C段中间件扫描器
Posted persuit
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C段中间件扫描器相关的知识,希望对你有一定的参考价值。
很多时候在渗透一个比较大的目标时候,在前期信息收集过程中,我们会发现目标出口规模特别大,有一个或者多个C段甚至B段甚至更大。为了方便撕开口子,
所以我们经常需要对目标出口段进行扫描。之前使用的中间件扫描器误报率太高,所以重构了下代码,实现关键字匹配功能。
代码如下:
#!/usr/bin/env python # encoding: utf-8 # ct.py # author: persuit import requests import re import sys import json from urllib.parse import urljoin import threading from requests.packages.urllib3.exceptions import InsecureRequestWarning requests.packages.urllib3.disable_warnings() PORTS = (80, 8080, ) PATHS = { \'tomcat\':[\'/manager/html\',\'/host-manager/html\'], \'jboss\' :[\'/web-console/login.jsp\'], \'Weathermap\':[\'/plugins/weathermap/editor.php\'], \'Jenkins\':[\'/script\'], } INFORMATION = dict() TEMPLATE = """<html> <title>POOR MAN, POOR LIFE</title> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <style type="text/css"> headline { font-size: 24px; font-family: Monaco; } body { font-size: 10px; font-family: Monaco; line-height:200%%; } it { font-size: 14px; font-family: Monaco; line-height:300%%; } hd { font-size: 10px; font-family: Monaco; line-height:200%%; } lk { font-size: 10px; font-family: Monaco; line-height:200%%; } a:link { text-decoration: none;color: blue} a:active { text-decoration:blink} a:hover { text-decoration:underline;color: red} a:visited { text-decoration: none;color: green} </style> </head> <headline> <center> Scan Report </center> </headline> <br> <body> %s </body> </html>""" def getips(host): ips = [] ip_pre = "" for pre in host.split(\'.\')[0:3]: ip_pre = ip_pre + pre + \'.\' for i in range(1, 255): ips.append(ip_pre + str(i)) return ips class ScanThread(threading.Thread): threadcount = 0 def __init__(self, ip): threading.Thread.__init__(self) self.daemon = True self.ip = ip self.headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:5.0) Gecko/20100101 Firefox/5.0", "Accept": "text/plain"} self.timeout = 5 def curl(self, url): try: request = requests.get(url,headers=self.headers,verify=False,timeout=10) return request except: pass def run(self): for port in PORTS: proto = "https" if (port == 443 or port == 8443) else "http" try: root = "{0}://{1}:{2}".format(proto, self.ip, port) sys.stdout.write("scanning {0:40} ....\\r".format(root[:40])) sys.stdout.flush() resp = self.curl(root) headers = resp.headers code = resp.status_code except: pass else: INFORMATION[root] = dict() INFORMATION[root]["headers"] = headers INFORMATION[root]["available"] = dict() print("{0:55}".format("{0} {1} {2} {3}".format(root, code, headers.get("server", ""), headers.get("x-powered-by", "")))) #for path in PATHS: for k,v in PATHS.items(): for i in v: keyword = k path = i #print (path + keyword) try: #url = urlparse.urljoin(root, path) url = urljoin(root, path) #print (url) sys.stdout.write("scanning {0:40} ....\\r".format(url[:40])) sys.stdout.flush() resp = self.curl(url) content = resp.content code = resp.status_code #print (code) except: print ("error urljoin") pass else: if bytes(keyword,\'utf-8\') in content: if code in (200, 406, 401, 403, 500): title = " ".join(re.findall("<title>(.*?)</title>", content.decode(), re.I)) print("{0:55}".format("{0} {1} {2}".format(url, code, title))) INFORMATION[root]["available"][url] = dict() INFORMATION[root]["available"][url]["code"] = code INFORMATION[root]["available"][url]["title"] = title def write_report(information): SPACE = " " LINK = \'<a href="{0}" target="_blank">{0}</a>\' content = "" for ip, info in information.items(): available = info.get("available") headers = info.get("headers") content += "<it>" content += ip content += "</br>" content += "</it>" for k, v in headers.items():#iteritems(): content += "<hd>" content += SPACE * 2 content += "{0}: {1}".format(k, v) content += "</br>" content += "</hd>" for url, info in available.items():#iteritems(): content += "<lk>" content += SPACE * 4 content += LINK.format(url) content += "</br>" content += SPACE * 6 content += "code: {0}".format(info.get("code")) content += "</br>" content += SPACE * 6 content += "title: {0}".format(info.get("title")) content += "</br>" content += "</lk>" with open(report, "w") as fp: fp.write(TEMPLATE % content) def usage(): print("[usage]: {0} <ip> <report>".format(sys.argv[0])) exit(-1) ##无限循环 if __name__ == \'__main__\': try: ips = getips(sys.argv[1]) report = sys.argv[2] except: usage() else: all_threads = [] for ip in ips: all_threads.append(ScanThread(ip)) for thread in all_threads: thread.start() for thread in all_threads: try: thread.join() except KeyboardInterrupt: exit(1) print("{0:55}".format("Done")) write_report(INFORMATION)
测试截图:
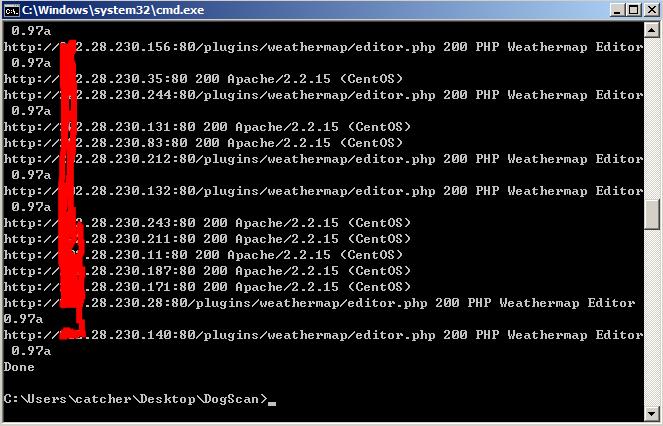
报告截图:
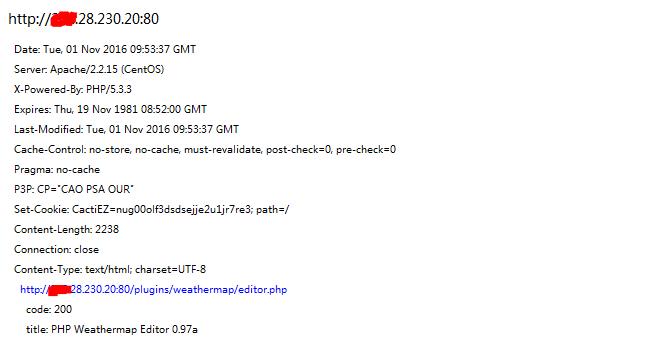
准确率和效率提高不少,看着比之前人性化多了。
以上是关于C段中间件扫描器的主要内容,如果未能解决你的问题,请参考以下文章