RocketMQ原理解析-Broker
Posted 1900
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RocketMQ原理解析-Broker相关的知识,希望对你有一定的参考价值。
broker 1. broker的启动
brker的启动
Broker向namesrv注册
1. 获取namesrv的地址列表(是乱序的)
2. 遍历向每个namesrv注册topic的配置信息topicconfig
Topic在broker文件上的存储json格式
"TopicTest":{ "perm":6, "readQueueNums":8, "topicFilterType":"SINGLE_TAG", "topicName":"TopicTest", "writeQueueNums":8 }
Namesrv接收Broker注册的topic信息, namesrv只存内存,但是broker有任务定时推送
1. 接收数据向RouteInfoManager注册。
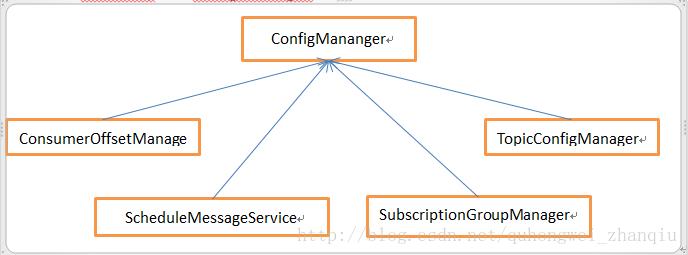
Broker初始化加载本地配置,配置信息是以json格式存储在本地, rocketmq强依赖fastjson作转换, RocketMq通过ConfigMananger来管理配置加载以及持久化


1. 加载topic配置${user.home}/store/config/topics.json
{
"dataVersion":{
"counter":2,
"timestatmp":1393729865073
},
"topicConfigTable":{
//根据consumer的group生成的重试topic
"%RETRY% group_name":{
"perm":6,
"readQueueNums":1,
"topicFilterType":"SINGLE_TAG",
"topicName":"%RETRY%group_name",
"writeQueueNums":1
},
"TopicTest":{
"perm":6, // 100读权限 , 10写权限 6是110读写权限
"readQueueNums":8,
"topicFilterType":"SINGLE_TAG",
"topicName":"TopicTest",
"writeQueueNums":8
}
}
}
2. 加载消费进度偏移量 ${user.home}/store/config/consumerOffset.json
{
"offsetTable":{
"%RETRY% group_name@group_name":{
0:0 //重试队列消费进度为零
},
"TopicTest@ group_name":{
0:23,1:23,2:22,3:22,4:21,5:18,6:18,7:18
//分组名group_name消费topic为TopicTest的进度为:
// 队列queue=0 消费进度23
// 队列 queue=2 消费进度为22 等等…
}
}
}
3. 加载消费者订阅关系 ${user.home}/store/config/subscriptionGroup.json
{
"dataVersion":{
"counter":1,
"timestatmp":1393641744664
},
"group_name":{
"brokerId":0, //0代表这台broker机器为master,若要设为slave值大于0
"consumeBroadcastEnable":true,
"consumeEnable":true,
"consumeFromMinEnable":true,
"groupName":"group_name",
"retryMaxTimes":5,
"retryQueueNums":1,
