python 正则表达式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 正则表达式相关的知识,希望对你有一定的参考价值。
原文地址:http://blog.csdn.net/longerzone/article/details/24303161
零、引言
在《Dive into Python》(深入python)中,第七章介绍正则表达式,开篇很好的引出了正则表达式,下面借用一下:我们都知道python中字符串也有比较简单的方法,比如可以进行搜索(index,find和count),替换(replace)和解析(split),这在本系列前篇数据结构篇中有所涉及,但是有种种限制。比如要进行大小写不敏感的搜索时,可能就需要先对字符串进行str.lower()或str.upper()将字符串先统一转换成小写或者大写在进行搜索。
那么,本篇的主角正则表达式呢?正则表达式本身是一种小型的、高度专业化的编程语言,它内嵌在Python中,并通过 re 模块实现。使用这个小型语言,你可以为想要匹配的相应字符串集指定规则;该字符串集可能包含英文语句、e-mail地址、TeX命令或任何你想搞定的东西。
下面借用《Dive into Python》中的例子比较一下正则表达式和字符串方法:
- >>> str = "1000 NORTH MAIN ROAD"
- >>> str.replace("ROAD","RD.") -- 通常使用时可能会使用RD.代替ROAD
- ‘1000 NORTH MAIN RD.‘
- >>> str = "1000 NORTH BROAD ROAD" -- 对于BROAD中的ROAD也进行了替换,这并不是我们想要的
- >>> str.replace("ROAD","RD.")
- ‘1000 NORTH BRD. RD.‘
- >>> str[:-4]+str[-4:].replace("ROAD","RD.") -- 通过切片只对最后四个字符的ROAD进行替换
