算法1(摘录)
Posted L的存在
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法1(摘录)相关的知识,希望对你有一定的参考价值。
第三章 算法
前言:许多人对算法的看法是截然不同的,我之前提到过了。不过,我要说的还是那句话:算法体现编程思想,编程思想指引算法。
同时,有许多人认为简单算法都太简单了,应当去学习一些更为实用的复杂算法。不过,许多复杂算法都是从简单算法演绎而来的,这里就不一一举例了。而且,算法千千万万。更为重要的是从算法中体会编程的思想。
4.1 简单问题算法
PS:接下来是一些入门问题,简单到都没有具体算法可言。但这些问题是我们当初对算法的入门。如果不喜欢,可以跳过。
实例111 任意次方后的最后三位
问题:编程实现一个整数任意次方后的最后三位数,即求xy的最后三位数,x和y的值由键盘输入。
逻辑:无论是刚接触编程还是现在,看到这个问题,你的脑海里都不会出现一个有名有姓的具体算法。但是,你却能够找到解决问题的逻辑步骤。而这个逻辑步骤的清晰指令就是算法。其次,这种情况不仅仅面对这题。当以后遇到诸多问题时都是这样,了解问题->分析问题->建立模型->寻找算法->编写程序->解决问题。最后,这题还体现了我在之前篇章强调的一点,编程解决问题的同时,还可以依靠数学的思想简化问题及程序。这题如果直接计算xy,也许还没等我们提取xy最后三位,xy的值就越界了。所以在每一次循环计算z*x之后,取z*x的最后三位作为z的值。其实,如果x的值大于999,也可以取x的后三位为新的x,结果不变。
代码:

1 #include<stdio.h>
2 main()
3 {
4 int i, x, y, z = 1;
5 printf("please input two numbers x and y(x^y):\\n");
6 scanf("%d%d", &x, &y);
7 //输入底数和幂数
8 for (i = 1; i <= y; i++)
9 z = z * x % 1000;
10 //计算一个数任意次方的后三位
11 printf("the last 3 digits of %d^%d is:%d\\n", x, y, z);
12 //输出最终结果
13 }
反思&总结:一个简单的问题,往往也可以从中分析到许多重要结论。就如同接下来许多算法,虽然简单、基础,却也是日后复杂算法的基础。
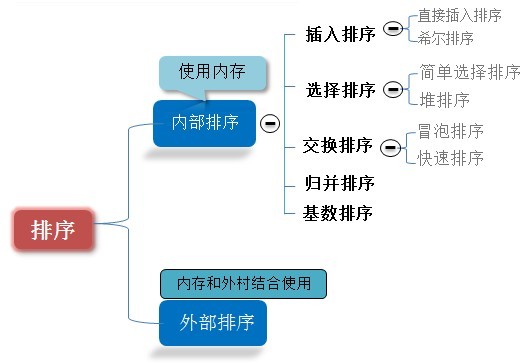
4.2 排序算法
PS:排序是数据处理中的一种重要算法。其中由于待排序的记录数量不同,使得排序过程中涉及的存储器不同,可将排序算法分为两大类:内部排序(待排序记录存放在RAM)与外部排序(排序过程中涉及ROM)。排序算法众多,最好的算法往往是与需求相关的。不过从使用上来说,频率最高的是归并排序,快速排序,堆排序(因为当n较大时,时间复杂度O(nlog2n)的上述三种算法最为迅捷)。
PS:从网络上找到的一张图。
实例119 直接插入排序
问题:通过直接插入排序,编程实现排序。
逻辑:插入排序是将一个数据插入到已排序的有序序列中,使得整个序列在插入了该数据后仍然有序(默认单个数据的序列为有序序列)。插入排序中较为简单的一种方法便是直接插入排序,它插入的位置的确定是通过将待插入的数据与有序区中的个数据自左向右依次比较其关键字值大小来确定的。
代码:
1 #include <stdio.h>
2 void insort(int s[], int n)
3 /*自定义函数isort*/
4 {
5 int i, j;
6 for (i = 2; i <= n; i++)
7 /*数组下标从2开始,0做监视哨,1一个数据无可比性*/
8 {
9 s[0] = s[i];
10 /*给监视哨赋值*/
11 j = i - 1;
12 /*确定要进行比较的元素的最右边位置*/
13 while (s[0] < s[j])
14 {
15 s[j + 1] = s[j];
16 /*数据右移*/
17 j--;
18 /*移向左边一个未比较的数*/
19 }
20 s[j + 1] = s[0];
21 /*在确定的位置插入s[i]*/
22 }
23 }
24 main()
25 {
26 int a[11], i;
27 /*定义数组及变量为基本整型*/
28 printf("please input number:\\n");
29 for (i = 1; i <= 10; i++)
30 scanf("%d", &a[i]);
31 /*接收从键盘中输入的10个数据到数组a中*/
32 printf("the original order:\\n");
33 for (i = 1; i < 11; i++)
34 printf("%5d", a[i]);
35 /*将为排序前的顺序输出*/
36 insort(a, 10);
37 /*调用自定义函数isort()*/
38 printf("\\nthe sorted numbers:\\n");
39 for (i = 1; i < 11; i++)
40 printf("%5d", a[i]);
41 /*将排序后的数组输出*/
42 printf("\\n");
43 }
PS:设立监视哨是为了避免数据在后移时丢失。
反思:直接插入算法应该是大多数人接触的第一个算法了。但是,有多少人自己将这个算法进一步优化呢?
