hive中关于数据库与表的基本操作
Posted 曹军
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive中关于数据库与表的基本操作相关的知识,希望对你有一定的参考价值。
一:基本用法
1.新建数据库

2.删除数据库
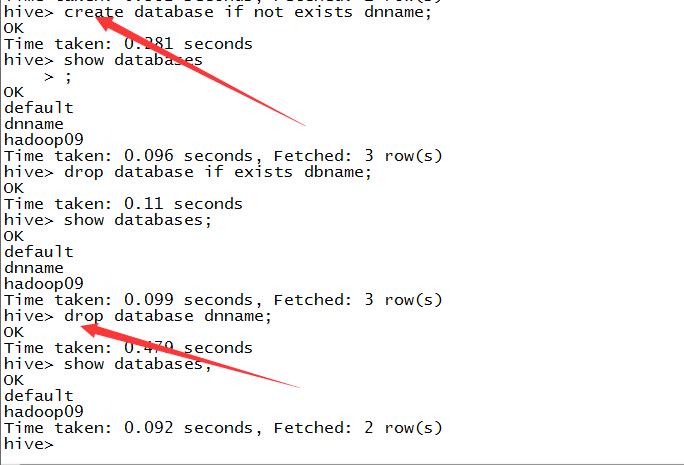
3.删除非空的数据库

4.指定数据库的位置
LOCATION:指定数据库的位置,不会在系统的默认文件下。

5.在指定数据库中新建表(验证在指定的数据库中可以建表)

6.在页面上观看表
可以看到在指定的目录下有一张新建的表。
但是,没有看到指定的数据库。

7.新建表

8.删除一张表
drop table if exists student;

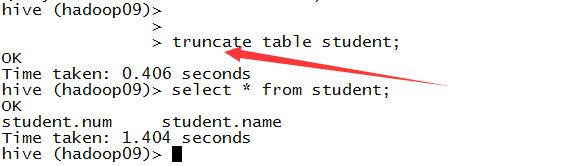
9.清空一张表
10.加载数据
1)从本地加载

2)从HDFS上加载
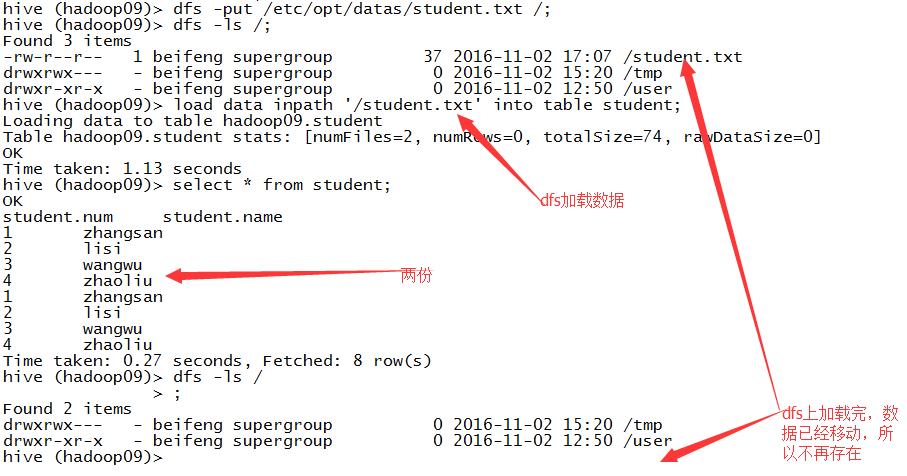
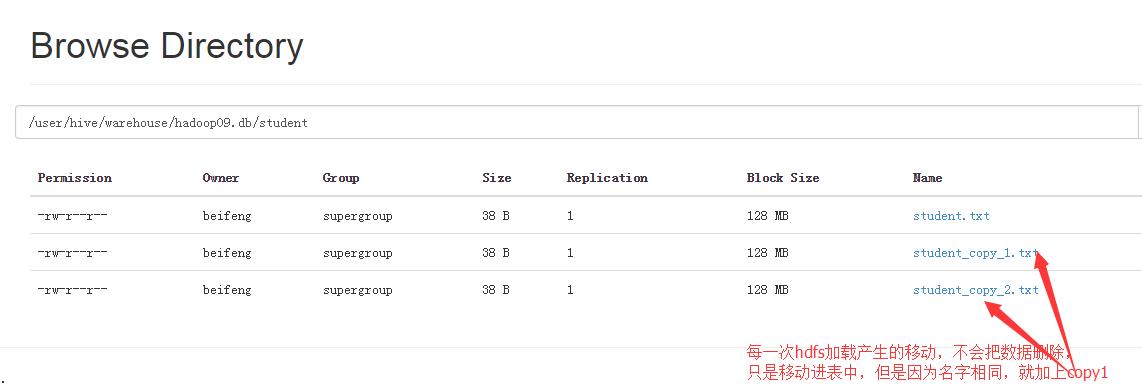
3)区别:
移动。
11.查询