"whichBrokerWhenConsumeSlowly":1
}
}
}
broker 2. broker的消息存储
Rocketmq的消息的存储是由consume queue和 commitLog 配合完成的
1) consume queue 消息的逻辑队列,相当于字典的目录用来指定消息在消息的真正的物理文件commitLog上的位置, 每个topic下的每个queue都有一个对应的consumequeue文件。 文件地址:${user.home} \\store\\consumequeue\\${topicName}\\${queueId}\\${fileName} consume queue中存储单元是一个20字节定长的数据,是顺序写顺序读 (1) commitLogOffset是指这条消息在commitLog文件实际偏移量 (2) size就是指消息大小 (3) 消息tag的哈希值

ConsumeQueue文件组织:
(1) topic queueId来组织的,比如TopicA配了读写队列0, 1,那么TopicA和Queue=0组成一个ConsumeQueue,TopicA和Queue=1组成一个另一个ConsumeQueue. (2) 按消费端group分组重试队列,如果消费端消费失败,发送到retry消费队列中 (3) 按消费端group分组死信队列,如果消费端重试超过指定次数,发送死信队列 (4) 每个ConsumeQueue可以由多个文件组成无限队列被MapedFileQueue对象管理

2) CommitLog消息存放物理文件,每台broker上的commitLog被本机器所有queue共享不做区分
文件地址:${user.home} \\store\\${commitlog}\\${fileName} 一个消息存储单元长度是不定的,顺序写但是随机读 消息存储结构: = 4 //4个字节代表这个消息的大小 + 4 //四个字节的MAGICCODE = daa320a7 + 4 //消息体BODY CRC 当broker重启recover时会校验 + 4 //queueId 你懂得 + 4 //flag 这个标志值rocketmq不做处理,只存储后透传 + 8 //QUEUEOFFSET这个值是个自增值不是真正的consume queue的偏移量,可以代表这个队列中消息的个数,要通过这个值查找到consume queue中数据,QUEUEOFFSET * 20才是偏移地址 + 8 //PHYSICALOFFSET 代表消息在commitLog中的物理起始地址偏移量 + 4 //SYSFLAG消息标志,指明消息是事物事物状态等等消息特征 + 8 //BORNTIMESTAMP 消息产生端(producer)的时间戳 + 8 //BORNHOST 消息产生端(producer)地址(address:port) + 8 //STORETIMESTAMP 消息在broker存储时间 + 8 //STOREHOSTADDRESS 消息存储到broker的地址(address:port) + 8 //RECONSUMETIMES消息被某个订阅组重新消费了几次(订阅组之间独立计数),因为重试消息发送到了topic名字为%retry%groupName的队列queueId=0的队列中去了 + 8 //Prepared Transaction Offset 表示是prepared状态的事物消息 + 4 + bodyLength // 前4个字节存放消息体大小值, 后bodylength大小空间存储了消息体内容 + 1 + topicLength //一个字节存放topic名称能容大小, 后存放了topic的内容 + 2 + propertiesLength // 2个字节(short)存放属性值大小, 后存放propertiesLength大小的属性数据
