HashMap的数据结构
Posted huaxun66
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap的数据结构相关的知识,希望对你有一定的参考价值。
HashMap的数据结构
数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组”,如图:
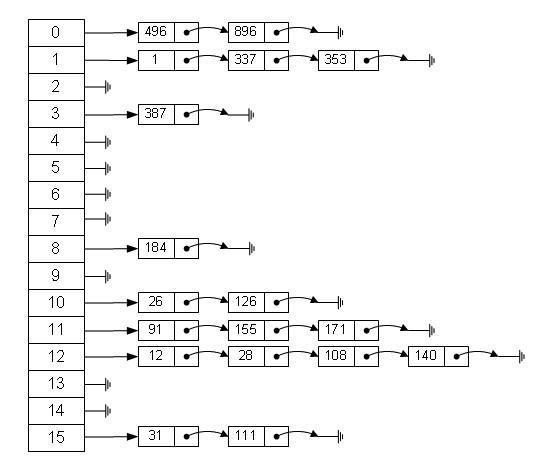
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是用一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
HashMap的存取实现
既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现:
//存储时:
int hash = key.hashCode();// 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
//取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];到这里我们已经轻松的理解了HashMap通过键值对实现存取的基本原理。
疑问:如果两个key通过hash%Entry[].length得到的index相同(也称为hash冲突),会不会有覆盖的危险?
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
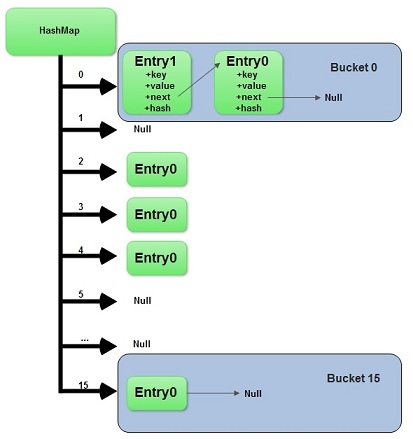
注:解决hash冲突的办法:
- 开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
- 再哈希法
- 链地址法
- 建立一个公共溢出区
Java中HashMap的解决办法就是采用的链地址法。
HashMap的优化
当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个因素(也称为负载极限),随着map的size越来越大,Entry[]会以一定的规则加长长度。
HashMap默认的“负载极限”为0.75,表明该hash表3/4已经被填满时,hash表会发生rehashing。0.75其实是事件和空间的一个折中:较高的“负载极限”可以降低hash表所占的内存空间,但会增加查询数据的开销,而查询是最频繁的操作;而较低的“负载极限”会增加查询的性能,但会增加hash表所占的内存空间。
实现自己的HashMap
已经了解了HashMap的实现原理,下面我们自己来实现一个简单的HashMap。
Entry.java
public class Entry<K,V>{
final K key;
V value;
Entry<K,V> next;//下一个结点
//构造函数
public Entry(K k, V v, Entry<K,V> n) {
key = k;
value = v;
next = n;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Entry))
return false;
Entry e = (Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^ (value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
}MyHashMap.java
public class MyHashMap<K, V> {
private Entry[] table;//Entry数组表
static final int DEFAULT_INITIAL_CAPACITY = 16;//默认数组长度
private int size;
// 构造函数
public MyHashMap() {
table = new Entry[DEFAULT_INITIAL_CAPACITY];
size = DEFAULT_INITIAL_CAPACITY;
}
//获取数组长度
public int getSize() {
return size;
}
// 求index
static int indexFor(int h, int length) {
return h % (length - 1);
}
//获取元素
public V get(Object key) {
if (key == null)
return null;
int hash = key.hashCode();// key的哈希值
int index = indexFor(hash, table.length);// 求key在数组中的下标
for (Entry<K, V> e = table[index]; e != null; e = e.next) {
Object k = e.key;
if (e.key.hashCode() == hash && (k == key || key.equals(k)))
return e.value;
}
return null;
}
// 添加元素
public V put(K key, V value) {
if (key == null)
return null;
int hash = key.hashCode();
int index = indexFor(hash, table.length);
// 如果添加的key已经存在,那么只需要修改value值即可
for (Entry<K, V> e = table[index]; e != null; e = e.next) {
Object k = e.key;
if (e.key.hashCode() == hash && (k == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
return oldValue;// 原来的value值
}
}
// 如果key值不存在,那么需要添加
Entry<K, V> e = table[index];// 获取当前数组中的e
table[index] = new Entry<K, V>(key, value, e);// 新建一个Entry,并将其指向原先的e
return null;
}
}使用自定义HashMap:
public class MainActivity extends AppCompatActivity {