- ‘1000 NORTH BROAD RD.‘
- >>> import re
- >>> re.sub(‘ROAD$‘,"RD.",str) -- 使用正则表达式re中的sub函数对str中的"ROAD$"使用"RD."进行替换,而$在正则表达式中表示行末,所以此句只对最后的ROAD进行了替换,使用起来比上面使用字符串切片再匹配要简单的多
- ‘1000 NORTH BROAD RD.‘
上面只是举了简单的小例子介绍Python中的正则表达式,在这种小例子中python的正则表达式要比字符串方法好用方便许多,更何况它还有更强大的功能?
一、简介
上文已经提及,正则表达式(RE)自身是一种小型的、高度专业化的编程语言,所以,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以s上手了。这里给大家推荐一个学习正则表达式的好资源《正则表达式30分钟入门教程》。
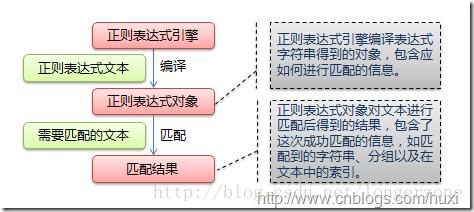
上文显示了正则表达式的工作流程,首先语言中的正则表达式引擎会将用户使用的正则表达式文本编程成正则表达式对象,然后依次拿出表达式对象和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
二、正则表达式元字符语法
这里偷个小懒,直接将《Python正则表达式指南》[2]中大神总结的正则表达式语法图拿过来用了:
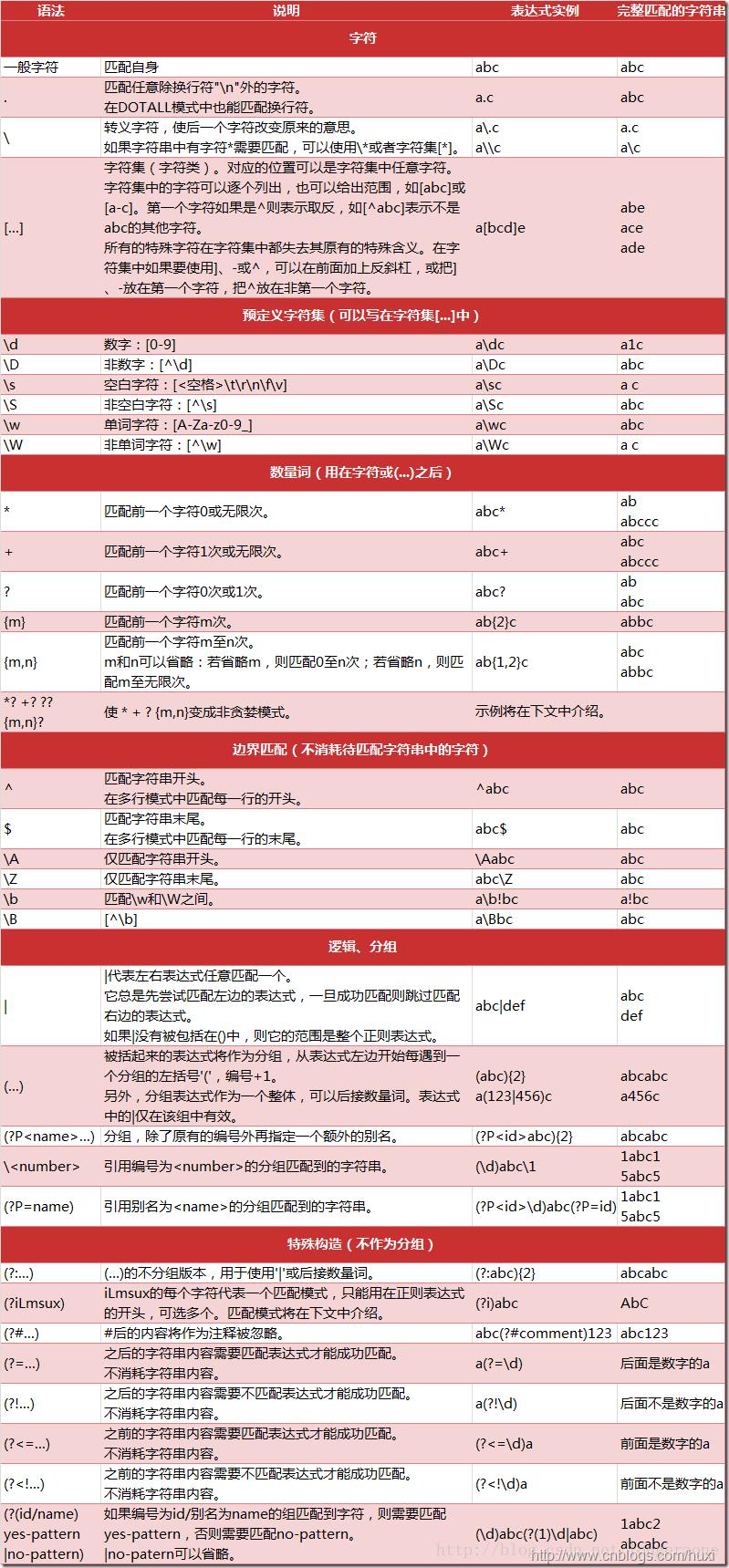
注: 正则表达式之所以复杂难懂,除了它有上面如此多的元字符外,这些元字符之间的组合模式使得RE变得非常难懂。比如: \\S 匹配非空白字符,而加上 + 后 \\S+ 则表示不包含空白字符的字符串!
此外, ^ 字符在上面图片中解释为字符串开始,其实并不完善,在[ a ] 这样的匹配中,^ 表示 “非” ,比如 [ a ]匹配字符 a,而[ ^a ] 则匹配除 a 以外的任意字符。
对于上面图文中没有列出来的,再扩展几条:
2.1 反斜杠!!