3) MapedFile 是PageCache文件封装,操作物理文件在内存中的映射以及将内存数据持久化到物理文件中,代码中写死了要求os系统的页大小为4k, 消息刷盘根据参数(commitLog默认至少刷4页, consumeQueue默认至少刷2页)才刷
以下io对象构建了物理文件映射内存的对象 FileChannel fileChannel = new RandomAccessFile(file,“rw”).getChannel(); MappedByteBuffer mappedByteBuffer=fileChannel.map(READE_WRITE,0,fileSize); 构建mapedFile对象需要两个参数 fileSize: 映射的物理文件的大小 commitLog每个文件的大小默认1G =1024*1024*1024 ConsumeQueue每个文件默认存30W条 = 300000 *CQStoreUnitSize(每条大小) filename: filename文件名称但不仅仅是名称还表示文件记录的初始偏移量, 文件名其实是个long类型的值
4) MapedFileQueue 存储队列,数据定时删除,无限增长。
队列有多个文件(MapedFile)组成,由集合对象List表示升序排列,前面讲到文件名即是消息在此文件的中初始偏移量,排好序后组成了一个连续的消息队
当消息到达broker时,需要获取最新的MapedFile写入数据,调用MapedFileQueue的getLastMapedFile获取,此函数如果集合中一个也没有创建一个,如果最后一个写满了也创建一个新的。
MapedFileQueue在获取getLastMapedFile时,如果需要创建新的MapedFile会计算出下一个MapedFile文件地址,通过预分配服务AllocateMapedFileService异步预创建下一个MapedFile文件,这样下次创建新文件请求就不要等待,因为创建文件特别是一个1G的文件还是有点耗时的,
getMinOffset获取队列消息最少偏移量,即第一个文件的文件起始偏移量
getMaxOffset获取队列目前写到位置偏移量
getCommitWhere刷盘刷到哪里了
5) DefaultMessageStore 消息存储层实现
(1)putMessage 添加消息委托给commitLog.putMessage(msg),主要流程: <1> 从mapedFileQueue获取最新的映射文件 <2>向mapedFile中添加一条消息记录 <3> 构建DispatchRequest对象,添加到分发索引服务DispatchMessageService线程中去 <4>唤醒异步刷盘线程 <5> 向发送方返回结果 (2)DispatchMessageService <1>分发消息位置到ConsumeQueue <2>分发到IndexService建立索引
broker 3. load&recover
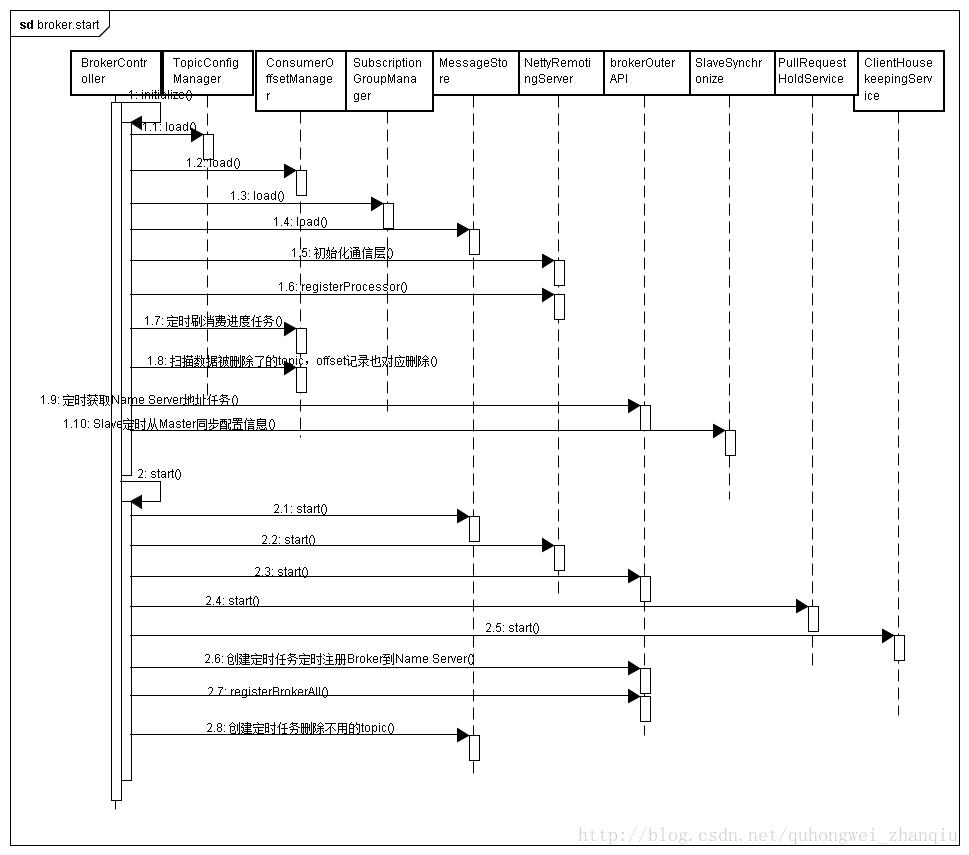
Broker启动的时候需要加载一系列的配置,启动一系列的任务,主要分布在BrokerController 的initialize()和start()方法中
1. 加载topic配置 2. 加载消费进度consumer offset 3. 加载消费者订阅关系consumer subscription 4. 加载本地消息messageStore.load() a) Load 定时进度 b) Load commit log commitLog其实调用存储消费队列mapedFileQueue.load()方法来加载的。 