private MyHashMap<Integer, Integer> map1 = new MyHashMap<Integer, Integer>();
private MyHashMap<String, String> map2 = new MyHashMap<String, String>();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
map1.put(1, 2000);
map1.put(48, 3000);
map1.put(99, 4000);
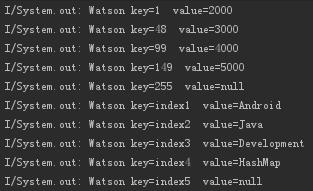
map1.put(149, 5000);
showlog("key=1 value="+map1.get(1));
showlog("key=48 value="+map1.get(48));
showlog("key=99 value="+map1.get(99));
showlog("key=149 value="+map1.get(149));
showlog("key=255 value="+map1.get(255)); //不存在这个Key
map2.put("index1", "android");
map2.put("index2", "Java");
map2.put("index3", "Development");
map2.put("index4", "HashMap");
showlog("key=index1 value="+map2.get("index1"));
showlog("key=index2 value="+map2.get("index2"));
showlog("key=index3 value="+map2.get("index3"));
showlog("key=index4 value="+map2.get("index4"));
showlog("key=index5 value="+map2.get("index5")); //不存在这个Key
}
private void showlog(String info) {
System.out.print("Watson "+info+"/n");
}
}运行程序,打印的Log信息如下:
HashMap、Hashtable、SynchronizedMap和ConcurrentHashMap关系
HashMap允许使用null作为key或者value,并且HashMap不是线程安全的,除了这两点外,HashMap与Hashtable大致相同。
HashMap不是线程安全的;Hashtable线程安全,但效率低,因为是Hashtable是使用synchronized的,所有线程竞争同一把锁;SynchronizedMap线程安全,其实是保持外部同步来实现的,效率也很低;而ConcurrentHashMap不仅线程安全而且效率高,因为它包含一个segment数组,将数据分段存储,给每一段数据配一把锁,也就是所谓的锁分段技术。
如何线程安全的使用HashMap,无非就是以下三种方式:
- Hashtable
- Synchronized Map
- ConcurrentHashMap
HashMap底层实现
当多个线程同时(严格来说不能称为同时,因为CPU每次只能允许一个线程获取资源,只不过时间上非常短,CPU运行速度很快,所以理解为同时)修改哈希映射,那么哈希映射(就是哈希表)的最终结果是不能确定的,这只能看CPU心情了。
下面从源码的角度分析一下,为什么HashMap不是线程安全的:
public V put(K key, V value) {
//这里省略了对重复键值的处理代码
modCount++;
addEntry(hash, key, value, i);
return null;
}那么问题应该处在addEntry()上,下面来看看其源码:
void addEntry(int hash, K key, V value, int bucketIndex) {
//如果达到Map的阈值,那么就扩大哈希表的容量
if ((size >= threshold) && (null != table[bucketIndex])) {
//扩容
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//创建Entry键值对,此处省略这部分代码
}(1)假设有线程A和线程B都调用addEntry()方法,两个put的key发生了碰撞(hash值一样),线程A和B会得到当前哈希表位置的头结点(就是上面链地址法的第一个元素),并修改该位置的头结点,如果是线程A先获取头结点,那么B的操作就会覆盖线程A的操作,所以会有问题。
下面再看看resize方法的源码:
void resize(int newCapacity) {
//此处省略如果达到阈值扩容为原来两倍的过程代码
Entry[] newTable = new Entry[newCapacity];
//把当前的哈希表转移到新的扩容后的哈希表中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}(2)如果有多个线程执行put方法,并调用resize方法,这样就会发生多个线程同时对Entry数组进行扩容,都在重新计算元素位置以及复制数据,但是最终只有一个线程扩容后的数组会赋给table,也就是说其他线程的都会丢失,并且各自线程put的数据也丢失。就会出现多种情况,在转移的过程中丢失数据,或者扩容失败,都有可能,所以从源码的角度分析这也是线程不安全的。
HashMap测试代码:
HashMap<Integer, String> hashMap = new HashMap<Integer, String>();
for (int i = 0; i < 40; i++) {
hashMap.put(i, String.valueOf(i));
}
Set<Entry<Integer,String>> keySets = hashMap.entrySet();
final Iterator<Entry<Integer, String>> keySetsIterator = keySets.iterator();
Thread t1 = new Thread(){
public void run(){
try {
while(keySetsIterator.hasNext()){
Entry<Integer,String> entrys = (Entry<Integer, String>) keySetsIterator.next();
