机器学习算法
Posted 嘀嘀嘎嘎唔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习算法相关的知识,希望对你有一定的参考价值。
几个分布函数:
PMF(概率质量函数):离散随机变量在各特定取值上的概率。
PDF(概率密度函数):对连续随机变量定义,只有对连续随机变量的取值进行积分后才是概率。
CDF(累积分布函数):能完整描述一个实数随机变量X的概率分布,是PDF的积分。
监督学习:基于已知类别的样本调整分类器的参数,使其达到所要求性能的过程,如SVM,最大熵,CRF。
CRF(条件随机场)与HMM(隐马模型)和MEMM(最大熵隐马模型)相比:
特征灵活,可容纳较多上下文信息,全局最优,缺点是训练代价大,复杂度高。
无监督学习:对没有分类标记的训练样本进行学习,以发现训练样本集中的结构性知识的过程。
基于核的机器学习算法:RBF(径向基函数)、LDA、SVM。
特征选择方法:卡方、信息增益、平均互信息、期望交叉熵。
特征降维方法:PCA、LDA、深度学习sparseAutoEncodrer、矩阵奇异值分解SVD、LASSO、小波分析、拉普拉斯特征映射。
LDA(Linear Discriminant Analysis 线性判别分析),是一种监督学习。将带上标签的数据(点),通过投影的方法,投影到维度更低的空间中,使得投影后的点,形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近。是一种线性分类器。分类的目标是,类别内的点距离越近越好(集中),类别间的点越远越好。
PCA(主成分分析):PCA是一种无监督学习。LDA通常来说是作为一个独立的算法存在,给定了训练数据后,将会得到一系列的判别函数(discriminate function),之后对于新的输入,就可以进行预测了。而PCA更像是一个预处理的方法,目标是通过某种线性投影,将高维的数据映射到低维的空间中表示,并期望在所投影的维度上数据的方差最大,以此使用较少的数据维度,同时保留住较多的原数据点的特性。PCA追求的是在降维之后能够最大化保持数据的内在信息,并通过衡量在投影方向上的数据方差的大小来衡量该方向的重要性。但是这样投影以后对数据的区分作用并不大,反而可能使得数据点揉杂在一起无法区分。这也是PCA存在的最大一个问题,这导致使用PCA在很多情况下的分类效果并不好。PCA的变换矩阵是协方差矩阵。
a*b和b*c两矩阵相乘效率为a*b*c。
线性非线性问题:
伪逆法:是RBF神经网络的训练算法,径向基解决的就是线性不可分情况。
HK算法:在最小均方误差准则下求得权矢量,适用于线性可分和非线性可分的情况。对于线性可分的情况,给出最优权矢量,
对于非线性可分的情况,能够判别出来,以退出迭代过程。
势函数法:非线性。
时间序列模型:
AR:线性预测;
MA:滑动平均模型,模型参量法谱分析方法之一;
ARMA:自回归滑动平均模型,模型参量法高分辨率谱分析方法之一,比前两者有较精确的谱估计及较优的谱分辨率性能,但其参数估算比较繁琐。
GARCH:广义ARCH模型,特别适用于波动性的分析和预测。
判别式模型:逻辑回归、SVM、传统神经网络、最近邻、CRF、LDA、boosting、线性回归。
产生式模型:高斯、朴素贝叶斯、HMMS、sigmoid belief networks、MRF、Latent Dirichlet Allocation。
EM算法: 只有观测序列,无状态序列时来学习模型参数;
维特比算法: 用动态规划解决HMM的预测问题,不是参数估计;
前向后向:算概率;
极大似然估计:即观测序列和相应的状态序列都存在时的监督学习算法,用来估计参数。
EXCEL中MATCH函数可返回指定内容所在位置,INDEX又可根据位置查询所对应数据。
MATCH(lookup-value,lookup-array,match-type)
INDEX(array,row-num,column-num)
分类器
分类器是数据挖掘中对样本进行分类的方法的统称,包含决策树、逻辑回归、朴素贝叶斯、神经网络等算法。
-
选定样本(正负样本),分成训练样本和测试样本两部分。
-
在训练样本上执行分类器算法,生成分类模型。
-
在测试样本上执行分类模型,生成预测结果。
-
根据预测结果,计算必要的评估指标,评估分类模型的性能。
(1)决策树(Decision Tree):是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法,是一种监督学习。优点是可读性好,反复使用,每次预测的最大计算次数不超过决策树的深度。
在机器学习中,随机森林Random Forest是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。
1、数据的随机性选取:首先,从原始的数据集中采取有放回的抽样,构造子数据集,子数据集的数据量是和原始数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。第二,利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。最后,如果有了新的数据需要通过随机森林得到分类结果,就可以通过对子决策树的判断结果的投票,得到随机森林的输出结果了。
2、待选特征的随机选取:与数据集的随机选取类似,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。这样能够使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
(2)逻辑回归:它不是一个回归模型,而是一个分类模型。
模型特点:
1. 优点:训练快、易实现;
2. 缺点:欠拟合,对于复杂的任务效果不够好;
计算方法很简单,分为两步:1,计算梯度,2,更新权值。
逻辑回归的目的是为了寻找非线性函数Sigmoid的最佳拟合参数中的权值w,其w的值通过梯度上升法来学习到。随机梯度上升一次只处理少量的样本,节约了计算资源,同时也使得算法可以在线学习。
(3)贝叶斯分类:是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。
贝叶斯定理:
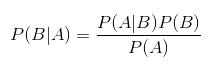 ;
;
贝叶斯分类中最简单的一种:朴素贝叶斯分类。其思想基础是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
对于先验概率p(y):
(1)当p(y)已知,使用贝叶斯公式求后验概率即可。
(2)当p(y)未知,使用N-P决策来计算决策面。最大最小损失规则主要就是解决最小损失规则时先验概率未知或难以计算的问题。
线性分类器三大类:
感知器准则函数,SVM,Fisher准则
SVM:
支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。
主要思想可以概括为两点:
(1)它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能;
(2)它基于结构风险最小化理论之上在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并且在整个样本空间的期望风险以某个概率满足一定上界。
一般特征
以上是关于机器学习算法的主要内容,如果未能解决你的问题,请参考以下文章