遍历出${user.home} \\store\\${commitlog}目录下所有commitLog文件,按文件名(文件名就是文件的初始偏移量)升序排一下, 每个文件构建一个MapedFile对象, 在MapedFileQueue中用集合list把这些MapedFile文件组成一个逻辑上连续的队列 c) Load consume Queue 遍历${user.home} \\store\\consumequeue下的所有文件夹(每个topic就是一个文件夹) 遍历${user.home} \\store\\consumequeue\\${topic}下的所有文件夹(每个queueId 就是一个文件夹) 遍历${user.home} \\store\\consumequeue\\${topic}\\${queueId}下所有文件,根据topic, queueId, 文件来构建ConsueQueue对象 DefaultMessageStore中存储结构Map<topic,Map<queueId, CosnueQueue>> 每个Consumequeue利用MapedFileQueue把mapedFile组成一个逻辑上连续的队列 d) 加载事物模块 e) 加载存储检查点 加载${user.home} \\store\\checkpoint 这个文件存储了3个long类型的值来记录存储模型最终一致的时间点,这个3个long的值为 physicMsgTimestamp为commitLog最后刷盘的时间 logicMsgTimestamp为consumeQueue最终刷盘的时间 indexMsgTimestamp为索引最终刷盘时间 checkpoint作用是当异常恢复时需要根据checkpoint点来恢复消息 f) 加载索引服务indexService g) recover尝试数据恢复 判断是否是正常恢复,系统启动的启动存储服务(DefaultMessageStore)的时候会创建一个临时文件abort, 当系统正常关闭的时候会把这个文件删掉,这个类似在Linux下打开vi编辑器生成那个临时文件,所有当这个abort文件存在,系统认为是异常恢复

1) 先按照正常流程恢复ConsumeQueue 为什么说先正常恢复,那么异常恢复在哪呢?当broker是异常启动时候,在异常恢复commitLog时会重新构建请到DispatchMessageService服务,来重新生成ConsumeQueue数据,
索引以及事物消息的redolog 什么是恢复ConsumeQueue, 前面不是有步骤load了ConsumeQueue吗,为什么还要恢复? 前面load步骤创建了MapedFile对象建立了文件的内存映射,但是数据是否正确,现在文件写到哪了(wrotePosition),
Flush到了什么位置(committedPosition)?恢复数据来帮我解决这些问题。 每个ConsumeQueue的mapedFiles集合中,从倒数第三个文件开始恢复(为什么只恢复倒数三个文件,也许只是个经验值吧),
因为consumequeue的存储单元是20字节的定长数据,所以是依次分别取了 Offset long类型存储了commitLog的数据偏移量 Size int类型存储了在commitLog上消息大小 tagcode tag的哈希值 目前rocketmq判断存储的consumequeue数据是否有效的方式为判断offset>= 0 && size > 0 如果数据有效读取下20个字节判断是否有效 如果数据无效跳出循环,记录此时有效数据的偏移量processOffset 如果读到文件尾,读取下一个文件 proccessOffset是有效数据的偏移量,获取这个值的作用什么? (1) proccessOffset后面的数据属于脏数据,后面的文件要删除掉 (2) 设置proccessOffset所在文件MapedFile的wrotePosition和commitedPosition值,值为 proccessOffset%mapedFileSize 2) 正常恢复commitLog文件 