System.out.println(entrys.getValue());
if(entrys.getValue().equals("1")){
System.out.println(entrys.getValue());
hashMap.remove(1);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
};
Thread t2 = new Thread(){
public void run(){
try {
while(keySetsIterator.hasNext()){
Entry<Integer,String> entrys = (Entry<Integer, String>) keySetsIterator.next();
System.out.println(entrys.getValue());
if(entrys.getValue().equals("1")){
System.out.println(entrys.getValue());
hashMap.remove(1);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
};
t1.start();
t2.start();这段代码启动了两个线程并发修改HashMap的映射关系,所以会抛出两个ConcurrentModificationException异常,通过这段测试代码在此证明了HashMap的非线程安全。
SynchronizedMap的底层实现
要解决HashMap的上面问题,官方的参考方案是保持外部同步,什么意思?看下面的代码就知道了:
Map m = Collections.synchronizedMap(new HashMap(...));源码实现:
//synchronizedMap方法
public static Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<>(m);
}//SynchronizedMap类
private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K,V> m; //Backing Map
final Object mutex; //Object on which to synchronize
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
mutex = this;
}
SynchronizedMap(Map<K,V> m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
public int size() {
synchronized (mutex) {
return m.size();
}
}
public boolean isEmpty() {
synchronized (mutex) {
return m.isEmpty();
}
}
public boolean containsKey(Object key) {
synchronized (mutex) {
return m.containsKey(key);
}
}
public boolean containsValue(Object value) {
synchronized (mutex) {
return m.containsValue(value);
}
}
public V get(Object key) {
synchronized (mutex) {
return m.get(key);
}
}
public V put(K key, V value) {
synchronized (mutex) {
return m.put(key, value);
}
}
public V remove(Object key) {
synchronized (mutex) {
return m.remove(key);
}
}
...
}从源码中可以看出调用synchronizedMap()方法后会返回一个SynchronizedMap类的对象,而在SynchronizedMap类中使用了Synchronized同步关键字来保证对Map的操作是线程安全的。
但使用上面的方法创建HashMap的时候,当有多个线程并发访问哈希表的情况下,会抛出异常,所以并发修改会失败。比如下面这段代码:
Map<Integer, String> collectionSynMap = Collections.synchronizedMap(new HashMap<Integer, String>());
for (int i = 0; i < 20; i++) {
collectionSynMap.put(i, String.valueOf(i));
}
Set<Entry<Integer,String>> keySets = collectionSynMap.entrySet();
Iterator<Entry<Integer, String>> keySetsIterator = keySets.iterator();
try {
while(keySetsIterator.hasNext()){
Entry<Integer,String> entrys = (Entry<Integer, String>) keySetsIterator.next();
System.out.println(entrys.getValue());
if(entrys.getValue().equals("1")){
System.out.println(entrys.getValue());
collectionSynMap.remove(1);
//keySetsIterator.remove();
}
}
} catch (Exception e) {
e.printStackTrace();
}就会抛出ConcurrentModificationException异常,因为在使用迭代器遍历的时候修改映射结构,但是使用代码中注释掉的删除是不会抛出异常的。
Hashtable的底层实现
Hashtable是线程安全的,那么Hashtable是如何实现线程安全的呢?有了上面的介绍,我们直接从源码中分析其线程安全性:
public synchronized V put(K key, V value) {
// 保证value值不为空,此处省略其代码
..
// 保证key是不重复的,此处省略其代码
..
//查过阈值则扩容,此处省略
// Creates the new entry.
