#图# #二分图匹配# #匈牙利算法#
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了#图# #二分图匹配# #匈牙利算法#相关的知识,希望对你有一定的参考价值。
二分图
设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。
区别二分图,关键是看点集是否能分成两个独立的点集。
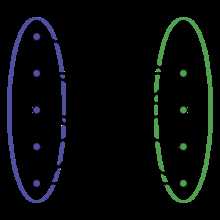
二分图匹配(匈牙利算法)
- 最大匹配:设
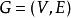 是一个无向图。如顶点集V可分割为两个互不相交的子集
是一个无向图。如顶点集V可分割为两个互不相交的子集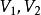 ,选择这样的子集中边数最大的子集称为图的最大匹配问题(maximal matching problem)。
,选择这样的子集中边数最大的子集称为图的最大匹配问题(maximal matching problem)。 - 完全匹配:如果一个匹配中,
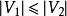 且匹配数
且匹配数 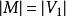 ,则称此匹配为完全匹配,也称作完备匹配。
,则称此匹配为完全匹配,也称作完备匹配。 - 完美匹配:如果一个匹配中,
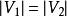 且匹配数 ,称为完美匹配(所有的点都匹配)
且匹配数 ,称为完美匹配(所有的点都匹配)
如图:
点集分成数字和字母,给定边的关系,求最大匹配。

(1)从数字点集开始遍历,从1号开始,所连边终点未被标记-->标记,进行下一个点;已被标记过-->搜索下一条边。
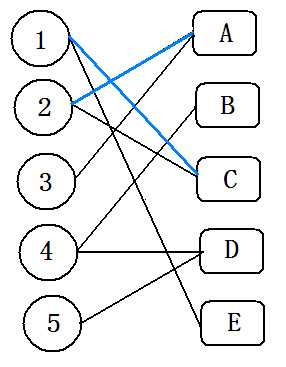
(2)3号只有一条边,且A已被标记过(3委屈)。匈牙利算法就要做一些magic的事情了,从3号搜索到A,因为A已被标记过,直接到2。(红色边为深搜所得边)
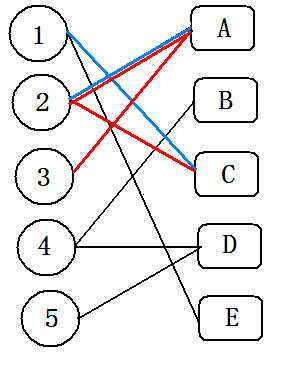
(3)从2深搜到C;C也被标记过,直接到1。
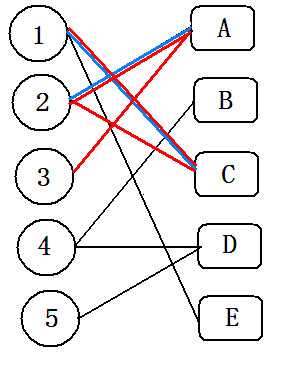
(4)1搜索到E,且E未被标记。
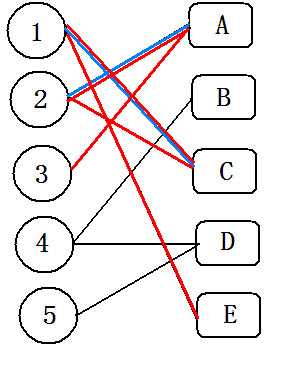
(5)此时,将以上红色&蓝色都有的边删除标记,只有红色的边 为匹配边。
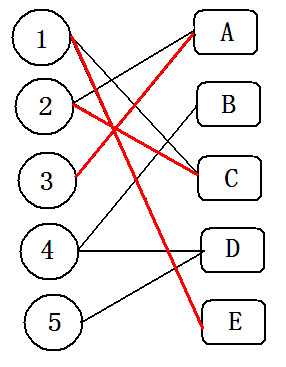
(6)这样1,2,3号点就处理完了,以此类推处理完整张图。
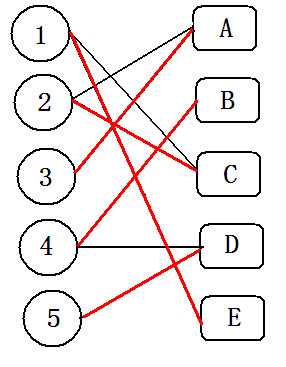
在(2)(3)(4)过程中,我们可以发现,从3号(未被标记过)开始每次遍历的边都遵循着 未匹配->已匹配->未匹配->已匹配... 的规律,此时走过的路为增广路。
而对走过的增广路取反,所得到的匹配边由原先的n条变为(n+1)条。(将M和P进行取反操作可以得到一个更大的匹配![]() 。)
。)
当我们对数字点集全部操作完就已求出最大匹配(不必再对字母点集操作,因为已通过边便利过可遍历的字母点集)。
/*
增广路
若P是图G中一条连通两个未匹配顶点的路径,并且属于M的边和不属于M的边(即已匹配和待匹配的边)在P上交替出现,则称P为相对于M的一条增广路径(举例来说,有A、B集合,增广路由A中一个点通向B中一个点,再由B中这个点通向A中一个点……交替进行)。
*/
1 //二分图匹配(匈牙利算法的DFS实现) 2 //初始化:g[][]两边顶点的划分情况 3 //建立g[i][j]表示i->j的有向边就可以了,是左边向右边的匹配 4 //g没有边相连则初始化为0 5 //uN是匹配左边的顶点数,vN是匹配右边的顶点数 6 //调用:res=hungary();输出最大匹配数 7 //优点:适用于稠密图,DFS找增广路,实现简洁易于理解 8 //时间复杂度:O(VE) 9 //***************************************************************************/ 10 //顶点编号从0开始的 11 const int MAXN=510; 12 int uN,vN;//u,v数目 13 int g[MAXN][MAXN]; 14 int linker[MAXN]; 15 bool used[MAXN]; 16 bool dfs(int u)//从左边开始找增广路径 17 { 18 int v; 19 for(v=0;v<vN;v++)//这个顶点编号从0开始,若要从1开始需要修改 20 if(g[u][v]&&!used[v]) 21 { 22 used[v]=true; 23 if(linker[v]==-1||dfs(linker[v])) 24 {//找增广路,反向 25 linker[v]=u; 26 return true; 27 } 28 } 29 return false;//这个不要忘了,经常忘记这句 30 } 31 int hungary() 32 { 33 int res=0; 34 int u; 35 memset(linker,-1,sizeof(linker)); 36 for(u=0;u<uN;u++) 37 { 38 memset(used,0,sizeof(used)); 39 if(dfs(u)) res++; 40 } 41 return res; 42 }
以上是关于#图# #二分图匹配# #匈牙利算法#的主要内容,如果未能解决你的问题,请参考以下文章