步骤跟流程恢复Consume Queue 判断消息有效, 根据消息的存储格式读取消息到DispatchRequest对象,获取消息大小值msgSize 大于 0 正常数据 等于-1 文件读取错误 恢复结束 等于0 读到文件末尾 3) 异常数据恢复,OSCRASH或者JVM CRASH或者机器掉电 当${user.home}\\store\\abort文件存在,代表异常恢复 读取${user.home} \\store\\checkpoint获取最终一致的时间点 判断最终一致的点所在的文件是哪个 从最新的mapedFile开始,获取存储的一条消息在broker的生成时间,大于checkpoint时间点的放弃找前一个文件,小于等于checkpoint时间点的说明checkpoint
在此mapedfile文件中 从checkpoint所在mapedFile开始恢复数据,它的整体过程跟正常恢复commitlog类似,最重要的区别在于 (1)读取消息后派送到分发消息服务DispatchMessageService中,来重建ConsumeQueue以及索引 (2)根据恢复的物理offset,清除ConsumeQueue多余的数据 4) 恢复TopicQueueTable=Map<topic-queueid,offset> (1) 恢复写入消息时,消费记录队列的offset (2) 恢复每个队列的最小offset 5. 初始化通信层 6. 初始化线程池 7. 注册broker端处理器用来接收client请求后选择处理器处理 8. 启动每天凌晨00:00:00统计消费量任务 9. 启动定时刷消费进度任务 10. 启动扫描数据被删除了的topic,offset记录也对应删除任务 11. 如果namesrv地址不是指定的,而是从静态服务器取的,启动定时向静态服务器获取namesrv地址的任务 12. 如果broker是master,启动任务打印slave落后master没有同步的bytes 如果broker是slave,启动任务定时到mastser同步配置信息
broker 4. HA&master slave
在broker启动的时候BrokerController如果是slave,配置了master地址更新,没有配置所有broker会想namesrv注册,从namesrv获取haServerAddr,然后更新到HAClient
当HAClient的MasterAddress不为空的时候(因为broker master和slave都构建了HAClient)会主动连接master获取SocketChannel Master监听Slave请求的端口,默认为服务端口+1
接收slave上传的offset long类型 int pos = this.byteBufferRead.position() -(this.byteBufferRead.position() % 8)
//没有理解意图
long readOffset =this.byteBufferRead.getLong(pos - 8); this.processPostion = pos;
主从复制从哪里开始复制:如果请求时0 ,从最后一个文件开始复制
Slave启动的时候brokerController开启定时任务定时拷贝master的配置信息
SlaveSynchronize类代表slave从master同步信息(非消息)
syncTopicConfig 同步topic的配置信息
syncConsumerOffset 同步消费进度
syncDelayOffset 同步定时进度
syncSubcriptionGroupConfig 同步订阅组配7F6E
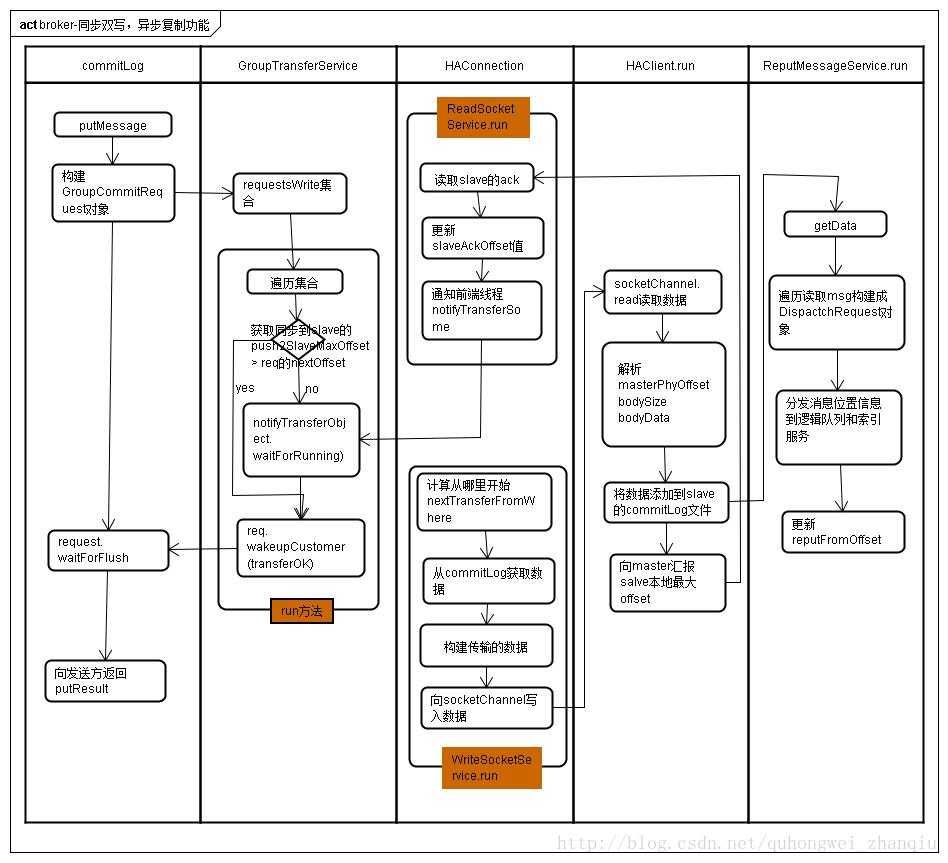
HaService类实现了HA服务,负责同步双写,异步复制功能, 这个类master和slave的broker都会实例化,
