TopK-微博今日热门话题
Posted futurehau
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TopK-微博今日热门话题相关的知识,希望对你有一定的参考价值。
大纲
- TopK on single node
- TopK on multiple nodes
- Realtime topK with low QPS
- Realtime topK with high QPS
- Approx TopK
- MapReduce
一、TopK on single node
从几个关于TopK的算法引出 TopK 系列问题
1. 给你一个无序整数数组,要求求出TopK (Order By Value)
题目地址:http://www.lintcode.com/zh-cn/problem/top-k-largest-numbers/
数据结构:优先队列(minHeap) (当然如果不是数据流的话,使用QuickSelect效率更高)
时间复杂度:O(nlogk)
空间复杂度: O(k)
2. 给你一个微博话题组成的列表,要求求出TopK(Order by Frequency)
题目地址:http://www.lintcode.com/zh-cn/problem/top-k-frequent-words/
分析:这里需要按照String出现的频数来求解TopK,自然不能像刚刚一样直接使用一个PriorityQueue来实现。但基本原理还是一致的。
使用一个HashMap,HashMap<String, Integer> 表明某个String 出现的频数。然后在PQ中存储的是我们自定义的一个数据结构Pair, Pair包含String 和 频数两个变量,自定义一个Comparator按照频数升序排序就可以了。
数据结构:HashMap PriorityQueue
时间复杂度:O(n + nlog(k)) -> O(nlogk)
空间复杂度: O(|n| + k) 其中 |n|表示unique string数目
二、TopK on multiple nodes
1. 现在假设这样一个场景:给你一组10T的文件,文件内容是10million用户当天的搜索记录,求微博今日话题热搜?
这个场景就不能再使用single node 因为一方面文件太大,单机无法处理,另一方面处理速度太慢
这时候就要采用 分&和 的思想
OverView 如下:
- 分成小文件
- 分发给不同的机器处理
- 每个机器分别获得TopK
- 组合这些TopK获得总的TopK
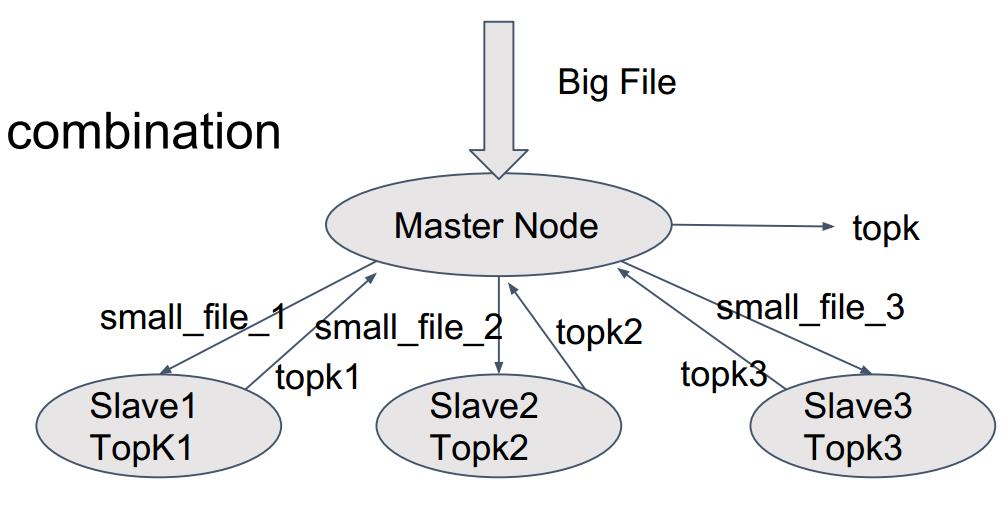
注意这里一个比较关键的地方:怎么来拆分文件呢?
一种思路是按照文件的先后顺序来拆分,这是有问题的,因为假如某个String比较分散,而总次数是能够进入TopK的,但是在SlaveNode上,这个slaveNode可能并没有入选TopK,这就导致了错误。
所以,我们这里采用 Divide by hash value. 这样相同的String都被分给了同一个slaveNode处理。
2. 假设场景二: 有N台机器, 每台机器各自存储单词文件,求所有单词出现频率的TopK
同样的道理,假如直接求各个单机的TopK在合并的话也是会出现问题的。
这里需要ReHash!
三、 Realtime TopK with Low QPS
之前讨论的情况都是 offline 的,那么实时数据又怎么样呢?
想法一:
步骤:新数据来,存储到磁盘,服务器请求计算TopK的时候再运行算法求解。
缺点:重复计算、运行速度慢。
想法二:
新数据来,把它写到hashmap,hashmap更新的时候同时更新PQ,获取TopK。
缺点:OOM 节点宕机或者停电的时候数据丢失
想法三:
不使用hashMap,取代他的是把数据存储在database中。
以上是使用database来取代hashmap的分析,那么PQ有没有什么需要处理的呢?
当然是需要的,新加入数据之后,需要删除PQ中已经存储了的数据。而PQ是不支持高效删除节点操作的,所以这里使用treeMap来代替PQ。
四、 Realtime TopK with High QPS
QPS过高的话,数据库相应存在high latency
解决办法也是 分&和

