spark -SQL 配置参数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark -SQL 配置参数相关的知识,希望对你有一定的参考价值。
参考技术A官网: http://spark.apache.org/docs/latest/sql-programming-guide.html
或者缓存dataFrame
或者CACHE TABLE
可通过两种配置方式开启缓存数据功能:
使用SQLContext的setConf方法
执行SQL命令 SET key=value
用到的配置
-- spark.sql.autoBroadcastJoinThreshold, broadcast表的最大值10M,当这是为-1时, broadcasting不可用,内存允许的情况下加大这个值
-- spark.sql.shuffle.partitions 当join或者聚合产生shuffle操作时, partitions的数量, 这个值可以调大点, 我一般配置500, 切分更多的task, 有助于数据倾斜的减缓, 但是如果task越多, shuffle数据量也会增多
对于broadcast join模式,会将小于spark.sql.autoBroadcastJoinThreshold值(默认为10M)的表广播到其他计算节点,不走shuffle过程,所以会更加高效。
官网的原话是这个样子:
The BROADCAST hint guides Spark to broadcast each specified table when joining them with another table or view. When Spark deciding the join methods, the broadcast hash join (i.e., BHJ) is preferred, even if the statistics is above the configuration spark.sql.autoBroadcastJoinThreshold. When both sides of a join are specified, Spark broadcasts the one having the lower statistics. Note Spark does not guarantee BHJ is always chosen, since not all cases (e.g. full outer join) support BHJ. When the broadcast nested loop join is selected, we still respect the hint.
注意 : 确定broadcast hash join的决定性因素是hive的表统计信息一定要准确。并且,由于视图是没有表统计信息的,所以所有的视图在join时都不会被广播。所以至少要有一张hive表。
------------------------待完善------------------------
Spark参数有效配置
Spark参数配置有三种方式:
1.在编写代码的时候,通过创建SparkConf的时候,使用set方法配置. 2.动态加载:在使用spark-submit提交代码上集群的时候,通过spark-submit的参数进行配置,可以通过spark-submit --help指令查看能够配置的参数. 3.通过spark-default.conf配置文件配置.如果配置的参数能够同时在这三种配置方法中有效的话,参数值优先度优先使用代码中直接调用SparkConf设置的参数,其次是spark-submit最后才是spark-default,没有设置的才使用默认值.
作用域: 1.仅在spark-default.conf中配置有效的参数 这类参数作用于Master和Worker的机器,在Spark第一次启动的时候生效,这就意味着和提交程序的客户端无关,这类参数通常在类Master.scala和Worker.scala中有源码,配置完需要重启Spark系统生效。 在Master.scala和Worker.scala中初始化过程使用到的参数,只能通过spark-default.conf配置,并且重启集群或重启对应的Worker之后才会生效 例如:

spark.deploy.spreadOut,spark.deploy.defaultCores这两个参数,在Master启动的时候赋值,所以不能通过上面所说前两种方法设置,只能通过spark-dafault.conf设置并重启集群生效.
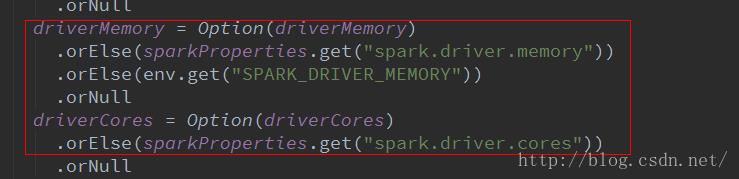
2.在spark-submit 和 spark-default.conf中配置有效: 这类参数通常和driver有关的配置,使用spark-submit提交jar的过程中,有一段调用SparkSumit对象反射启动jar包对象的过程,也就是说,在这个过程中使用到的参数,不能通过SparkConf配置。例如driver相关的几个参数:
以上是关于spark -SQL 配置参数的主要内容,如果未能解决你的问题,请参考以下文章