12.描述一张表
一张表的一些信息。

13.查看方法

14.描述方法

二:hive的参数的用法
1.到指定的数据库

2.命令行执行SQL

3.执行文件里的sql

4.启动时指定hive的陪置

5.查看当前的配置,更可以更改配置

三.hive shell中常用的操作
1.访问本地文件系统
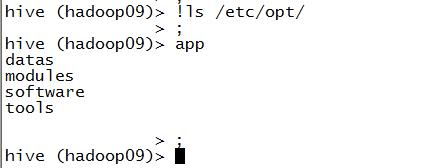
2.访问hdfs

四.hive中表的使用
1.创建表的三种方式
1)第一种方式:普通方式

2)第二种方式:as select ,子查询方式
特点:将子查询的数据和结构复制给新的表。

3)第三种方式:like
特点:复制表的结构。

2.表的类型
1)新建员工表
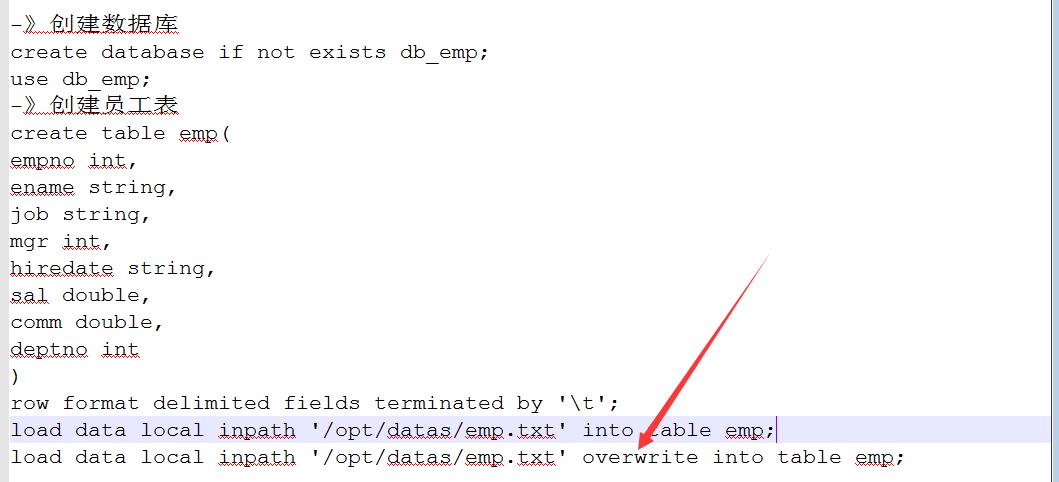
2)新建部门表

3)默认表的类型:管理表
4)问题:文件还有一份,多人使用时,可以通过location指定创建多张表

看在HDFS中的效果

没有加载数据,但是依旧可以使用emp的数据,因为使用的目录。

如果这时候删除掉emp1:
这时,会删除掉元数据的信息,同时删除在HDFS中表的两个文件夹emp与emp1,但是hive中还保留着emp。
5)解决方案
使用外部表。
3.创建外部表
这时,在HDFS上依旧只有一张dept的元数据表。
两个地方:external,location。

