windows定时执行百度新闻爬虫
Posted 不秩稚童
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了windows定时执行百度新闻爬虫相关的知识,希望对你有一定的参考价值。
想要做个新闻文本识别分类的项目,就先写了个爬取百度新闻的爬虫。
环境:win7 32 bit python3.4 若干第三方库
可以实现的功能:定期按照百度新闻的分类抓取新闻的标题,所属类别及文本内容,并自动存入数据库(mysql),同时发邮件到自己邮箱提醒。
缺陷:因新闻来源不同,网页编码不同,会出现少量的乱码现象;存入数据库未添加自动去重功能(自己手动去重其实也并不难,所以没去研究这个)
STEP1: creat_dbtable.py链接数据库创建表(也可直接通过操作MySQL)
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 6 23:31:33 2016
@author: Administrator
"""
#数据库创建操作
import MySQLdb
#打开数据库链接
db = MySQLdb.Connect(host="localhost",user="root",passwd=\'你的密码\',db="test",use_unicode=True, charset="utf8")
cursor = db.cursor()
#如果数据已经存在,使用excute()方法删除表
cursor.execute("DROP TABLE IF EXISTS news")
#创建数据表 SQL语句
sql = """CREATE TABLE news(
class VARCHAR(10) NOT NULL,
title VARCHAR(100),
text VARCHAR(15000)
)"""
cursor.execute(sql)
#关闭数据库连接
db.close()
在MySQL看到表已经生成:

step2:为了了解每次的抓取情况,写一个send_email.py来实现发送邮件的功能,这个文件在spider主文件里面来调用。
NOTE:这个往自己的邮箱发送邮件要在相应邮箱开启服务获取一个password才可以,这个网上教程也比较多,之后有空会补充。
#coding:utf-8
from email.header import Header
from email.mime.text import MIMEText
from email.utils import parseaddr, formataddr
import smtplib
def _format_addr(s):
name, addr = parseaddr(s)
return formataddr((Header(name,\'utf-8\').encode(), addr))
def send_ms(T):
from_addr = "1021550072@qq.com"
password = \'your-password\'
to_addr = \'1021550072@qq.com\'
smtp_server = \'smtp.qq.com\'
msg = MIMEText(T, \'plain\', \'utf-8\')
msg[\'From\'] = _format_addr(\'Anyone\')
msg[\'To\'] = _format_addr(\'Echo\')
msg[\'Subject\'] = Header(\'The New Report\', \'utf-8\').encode()
server = smtplib.SMTP_SSL(smtp_server, 465, timeout=10)
server.set_debuglevel(0)
server.login(from_addr,password)
server.sendmail(from_addr, [to_addr], msg.as_string())
server.quit()
# send_ms(T)
step3:创建spider.py文件,实现具体功能。
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 6 21:24:27 2016
@author: Administrator
"""
import re
import time
import requests
import numpy as np
import send_email
from bs4 import BeautifulSoup
from collections import Counter
import MySQLdb
start = time.time()
#打开数据库链接
db = MySQLdb.Connect(host="localhost",user="root",passwd=\'password\',db="test",use_unicode=True, charset="utf8")
cursor = db.cursor()
headers = {\'User-Agent\':"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/53.0.2785.143 Safari/537.36"}
# 获取首页数据head_data
def get_head_data():
head_url = \'http://internet.baidu.com/\'
data = requests.get(head_url,headers=headers)
data.encoding = \'gbk\'
# print(data.status_code)
head_data = data.text
return head_data
# 获取各新闻分类的title及href
def get_class(head_data):
title_href = {}
pa = re.compile(r\'<a href="(http.*?.com/).*?>.*?(\\w+)</a></li>\')
ma = re.findall(pa,head_data)[1:-7]
ma = list(set(ma))[:-1]
# print(len(ma))
for i in range(len(ma)):
key = ma[i][1]
value = ma[i][0]
title_href[key] = value
# print(title_href)
return title_href
# 对于每个分类提取标题信息class_data
def get_class_data(class_url):
class_data = requests.get(class_url, headers=headers)
pa = re.compile(r\'charset=(.*?)">\')
charset = re.findall(pa,class_data.text)[0]
class_data.encoding = charset
# class_data.encoding = \'gbk\'
class_data =class_data.text
soup = BeautifulSoup(class_data, \'lxml\')
data = soup.findAll(\'a\',{\'target\':\'_blank\'})
class_data = {}
for i in range(len(data)):
title = data[i].get_text()
href = data[i].get(\'href\')
if len(title) > 10:
if not \'下载\' in title:
class_data[title] = href
return class_data
# 获取每条新闻的具体文本内容,粗略抓取
def get_news_text(href):
try:
data = requests.get(href,headers=headers)
# data.encoding = \'gbk\'
pa = re.compile(r\'charset=(.*?)">\')
charset = re.findall(pa,data.text)[0]
data.encoding = charset
data = BeautifulSoup(data.text,\'lxml\').get_text()
text = re.sub("[A-Za-z0-9\\[\\`\\~\\!\\@\\#\\$\\ \\^\\"\\-\\+\\_\\\\&\\\\n\\\\t\\*\\(\\)\\=\\|\\{\\}\\\'\\:\\;\\\'\\,\\[\\]\\.\\<\\>\\/\\?\\~\\!\\@\\#\\\\\\&\\*\\%]", "", data)
except:
# print(\'get New Text fail...\')
text = None
pass
return text
head_data = get_head_data()
title_href = get_class(head_data)
count = 0
for class_title,class_href in dict(title_href).items():
print(class_title)
# try:
class_data = get_class_data(class_href)
# except:
# print(\'get Class data fail...\')
# pass
for news_title, news_url in class_data.items():
# print(news_title)
text = get_news_text(news_url)
sql = """INSERT INTO news\\
SET class=%s, title=%s, text=%s"""
try:
cursor.execute(sql,(class_title,news_title,text))
db.commit()
count += 1
except:
# print(\'Save fail...\')
pass
db.close()
end = time.time()
total_time = end - start
T1 = \'本次抓取耗时%s\'%str(total_time)
T2 = \' & 本次共抓取%s条新闻\'%str(count)
T = T1+T2
# print(t1,t2)
send_email.send_ms(T)
数据库存储情况:

邮件详情:
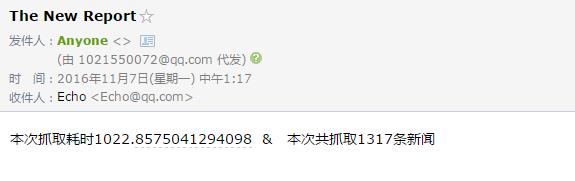
REMARK:关于windows定时任务,请参考这篇教程。
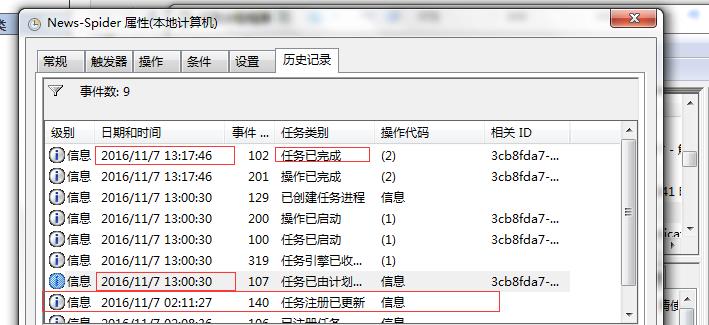
这是我自己计划任务的设置和运行情况

以上是关于windows定时执行百度新闻爬虫的主要内容,如果未能解决你的问题,请参考以下文章