Master通过AcceptSocketService监听slave的连接,每个masterslave连接都会构建一个HAConnection对象搭建他们之间的桥梁,对于一个master多slave部署结构的会有多个HAConnection实例,
Master构建HAConnection时会构建向slave写入数据服务线程对象WriteSocketService对象和读取Slave反馈服务线程对象ReadSocketService
WriteSocketService
向slave同步commitLog数据线程,
slaveRequestOffset是每次slave同步完数据都会向master发送一个ack表示下次同步的数据的offset。
如果slave是第一次启动的话slaveRequestOffset=0, master会从最近那个commitLog文件开始同步。(如果要把master上的所有commitLog文件同步到slave的话, 把masterOffset值赋为minOffset)
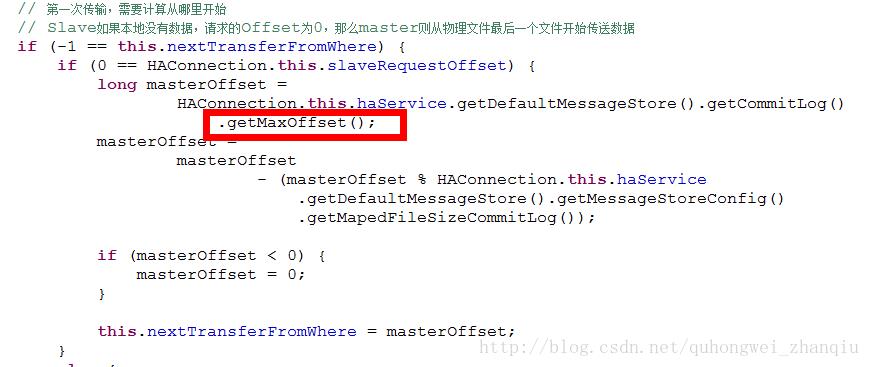
向socket写入同步数据: 传输数据协议<Phy Offset> <Body Size> <Body Data>
ReadSocketService:
4.2 ReadSocketService
读取slave通过HAClient向master返回同步commitLog的物理偏移量phyOffset值
通知前端线程,如果是同步复制的话通知是否复制成功
Slave 通过HAClient建立与master的连接,
来定时汇报slave最大物理offset,默认5秒汇报一次也代表了跟master之间的心跳检测
读取master向slave写入commitlog的数据, master向slave写入数据的格式是

Slave初始化DefaultMessageStore时候会构建ReputMessageService服务线程并在启动存储服务的start方法中被启动
ReputMessageService的作用是slave从物理队列(由commitlog文件构成的MapedFileQueue)加载数据,并分发到各个逻辑队列
HA同步复制, 当msg写入master的commitlog文件后,判断maser的角色如果是同步双写SYNC_MASTER, 等待master同步到slave在返回结果
3 HA异步复制
broker 6.索引服务
1索引结构
IndexFile 存储具体消息索引的文件,文件的内容结构如图:
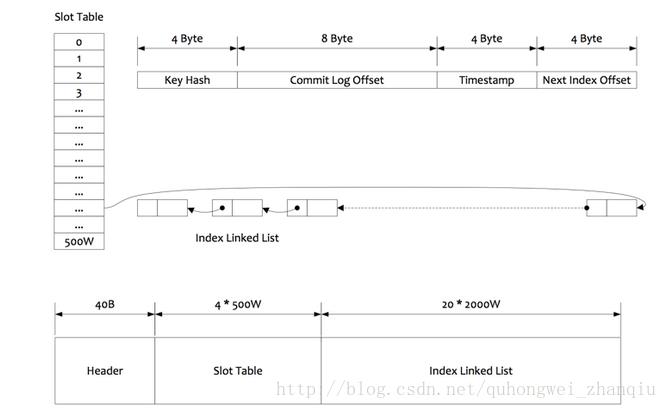
索引文件由索引文件头IndexHeader, 槽位Slot和消息的索引内容三部分构成
IndexHeader:索引文件头信息40个字节的数据组成

beginTimestamp 8位long类型,索引文件构建第一个索引的消息落在broker的时间
endTimestamp 8位long类型,索引文件构建最后一个索引消息落broker时间
beginPhyOffset 8位long类型,索引文件构建第一个索引的消息commitLog偏移量
endPhyOffset 8位long类型,索引文件构建最后一个索引消息commitLog偏移量
hashSlotCount 4位int类型,构建索引占用的槽位数(这个值貌似没有具体作用)
indexCount 4位int类型,索引文件中构建的索引个数
槽位slot, 默认每个文件配置的slot个数为500万个,每个slot是4位的int类型数据
计算消息的对应的slotPos=Math.abs(keyHash)%hashSlotNum
消息在IndexFile中的偏移量absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos *HASH_SLOT_SIZE