Entry<K,V> e = tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
return null;
}通过源码可以很明显看到其put方法使用synchronized关键字,在线程中这是实现线程安全的一种方式,所以Hashtable是线程安全的。
当一个线程访问HashTable的同步方法时,其他线程如果也要访问同步方法,会被阻塞住。举个例子,当一个线程使用put方法时,另一个线程不但不可以使用put方法,连get方法都不可以,好霸道啊!!!so~~,效率很低,现在基本不会选择它了。
Hashtable的测试案例:
下面使用一段测试代码验证Hashtable的线程安全:
Hashtable<Integer, String> hashTable = new Hashtable<Integer, String>();
final Hashtable<Integer, String> hashTable_back = hashTable;
Thread t3 = new Thread(){
public void run(){
for (int i = 0; i < 20; i++) {
hashTable_back.put(i, String.valueOf(i));
}
}
};
Thread t4 = new Thread(){
public void run(){
for (int i = 20; i < 40; i++) {
hashTable_back.put(i, String.valueOf(i));
}
}
};
t3.start();
t4.start();
//放完数据后,从map中取出数据,如果map是线程安全的,那么取出的entry应该和放进去的一一对应
new Handler().postDelayed(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 20; i++) {
showlog(i + "=" + hashTable_back.get(i));
}
}
}, 1000);最后得到的输出结果是这样的:
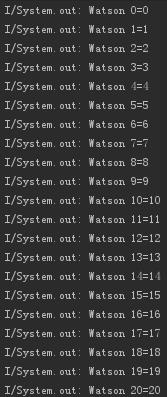
OK,再次说明Hashtable是线程安全的。
ConcurrentHashMap的底层实现
ConcurrentHashMap支持完全并发的对哈希表的操作,ConcurrentHashMap遵从了和Hashtable一样的规范,这里指的是线程安全的规范,但是其底层的实现与Hashtable并不一致。ConcurrentHashMap底层采用的锁机制,执行put方法的线程会获得锁,只有当此线程的put方法执行结束后才会释放锁,根据多线程的知识,获得锁的线程会通知其他试图操作put方法的线程,并通知其他线程出于等待状态,直到释放锁后,其他线程才会去重新竞争锁。这一点保证了ConcurrentHashMap的线程安全。
ConcurrentHashMap实际上是Hashtable的升级版,除了具备线程安全外还增加了迭代器快速失败行为的异常处理,也就是说,通过ConcurrentHashMap对Iterator迭代器结构的修改不会抛出异常,而Hashtable会抛出异常,因而就Hashtable来说,如果迭代器修改了映射结构,那么遍历的结果是不确定的,而ConcurrentHashmap支持之允许一个线程对迭代器的映射结构进行修改。
那么我们接着从源码的角度分析ConcurrentHashMap是如何实现线程安全的:
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) //in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}ConcurrentHashMap把要放入的数据分成了多段数据,然后对每段的put操作进行加锁,下面看一下ensureSegment方法:
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}这段代码的作用就是根据给定的索引,返回某个具体的Segment,然后根据返回的Segment(块)加锁执行put方法。
再看s.put()方法:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
//此处省略详细的处理过程
}
} finally {
unlock();
}
return oldValue;
}在上面的源码中出现了Segment s,我们来看看它何方神圣:每次执行ConcurrentHashMap的put方法都是调用s.put()方法的,而Segments对象是一个继承了ReentrantLock锁对象的子类,那么剩下的就很清晰了,每一个Segments都有一个锁,只有执行完上面try语句块中的代码才会释放锁,从而保证了多线程并发访问的安全性。
下面来看看ConcurrentHashMap的get方法:
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && (tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}get操作会通过key找到哈希表的哈希值,根据哈希值定位到某个Segment,然后再从Segment中返回value。
ConcurrentHashMap的测试案例
下面仍然通过一段测试程序验证ConcurrentHashMap的线程安全:
ConcurrentHashMap<Integer, String> concurrentHashMap = new ConcurrentHashMap<Integer, String>();
final ConcurrentHashMap<Integer, String> concurrentHashMap_back = concurrentHashMap;
Thread t5 = new Thread(){
public void run(){
for (int i = 0; i < 20; i++) {
concurrentHashMap_back.put(i, String.valueOf(i));
}
}
};
Thread t6 = new Thread(){
public void run(){
for (int i = 20; i < 40; i++) {
concurrentHashMap_back.put(i, String.valueOf(i));
}
}
};
t5.start();
t6.start();
//放完数据后,从map中取出数据,如果map是线程安全的,那么取出的entry应该和放进去的一一对应
new Handler().postDelayed(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 20; i++) {
showlog(i + "=" + concurrentHashMap_back.get(i));
}
}
}, 1000);最后,控制台输出的结果如下:
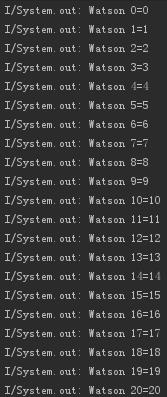
说了那么多,针对Map子类的安全性可以总结如下几点:
- HashMap采用链地址法解决哈希冲突,多线程访问哈希表的位置并修改映射关系的时候,后执行的线程会覆盖先执行线程的修改,所以不是线程安全的。
- Hashtable采用synchronized关键字解决了并发访问的安全性问题但是效率较低,所有线程竞争同一把锁。
- SynchronizedMap线程安全,其实是保持外部同步来实现的,效率也很低。
- ConcurrentHashMap使用了线程锁分段技术,它包含一个segment数组,将数据分段存储,给每一段数据配一把锁,每次访问只允许一个线程修改哈希表的映射关系,所以是线程安全的而且效率高。
以上是关于HashMap的数据结构的主要内容,如果未能解决你的问题,请参考以下文章