与大多数编程语言相同,正则表达式里使用"\\"作为转义字符,这就可能造成反斜杠困扰。比如你想要在匹配文本中匹配制表符"\\t",你需要写成"\\\\t",直接匹配反斜杠需写成"\\\\",更多时会显得尤为复杂。
在Python中,原生字符串很好地解决了这个问题,方法为在匹配文本前加r,如r‘\\‘表示匹配‘\\‘本身。同样,匹配一个数字的"\\\\d"可以写成r"\\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
2.2 贪婪与懒惰
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。例如: a.*b ,它将会匹配 最长的以 a 开始,以 b 结束的字符串 。如果用它来搜索 aabab 的话,它会匹配整个字符串 aabab 。这被称为 贪婪 匹配。
有时,我们更需要 懒惰 匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号 ? 。这样 .*? 就意味着 匹配任意数量的重复, 但是在能使整个匹配成功的前提下使用最少的重复 。比如前面提到的 a.*b ,它的懒惰版为: a.*?b 匹配 最短的,以 a 开始,以 b 结束的字符串 。如果把它应用于 aabab 的话,它会匹配 aab (第一到第三个字符)和 ab (第四到第五个字符)。
- >>> str = "aabab"
- >>> pattern = "a.*b"
- >>> print re.match(pattern,str).group(0)
- aabab
- >>> pattern = "a.*?b"
- >>> print re.match(pattern,str).group(0)
注: 你可能发问了:既然是懒惰匹配,为什么第一个匹配是aab(第一到第三个字符)而不是ab(第二到第三个字符)?简单地说,因为正则表达式有另一条规则,且比懒惰 / 贪婪规则的优先级更高:最先开始的匹配拥有最高的优先权。
——The match that begins earliest wins。
三、一些Python 的RE方法及其应用
在此我们可以使用本系列前篇 -- Python自省中的apihelper模块来查看一下python的 re 模块中有哪些方法:
>>> import re
>>> import apihelper as ah
>>> ah.info(re)
Scanner None
_compile None
...
compile Compile a regular expression pattern, returning a pattern object.
error None
escape Escape all non-alphanumeric characters in pattern.
findall Return a list of all non-overlapping matches in the string. If one or more groups are present in the pattern, return a list of groups; this will be a list of tuples if the pattern has more than one group. Empty matches are included in the result.
finditer Return an iterator over all non-overlapping matches in the string. For each match, the iterator returns a match object. Empty matches are included in the result.
match Try to apply the pattern at the start of the string, returning a match object, or None if no match was found.
purge Clear the regular expression cache
search Scan through string looking for a match to the pattern, returning a match object, or None if no match was found.
split Split the source string by the occurrences of the pattern, returning a list containing the resulting substrings.
sub Return the string obtained by replacing the leftmost non-overlapping occurrences of the pattern in string by the replacement repl. repl can be either a string or a callable; if a string, backslash escapes in it are processed. If it is a callable, it‘s passed the match object and must return a replacement string to be used.
subn Return a 2-tuple containing (new_string, number). new_string is the string obtained by replacing the leftmost non-overlapping occurrences of the pattern in the source string by the replacement repl. number is the number of substitutions that were made. repl can be either a string or a callable; if a string, backslash escapes in it are processed. If it is a callable, it‘s passed the match object and must return a replacement string to be used.
template Compile a template pattern, returning a pattern object
所以,我们可以大概知道,RE模块主要包括,compile, escape, findall, ...等方法,而具体如何使用,我们可以使用 “>>> help(re.match) ” 这样查看每个方法的帮助文档。
闲话不多说,下面将对这些函数一一进行简单介绍:
3.1 python的 re 模块简单使用
前文以及提及,Python通过 re 模块提供对正则表达式的支持。使用 re 的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文
本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
- >>> import re
- >>> pattern = re.compile(r‘hello‘) # 将正则表达式编译成Pattern对象
- >>> match = pattern.match(‘hello world!‘) # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
- >>> if match:
- ... print match.group() # 如果匹配,打印匹配信息
- ...