4.EXCERANL新建的是外部表
可以看描述信息。
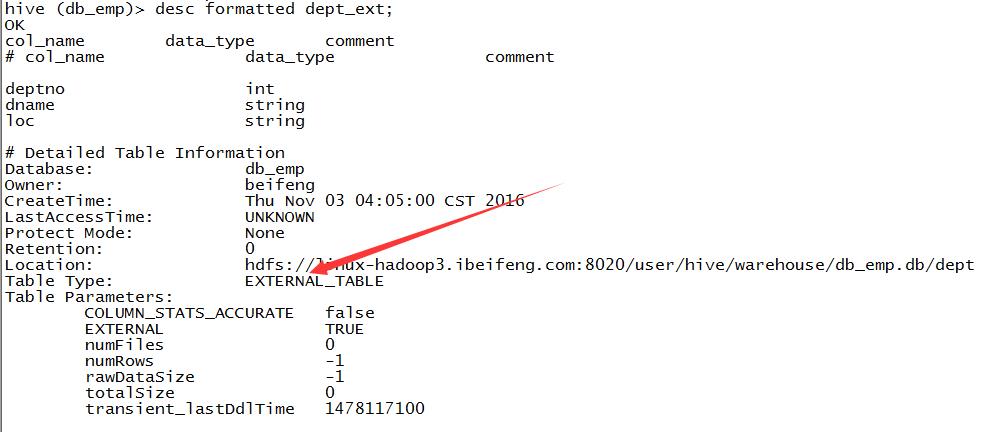
5.外部表的好处
这时,删掉dept_ext,dept表的元数据依然还在。
6.管理表与外部表的区别
管理表的删除操作:先删除元数据,然后删除表的文件夹
外部表的删除操作:只删除元数据
五:分区表
1.分区表需求
当前的web服务器上的log文件,需求是对前一天日志进行分析:
20161019.log
20161020.log
20161021.log
20161022.log
第一种: /logs/20161019.log
20161020.log
20161021.log
20161022.log
select * from logs where date=\'20161022\';
这种情况是:先加载再过滤,其实意思是,这些数据会全部加载到mapreduce,然后才选择自己需要的数据。
第二种: /logs/20161019/20161019.log
/20161020/20161020.log
select * from logs where date=\'20161022\';
这种情况是:会直接加载加载相应的文件到mapreduce。
2.新建分区表
其中,by后面的字段是一个逻辑字段,在表中是没有的。
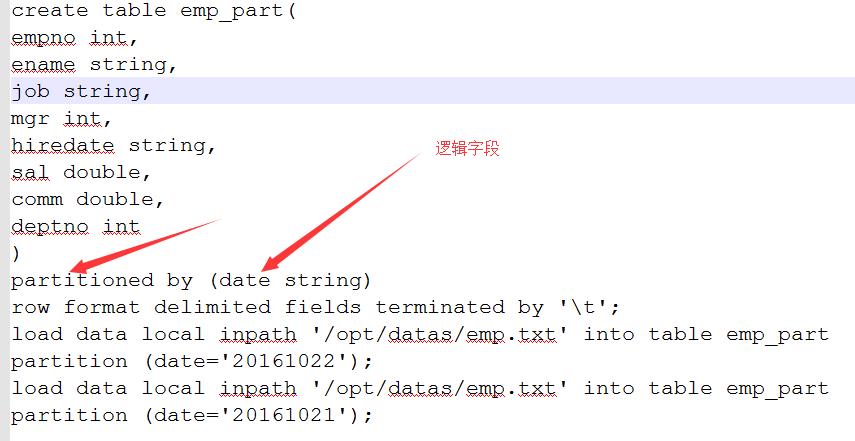
这时,HDFS上出现字段。这个情况是必须加载完数据才会出现的情况,不然没有分区的字段值。