Slot存储的值为消息个数索引
消息的索引内容是20位定长内容的数据

4位int值, 存储的是key的hash值
8位long值 存储的是消息在commitlog的物理偏移量phyOffset
4位int值 存储了当前消息跟索引文件中第一个消息在broker落地的时间差
4位int值 如果存在hash冲突,存储的是上一个消息的索引地址
2. 索引服务IndexService线程
1. 索引配置:hashSlotNum哈希槽位个数、indexNum存储索引的最大个数、storePath索引文件indexFile存储的路径 2. Load broker启动的时候加载本地IndexFile, 如果是异常启动删除之后storeCheckPoint文件,因为commitLog根据storeCheckPoint会重建之后的索引文件, 3. Run方法,任务从阻塞队列中获取请求构建索引 4. queryOffset 根据topic key 时间跨度来查询消息 倒叙遍历所有索引文件 每一个indexfile存储了第一个消息和最后一个消息的存储时间,根据传入时间范围来判断索引是否落在此索引文件
3. 构建索引服务
分发消息索引服务将消息位置分发到ConsumeQueue中后,加入IndexService的LinkedBlockingQueue队列中,IndexService通过任务向队列中获取请求来构建索引 剔除commitType或者rollbackType消息,因为这两种消息都有对应的preparedType的消息 构建索引key(topic + "#" + key) 根据key的hashcode计算槽位,即跟槽位最大值取余数 计算槽位在indexfile的具体偏移量位置 根据槽位偏移量获取存储的上一个索引 计算消息跟文件头存储开始时间的时间差 根据消息头记录的存储消息个数计算消息索引存储的集体偏移量位置 写入真正的索引,内容参考上面索引内容格式 将槽位中的更新为此消息索引 更新索引头文件信息

4. Broker与client(comsumer ,producer)之间的心跳,
一:Broker接收client心跳ClientManageProcessor处理client的心跳请求 1. 构建ClientChannelInfo对象 1) 持有channel对象,表示与客户端的连接通道 2) ClientID表示客户端 ….. 2. 每次心跳会更新ClientChannelInfo的时间戳,来表示client还活着 3. 注册或者更新consumer的订阅关系(是以group为单位来组织的, group下可能有多个订阅关系) 4. 注册producer,其实就是发送producer的group(这个在事物消息中才有点作用) 二:ClientHouseKeepingService线程定时清除不活动的连接 1) ProducerManager.scanNotActiveChannel 默认两分钟producer没有发送心跳清除 2) ConsumerManager.scanNotActiveChannel 默认两份中Consumer没有发送心跳清除
5. Broker与namesrv之间的心跳
1) namesrv接收borker心跳DefaultRequestProcessor的REGISTER_BROKE事件处理, (1) 注册broker的topic信息 (2) 构建或者更新BrokerLiveInfo的时间戳 NamesrvController初始化时启动线程定时调用RouteInfoManger的scanNotActiveBroker方法来定时不活动的broker(默认两分钟没有向namesrv发送心跳更新时间戳的)
以上是关于RocketMQ原理解析-Broker的主要内容,如果未能解决你的问题,请参考以下文章