数据结构 笔记 part3 (字典树 && 扫描线)
Posted 毛线刷题笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构 笔记 part3 (字典树 && 扫描线)相关的知识,希望对你有一定的参考价值。
一:概念
下面我们有and,as,at,cn,com这些关键词,那么如何构建trie树呢?
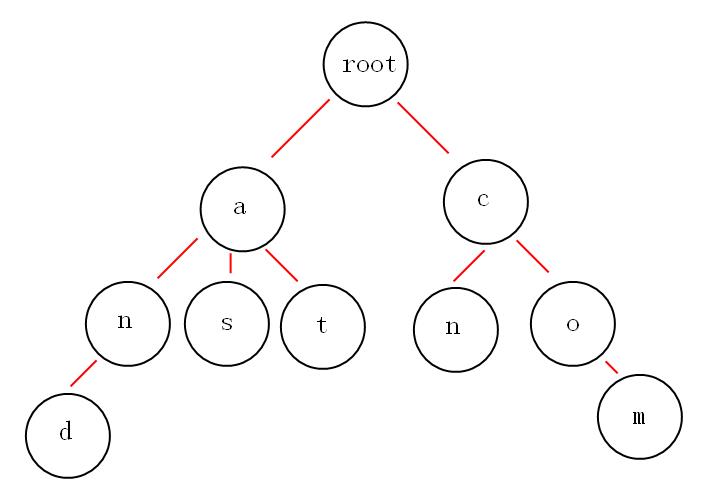
从上面的图中,我们或多或少的可以发现一些好玩的特性。
第一:根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
第二:从根节点到某一节点,路径上经过的字符连接起来,就是该节点对应的字符串。
第三:每个单词的公共前缀作为一个字符节点保存。
二:使用范围
既然学Trie树,我们肯定要知道这玩意是用来干嘛的。
第一:词频统计。
可能有人要说了,词频统计简单啊,一个hash或者一个堆就可以打完收工,但问题来了,如果内存有限呢?还能这么
玩吗?所以这里我们就可以用trie树来压缩下空间,因为公共前缀都是用一个节点保存的。
第二: 前缀匹配
就拿上面的图来说吧,如果我想获取所有以"a"开头的字符串,从图中可以很明显的看到是:and,as,at,如果不用trie树,
你该怎么做呢?很显然朴素的做法时间复杂度为O(N2) ,那么用Trie树就不一样了,它可以做到h,h为你检索单词的长度,
可以说这是秒杀的效果。
相关题目:
Implement Trie
Implement a trie with insert, search, and startsWith methods.
可以用hashmap来实现
 Implement Trie hashmap version
Implement Trie hashmap versiontrie 树是一个26叉树,那么其实可以用一个数组,然后用每个字母对应index.
同时function可以写成递归
递归需要用到index,那么index需要重新写一个insert function 和 find function。注意这两个方法定义在类里面!
(类里面定义函数递归,多写几遍)

class TrieNode { TrieNode[] children; boolean isWord = false; // Initialize your data structure here. public TrieNode() { this.children = new TrieNode[26]; } public TrieNode(char mychar) { this.children = new TrieNode[26]; } public void insert(String word, int index) { if (word.length() == index) { this.isWord = true; return; } int pos = word.charAt(index) - \'a\'; if (children[pos] == null) { children[pos] = new TrieNode(); } children[pos].insert(word, index + 1); } public TrieNode search(String word, int index) { if (index == word.length()) { return this; } int pos = word.charAt(index) - \'a\'; if (children[pos] == null) { return null; } return children[pos].search(word, index + 1); } } public class Trie { private TrieNode root; public Trie() { root = new TrieNode(); } // Inserts a word into the trie. public void insert(String word) { root.insert(word,0); } // Returns if the word is in the trie. public boolean search(String word) { TrieNode res = root.search(word, 0); if (res == null || res.isWord == false) { return false; } return true; } // Returns if there is any word in the trie // that starts with the given prefix. public boolean startsWith(String prefix) { return (root.search(prefix, 0) != null); } }
notes: this是指当前对象自己。
当在一个类中要明确指出使用对象自己的的变量或函数时就应该加上this引用。
------分割线-----
word search II
Given a 2D board and a list of words from the dictionary, find all words in the board.
Each word must be constructed from letters of sequentially adjacent cell, where "adjacent" cells are those horizontally or vertically neighboring. The same letter cell may not be used more than once in a word.
For example,
Given words = ["oath","pea","eat","rain"] and board =
[ [\'o\',\'a\',\'a\',\'n\'], [\'e\',\'t\',\'a\',\'e\'], [\'i\',\'h\',\'k\',\'r\'], [\'i\',\'f\',\'l\',\'v\'] ]
Return ["eat","oath"].
暴力方法对于给定的words array 每一个单词做dfs, 优化方法是在word search 的基础上建立字典树,把dfs过程中找到的结果放倒result array里面去。
优化方法是在word search 的基础上利用字典树。 首先根据字典里的单词建立trie tree。然后和word search 一样进行dfs回溯查找,如果当前的字母不在字典树里面就不需要进行dfs向下查找。如果存在字典树里面,就一直向下查找。如何来判断单词结尾,对于常规的字典树,是在叶子节点存一个isword的boolean变量来表示。这道题也是类似的方法,在做insert的同时,判断如果是最后一个字母的时候,在节点上做一个标记。但是注意,和实现字典树不用,并不是存一个boolean值,而是把整个word string 存下来,这样我们走到叶子节点的时候就知道当前叶子所对应的单词是什么。就可以把相应的单词存到result里面去。
注意在实现字典树搜索的时候,以前是把search 定义在trie tree的类里面利用for loop查找/ 或者在trie tree类里面的search函数叫trie node里面定义的递归版的带index的search函数。 这道题不需要在类里面定义search,而是在进行dfs的同时,记住当前的tree node节点。这样就能做到每往下走一层,在当前的trie树的子节点里面找对应的单词,而不需要从根节点来找对应的string(重要的区别!!!)。另外有个小技巧,不需要额外开辟数组记住visited[][] 直接更新board[][]把特定的位置变成特定的flag值,题目里面我用了‘0’ 作为特定值,表示visited过。记住,从递归体退出的时候,要把修改过的board给改回来。
word search ii犯过的错误:
1.注意这3个if的顺序,如果检测边界条件在增加res之前,那么对于只有一个节点的输入,将得到空的result。
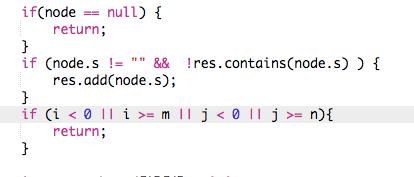
2.把 m,n作为全局变量的话 在class 里面定义了以后,直接赋值,如果在方法里面又重新定义了 int m =.. 这样会造成方法里访问的是这个局部的m。
3.在遍历board做递归的时候,是在循环里面找到新的 i j 然后在下一层递归里面处理相应的结果。注意分清递归层,出口,递归体。
以上是关于数据结构 笔记 part3 (字典树 && 扫描线)的主要内容,如果未能解决你的问题,请参考以下文章