各个节点get TopK 然后再合并。
可能带来这样一个问题:假如某个key太热了,导致某个节点write key 负荷太重怎么办?这也会带来高延迟
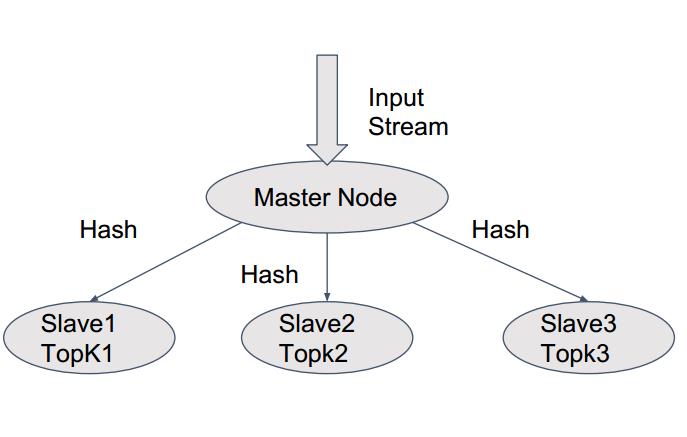
流程图:

由图可知,当某个key过热的话,这个节点就很频繁的在写数据,导致treeMap被锁。high latency
解决办法是就是:Cache
这其实是在准确性和延迟之间找一个平衡。

五、Approx TopK Algorithm
准确性和使用空间的TradeOff
如果我们把所有词都存入disk,那么那些那些低频词将浪费较多的空间。
接下来介绍的这种算法可以自定义使用的空间大小,并且时间复杂度为O(logK)
基本步骤:
新单词来的时候,更新hashMap
更新treeMap
这和之前是一样的,区别之处在于:
HashMap:
key = word_hashvalue
Value = frequency
但是这是会带来问题的,分析如下:
1、假如好多低频词都被hash到同一个value,那么这个value就很可能被选中了。
2、假如后来的低频词hash到高频的那个value,误把这个低频词选中。
解决办法:bloom filter 布隆过滤器
Bloom Filter:
HashMap 拥有三个不同的hash函数,取hash到的最小的count。这样一来,低频词虽然有可能某一个hash hash到和高频词的那个value,但三个hash取小的counter 还是有很大作用来处理这个问题的。
六、Use Mapreduce to solve it
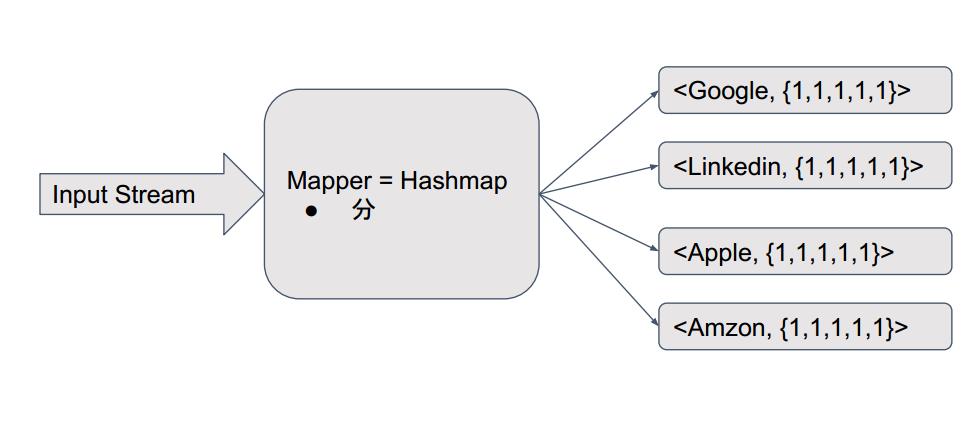
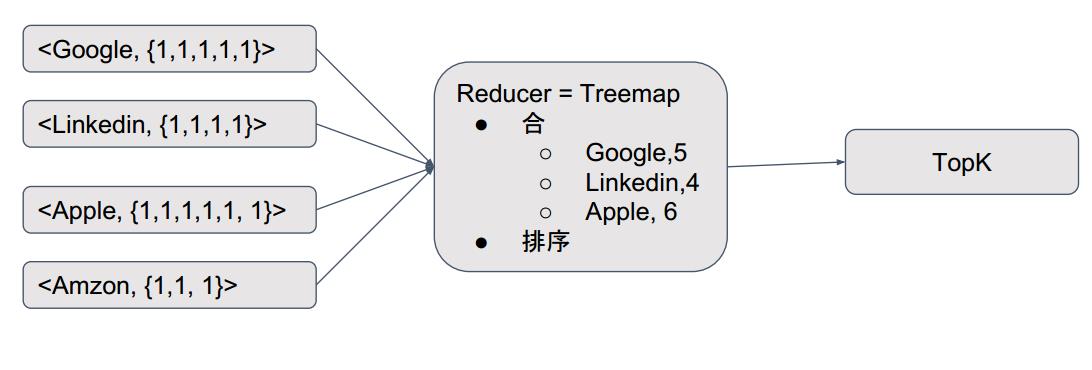
以上是关于TopK-微博今日热门话题的主要内容,如果未能解决你的问题,请参考以下文章