- hello
RE的编译方法:
re.compile(strPattern[, flag])
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 其第二个参数flag是匹配模式,取值可以使用按位或运算符 ‘|‘ 表示同时生效,比如 re.I | re.M。编译标志让你可以修改正则表达式的一些运行方式。在 re 模块中标志可以使用两个名字,一个是全名如 IGNORECASE,一个是缩写,一字母形式如 I。(标志及其对应的flag及缩写都在下表中清晰的显示)
另外,你也可以在regex字符串中指定模式,比如re.compile(‘pattern‘, re.I | re.M)与re.compile(‘(?im)pattern‘)是等价的。
对于flag 可选值有:
| 名称 | 修饰符 | 说明 |
| IGNORECASE(忽略大小写) | re.I re.IGNORECASE |
忽略大小写,使匹配对大小写不敏感 |
| MULTILINE (多行模式) | re.M re.MULTILINE |
多行模式,改变‘^‘和‘$‘的行为 |
| DOTALL(点任意匹配模式) | re.S re.DOTALL |
点任意匹配模式,改变‘.‘的行为,使 ‘.‘ 匹配包括换行在内的所有字符;没有这个标志, "." 匹配除了换行外的任何字符。 |
| LOCALE(使预定字符类) | re.L re.LOCALE |
做本地化识别(locale-aware)匹配,使预定字符类 \\w \\W \\b \\B \\s \\S 取决于当前区域设定。locales 是 C 语言库中的一项功能,是用来为需要考虑不同语言的编程提供帮助的。举个例子,如果你正在处理法文文本,你想用 "w+ 来匹配文字,但 "w 只匹配字符类 [A-Za-z];它并不能匹配 "é" 或 "?"。如果你的系统配置适当且本地化设置为法语,那么内部的 C 函数将告诉程序 "é" 也应该被认为是一个字母。 |
| UNICODE(Unicode模式) | re.U re.UNICODE |
根据Unicode字符集解析字符,使预定字符类 \\w \\W \\b \\B \\s \\S \\d \\D 取决于unicode定义的字符属性 |
| VERBOSE(详细模式) | re.X re.VERBOSE |
这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。详见4.1 松散正则表达式 |
re 模块还提供了一些其他方法可以不用先编译pattern实例,直接使用方法匹配文本,如上面这个例子可以简写为:(使用compile 编译的好处是可重用)
- m = re.match(r‘hello‘, ‘hello world!‘)
- print m.group()
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回>,在需要大量匹配元字符时有那么一点用。
- >>> re.escape(‘.‘)
- ‘\\\\.‘
- >>> re.escape(‘+‘)
- ‘\\\\+‘
- >>> re.escape(‘?‘)
- ‘\\\\?‘
3.2 python RE模块之match 方法
对于 re 的match 方法,首先我们使用help 查看其介绍:
match(pattern, string, flags=0)
Try to apply the pattern at the start of the string, returning a match object, or None if no match was found.
解释: match()函数只检测RE是不是在string的开始位置匹配, 也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none。
eg.
- >>> print re.match(r‘hello‘, ‘hello world!‘).group()
- hello
- >>> print re.match(r‘hello‘, ‘My name is zhou, hello world!‘).group()
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- AttributeError: ‘NoneType‘ object has no attribute ‘group‘
其实Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
string: 匹配时使用的文本。
re: 匹配时使用的Pattern对象。
pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;>不填写参数时,默认返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
span([group]):
返回(start(group), end(group))。
如:
- >>> match = re.match(r‘hello‘, ‘hello world!‘)
- >>> print match.string -- 打印匹配使用的文本
- hello world!
- >>> print match.re -- 匹配使用的Pattern对象
- <_sre.SRE_Pattern object at 0xb7522520>
- >>> print match.pos -- 文本中正则表达式开始搜索的索引
- 0
- >>> print match.endpos -- 文本中正则表达式结束搜索的索引,一般与len(string)相等
- 12
- >>> print match.lastindex
- None
- >>> print match.lastgroup
- None
- >>> print match.groups()
- ()
- >>> print match.group() -- 不带参数,默认为group(0),打印整个匹配的子串
- hello
- >>> print match.groupdict()
- {}
- >>> print match.start() -- 匹配到的字符串在string中的起始索引
- 0
- >>> print match.end() -- 匹配到的字符串在string中的结束索引
- 5
- >>> print match.span() -- 打印(start,end)
- (0, 5)
3.3 python RE模块之search 方法
同样,我们首先使用help 查看其介绍:
Scan through string looking for a match to the pattern, returning a match object, or None if no match was found.
3.4 python RE模块之两种匹配方法比较(match VS search)
从上面两小节的介绍中我们也可以知道 re.match 从字符串的开始处开始匹配,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search 查找整个字符串,直到找到一个匹配;若无匹配返回None。
从例子中我们可以轻易的看出区别:
- >>> match = re.match(r‘hello‘, ‘my name is zhou, hello world!‘)
- >>> search = re.search(r‘hello‘, ‘my name is zhou, hello world!‘)
- >>> match.group()
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- AttributeError: ‘NoneType‘ object has no attribute ‘group‘
- >>> search.group()
- ‘hello‘
- >>> search.start()
- 17
- >>> search.end()
- 22
3.5 python RE模块之sub 方法
照旧,我们使用help:
sub(pattern, repl, string, count=0, flags=0)
Return the string obtained by replacing the leftmost non-overlapping occurrences of the pattern in string by the replacement repl. repl can be either a string or a callable; if a string, backslash escapes in it are processed. If it is a callable, it‘s passed the match object and must return a replacement string to be used.