实例120 希尔排序
问题:通过希尔排序,编程实现排序。
逻辑:希尔排序是在直接插入排序的基础上进行了改进。将要排序的序列按固定增量d分成若干组,即将等距离者(相距d的数据)划分在同一组中,再在组内进行直接插入排序。然后减小增量d,再在新划分的组内进行直接插入排序。重复上述操作,直至增量d减小到1(即所有数据都放在了同一组内进行直接插入排序)。

代码:
1 #include <stdio.h>
2 void shsort(int s[], int n)
3 /*自定义函数shsort*/
4 {
5 int i, j, d;
6 d = n / 2;
7 /*确定固定增量值*/
8 while (d >= 1)
9 {
10 for (i = d + 1; i <= n; i++)
11 /*数组下标从d+1开始进行直接插入排序*/
12 {
13 s[0] = s[i];
14 /*设置监视哨*/
15 j = i - d;
16 /*确定要进行比较的元素的最右边位置*/
17 while ((j > 0) && (s[0] < s[j]))
18 {
19 s[j + d] = s[j];
20 /*数据右移*/
21 j = j - d;
22 /*向左移d个位置*/
23 }
24 s[j + d] = s[0];
25 /*在确定的位置插入s[i]*/
26 }
27 d = d / 2;
28 /*增量变为原来的一半*/
29 }
30 }
31 main()
32 {
33 int a[11], i;
34 /*定义数组及变量为基本整型*/
35 printf("please input numbers:\\n");
36 for (i = 1; i <= 10; i++)
37 scanf("%d", &a[i]);
38 /*从键盘中输入10个数据*/
39 shsort(a, 10);
40 /*调用shsort()函数*/
41 printf("the sorted numbers:\\n");
42 for (i = 1; i <= 10; i++)
43 printf("%5d", a[i]);
44 /*将排好序的数组输出*/
45 }
反思:其实希尔排序就是一个分组排序。通过比较固定距离(称为增量)的数据,使得在数据的一次移动时可能跨过多个元素,则在一次数据比较就可能消除多个数据交换。而这就是希尔排序较直接插入排序的美丽之处。
实例120.5.1 简单选择排序
问题:通过简单选择排序,编程实现排序。
逻辑:从待排序区间中找出关键字值最小(/最大)的数据(选择),将其与待排序区间第一个数据a[0]交换(默认本身可以与本身交换).将其中再从剩余的待排序区间(a[1]-a[n])重复上述操作,直至最后一个数据完成交换。
代码:
1 #include <stdio.h>
2 main()
3 {
4 int i, j, t, a[11];
5 /*定义变量及数组为基本整型*/
6 printf("please input 10 numbers:\\n");
7 for (i = 1; i < 11; i++)
8 scanf("%d", &a[i]);
9 /*从键盘中输入要排序的10个数字*/
10 for (i = 1; i <= 9; i++)
11 for (j = i + 1; j <= 10; j++)
12 if (a[i] > a[j])
13 /*如果后一个数比前一个数大则利用中间变量t实现俩值互换*/
14 {
15 t = a[i];
16 a[i] = a[j];
17 a[j] = t;
18 }
19 printf("the sorted numbers:\\n");
20 for (i = 1; i <= 10; i++)
21 printf("%5d", a[i]);
22 /*将排好序的数组输出*/
23 }
反思:简单选择排序存在其改进算法——二元选择排序,简单选择排序每次循环都只能确定一个数据(关键字值最大/最小)的定位。那么在每次循环同时确定关键字值最大和关键字值最小的数据,那么就可以在n/2次循环后完成排序。
实例120.5.2 堆排序
问题:通过堆排序,编程实现排序。
逻辑:堆排序是一种树形选择排序,是对直接选择算法更为彻底的改进。堆排序中的堆指代的就是完全二叉树。堆又分为:大根堆和小根堆。大根堆要求完全二叉树中的每个节点的值都不大于其父节点的值。根据定义,大根堆的堆顶一定是关键字值最大的。同理,可理解小堆根的定义与堆顶关键字值最小。
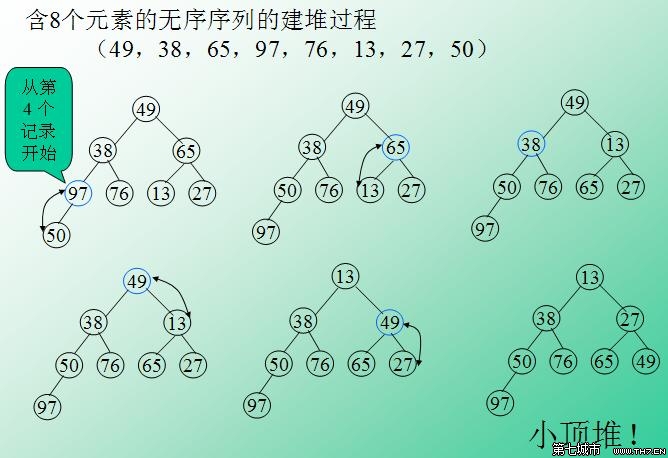
(图片选自网络资源)
代码:(经过考虑,还是选了兰亭风雨的代码,比较易于理解)
1 #include<stdio.h>
2 #include<stdlib.h>
3 /* arr[start+1...end]满足最大堆的定义, 将arr[start]加入到最大堆arr[start+1...end]中, 调整arr[start]的位置,使arr[start...end]也成为最大堆 注:由于数组从0开始计算序号