3.分区表查询
分区表的全部查询:
select * from emp;
然后可以根据字段进行过滤:
select * from emp where date=\'20161021\';
为啥可以这么做?因为,在全部的查询中,会发现多了一个date的字段,所以可以作为条件进行过滤。
4.多级分区
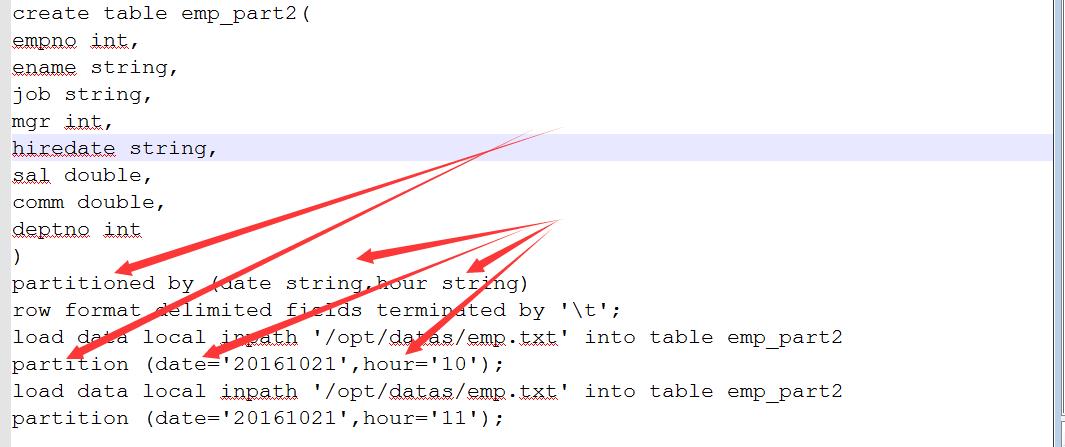
5.多级分区的效果
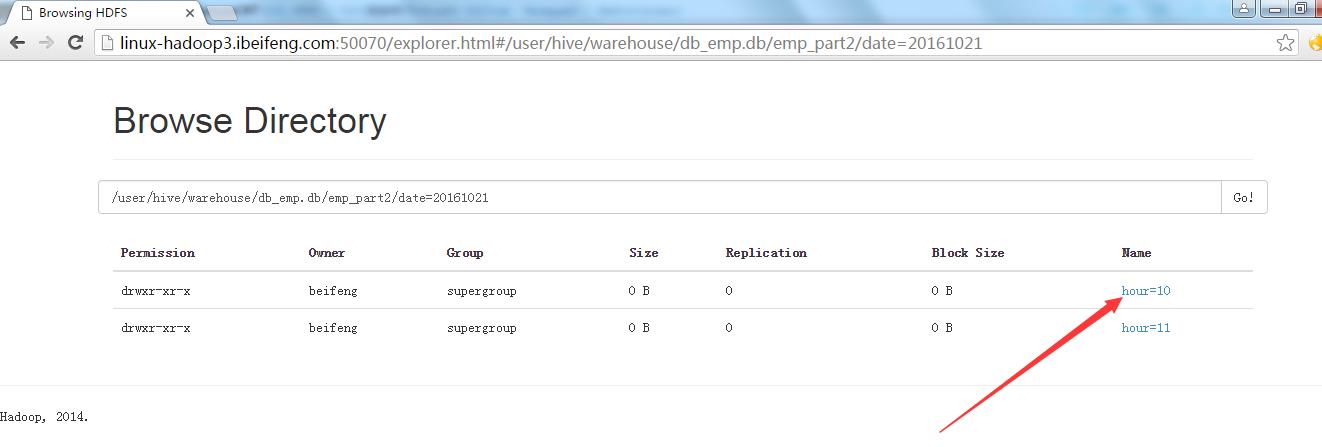
以上是关于hive中关于数据库与表的基本操作的主要内容,如果未能解决你的问题,请参考以下文章