解释:
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\\id或\\g<id>、\\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
eg.
- >>> import re
- >>> p = re.compile(r‘(\\w+) (\\w+)‘) -- 匹配p为以空格连接的两个单词
- >>> s = ‘i say, hello world!‘
- >>> print p.sub(r‘\\2 \\1‘, s) -- 以\\id引用分组,将每个匹配中的两个单词掉转位置
- say i, world hello!
- >>> def func(m): -- 一个函数,将匹配单词的首字母改为大写
- ... return m.group(1).title() + ‘ ‘ + m.group(2).title()
- ...
- >>> print p.sub(func, s) -- 使用sub调用func 函数
- I Say, Hello World!
3.6 python RE模块之subn 方法
照旧,我们使用help:
subn(pattern, repl, string, count=0, flags=0)
Return a 2-tuple containing (new_string, number).
new_string is the string obtained by replacing the leftmost non-overlapping occurrences of the pattern in the source string by the replacement repl. number is the number of substitutions that were made. repl can be either a string or a callable; if a string, backslash escapes in it are processed. If it is a callable, it‘s passed the match object and must return a replacement string to be used.
解释: 此函数的参数与 sub 函数完全一致,只不过其返回值是包括两个元素的元组:(new_string, number);第一个返回值 new_string 为sub 函数的结果,第二个 number 为匹配及替换的次数。
例子我们可以直接在上面 sub 的例子上测试:
- >>> import re
- >>> p = re.compile(r‘(\\w+) (\\w+)‘)
- >>> s = ‘i say, hello world!‘
- >>> print p.subn(r‘\\2 \\1‘, s)
- (‘say i, world hello!‘, 2)
- >>> def func(m):
- ... return m.group(1).title() + ‘ ‘ + m.group(2).title()
- ...
- >>> print p.subn(func, s)
- (‘I Say, Hello World!‘, 2)
3.7 python RE模块之findall 方法
照旧,我们使用help:
findall(pattern, string, flags=0)
Return a list of all non-overlapping matches in the string.
If one or more groups are present in the pattern, return a list of groups; this will be a list of tuples if the pattern has more than one group.
Empty matches are included in the result.
解释: 搜索string,以列表形式返回全部能匹配的子串。返回值格式为一个列表
eg.
- >>> re.findall(r‘\\d‘,‘one1two2three3four4‘)
- [‘1‘, ‘2‘, ‘3‘, ‘4‘]
- >>> re.findall(r‘one‘,‘one1two2three3four4‘)
- [‘one‘]
- >>> re.findall(r‘one2‘,‘one1two2three3four4‘)
- []
3.8 python RE模块之finditer 方法
照旧,我们使用help:
finditer(pattern, string, flags=0)
Return an iterator over all non-overlapping matches in the string. For each match, the iterator returns a match object.
Empty matches are included in the result.
eg.
- >>> re.finditer(r‘\\d‘,‘one1two2three3four4‘).group() -- python的迭代器并不能像findall那样直接打印所有匹配
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- AttributeError: ‘callable-iterator‘ object has no attribute ‘group‘
- <callable-iterator object at 0xb744496c> -- 迭代器只能一个接着一个的打印
- >>> for m in re.finditer(r‘\\d‘,‘one1two2three3four4‘):
- ... print m.group()
- ...
- 1
- 2
- 3
- 4
3.9 python RE模块之purge 方法
照旧,我们使用help:
purge()
Clear the regular expression cache
eg.
- >>> p = re.compile(r‘(\\w+) (\\w+)‘)
- >>> p.search("hello world 123 zhou write").group() -- 匹配字符串中的两个单词正常
- ‘hello world‘
- >>> p = re.purge() -- 清空RE缓存
- >>> p.search("hello world 123 zhou write").group() -- 再次使用search,报错!此时p 变成了‘NoneType‘对象,而不是Pattern对象
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- AttributeError: ‘NoneType‘ object has no attribute ‘search‘
3.10 python RE模块之split 方法
照旧,我们使用help:
split(pattern, string, maxsplit=0, flags=0)Split the source string by the occurrences of the pattern, returning a list containing the resulting substrings.
