except Exception as e:
sc.shutdown()
#实现2
from datetime import datetime
import os
from apscheduler.schedulers.blocking import BlockingScheduler
def tick():
print(\'Tick! The time is: %s\' % datetime.now())
if __name__ == \'__main__\':
scheduler = BlockingScheduler()
scheduler.add_job(tick, \'cron\', day_of_week=\'*\',hour=13,minute=8)
print(\'Press Ctrl+{0} to exit\'.format(\'Break\' if os.name == \'nt\' else \'C \'))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
pass
定时 cron 任务也非常简单,直接给触发器 trigger 传入 ‘cron’ 即可。hour =19 ,minute =23 这里表示每天的19:23 分执行任务。这里可以填写数字,也可以填写字符串
hour =19 , minute =23
hour =\'19\', minute =\'23\'
minute = \'*/3\' 表示每 5 分钟执行一次
hour =\'19-21\', minute= \'23\' 表示 19:23、 20:23、 21:23 各执行一次任务
二十二、yagmail模块--自动发邮件
一般发邮件方法
import smtplib
from email.mime.text import MIMEText
from email.header import Header
其实,这段代码也并不复杂,只要你理解使用过邮箱发送邮件,那么以下问题是你必须要考虑的:
- 你登录的邮箱帐号/密码
- 对方的邮箱帐号
- 邮件内容(标题,正文,附件)
- 邮箱服务器(SMTP.xxx.com/pop3.xxx.com)
yagmail 可以更简单的来实现自动发邮件功能
安装pip install yagmail
简单例子
import yagmail
给多个用户发送邮件,只需要将接收邮箱 变成一个list即可。
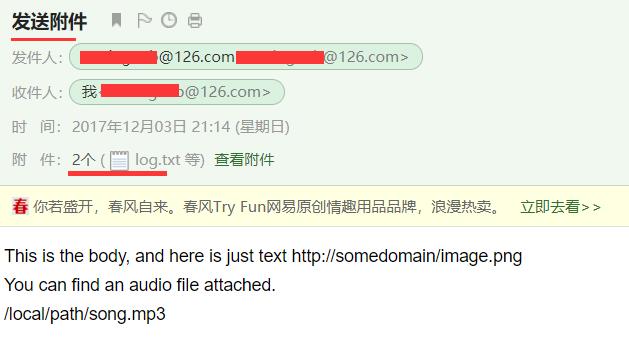
发送带附件的邮件
只需要添加要发送的附件列表即可。