解释:按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定使用默认值0将全部分割。如设定好分割次数后,最后未分割部分将作为列表中的一个元素返回。
eg.
- >>> re.split(r‘\\d‘,‘one1two2three3four4‘)
- [‘one‘, ‘two‘, ‘three‘, ‘four‘, ‘‘]
- >>> re.split(r‘\\d‘,‘one1two2three3four4‘,2)
- [‘one‘, ‘two‘, ‘three3four4‘]
- >>> re.split(r‘\\d‘,‘one1two2three3four4‘,0)
- [‘one‘, ‘two‘, ‘three‘, ‘four‘, ‘‘]
四、About : python 中的正则表达式
4.1 松散正则表达式
对于一个正则表达式,可能过一段时间你就需要重新分析这个表达式的实际意思,因为它本身就是由多个元字符组成,可能你还需要比较着上面的元字符的意思再分析你的表达式文本,那么有什么好的方法能够解决这个问题?比如说下面这个表达式:(dive into python ,P129)
pattern = "^M{0,3}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$"
Python支持使用所谓的松散正则表达式来解决这个问题:
>>> import re
>>> pattern = """
# 本正则表达式为匹配一个罗马数字,而罗马数字中MDCCCLXXXVIII表示1888,所以需要找到其规律写成相应的匹配文本,使用该表达式匹配通过的为罗马数字,否则不是!
# 罗马数字中: I = 1; V = 5; X = 10; L = 50; C = 100; D = 500; M = 1000
# 罗马数字的规则:
# 1. 字符是叠加的,如I表示1,而II表示2,III表示3
# 2. 含十字符(I,X,C,M)至多可以重复三次,而应该利用下一个最大的含五字符进行减操作,如:对于4不能使用IIII而应该是IV,40不是XXXX而是XL,41为XLI,而44为XLIV
# 3. 同样,对于9需要使用下一个十字符减操作,如9表示为IX,90为XC,900为CM
# 4. 含五字符(V,L,D)不能重复,如:10不应该表示为VV而是X
# 5. 罗马数字从高位到低位书写,从左到右阅读,因此不同顺序的字符意义不同,如,DC为600而CD为400.CI 表示101 而IC 为不合法的罗马数字
^ # 字符串开头
M{0,3} # 千位,支持0到3个M
(CM|CD|D?C{0,3})
# 百位,900(CM),400(CD),0~300(0~3个C),500~800(D后接0~3个C)
(XC|XL|L?X{0,3})
# 十位,90(XC),40(XL),0~30(0~3个X),50~80(L后接0~3个X)
(IX|IV|V?I{0,3})
# 个位,9(IX),4(IV),0~3(0~3个I),5~8(V后接0~3个I)
$ # 字符串结尾
"""
>>> re.search(pattern,"M",re.VERBOSE)
-- 匹配M成功。注:使用松散正则表达式必须添加re.VERBOSE(或者re.X)作为其第三个参数flag。
<_sre.SRE_Match object at 0xb7557e30>
>>> re.match(pattern,"M",re.VERBOSE).group() -- 打印匹配文本
‘M‘
>>> re.match(pattern,"MMMDD",re.VERBOSE).group() -- 五字符D重复2次,不符合罗马数字规范,不匹配
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: ‘NoneType‘ object has no attribute ‘group‘
>>> re.match(pattern,"MMMDCCCLXXXVIII",re.VERBOSE).group()
-- MMMDCCCLXXXVIII匹配成功
‘MMMDCCCLXXXVIII‘
所以,使用松散正则表达式,我们可以添加足够详尽的注释内容,可以让你在N年后打开代码,很快读懂。这就是松散正则表达式的作用!
===================================
引用:
[1] 《Dive into Python》-- Chapter 7 正则表达式:免费下载通道(罗嗦一句,深入Python,新手必看,以实例入手介绍python,好书)
[2] 神文:《Python正则表达式指南》http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
[3] 《正则表达式30分钟入门教程》:免费下载通道
[4] Python 正则表达式 http://www.w3cschool.cc/python/python-reg-expressions.html
===================================
拓展阅读:
以上是关于python 正则表达式的主要内容,如果未能解决你的问题,请参考以下文章