4
5 ,也就是二叉堆的根节点序号为0, 因此序号为i的左右子节点的序号分别为2i+1和2i+2 */
6 void HeapAdjustDown(int *arr,int start,int end)
7 {
8 int temp=arr[start];
9 //保存当前节点
10 int i=2*start+1;
11 //该节点的左孩子在数组中的位置序号
12 while(i<=end)
13 {
14 //找出左右孩子中最大的那个
15 if(i+1<=end && arr[i+1]>arr[i])
16 i++;
17 //如果符合堆的定义,则不用调整位置
18 if(arr[i]<=temp)
19 break;
20 //最大的子节点向上移动,替换掉其父节点
21 arr[start]=arr[i];
22 start=i;
23 i=2*start+1;
24 }
25 arr[start]=temp;
26 }
27 /* 堆排序后的顺序为从小到大 因此需要建立最大堆 */
28 void Heap_Sort(int *arr,int len)
29 {
30 int i;
31 //把数组建成为最大堆
32 //第一个非叶子节点的位置序号为(len-1)/2 for(i=(len-1)/2;i>=0;i--)
33 for(i=(len-1)/2;i>=0;i--)
34 HeapAdjustDown(arr,i,len-1);
35 //进行堆排序 for(i=len-1;i>0;i--)
36 for(i=len-1;i>0;i--)
37 {
38 //堆顶元素和最后一个元素交换位置,
39 //这样最后的一个位置保存的是最大的数,
40 //每次循环依次将次大的数值在放进其前面一个位置,
41 //这样得到的顺序就是从小到大
42 int temp=arr[i];
43 arr[i]=arr[0];
44 arr[0]=temp;
45 //将arr[0...i-1]重新调整为最大堆
46 HeapAdjustDown(arr,0,i-1);
47 }
48 }
49 int main()
50 {
51 int num;
52 printf("请输入排序的元素的个数:");
53 scanf("%d",&num);
54 int i;
55 int *arr = (int *)malloc(num*sizeof(int));
56 printf("请依次输入这%d个元素(必须为整数):",num);
57 for(i=0;i<num;i++)
58 scanf("%d",arr+i);
59 printf("堆排序后的顺序:");
60 Heap_Sort(arr,num);
61 for(i=0;i<num;i++)
62 printf("%d ",arr[i]);
63 printf("\\n");
64 free(arr);
65 arr = 0;
66 return 0;
67 }
反思:由于开始建立初始堆时比较次数较多,故不适合数据较少的排序。
实例121 冒泡排序
问题:通过冒泡排序,编程实现排序。
逻辑:冒泡排序可以说是直接排序后遇到的最早的排序方法,同时也是许多C语言入门考试的重点。对n个数据进行冒泡排序,那么就要进行n-1趟比较(PS:在第j趟比较中要进行n-j次两两比较)。每次通过比较相邻的两个数据,将关键字值较小的上升(下降),将关键字值较大的下降(上升)。由于这样的模式就像是水中的泡泡在上升,故命名为冒泡排序。
代码:
1 #include <stdio.h>
2 main()
3 {
4 int i, j, t, a[11];
5 /*定义变量及数组为基本整型*/
6 printf("please input 10 numbers:\\n");
7 for (i = 1; i < 11; i++)
8 scanf("%d", &a[i]);
9 /*从键盘中输入10个数*/
10 for (i = 1; i < 10; i++)
11 /*变量i代表比较的趟数*/
12 for (j = 1; j < 11-i; j++)
13 /*变量j代表每趟两两比较的次数*/
14 if (a[j] > a[j + 1])
15 {
16 t = a[j];
17 /*利用中间变量实现俩值互换*/
18 a[j] = a[j + 1];
19 a[j + 1] = t;
20 }
21 printf("the sorted numbers:\\n");
22 for (i = 1; i <= 10; i++)
23 printf("%5d", a[i]);
24 /*将冒泡排序后的顺序输出*/
25 }
反思:冒泡排序算法是一个看到名字就可以想象到其原理的一个算法。所以是很好理解、记忆的。
实例122 快速排序
问题:通过快速排序,编程实现排序
逻辑:快速排序是冒泡排序的一种改进。主要的算法思想是在待排序的n个数据中去第一个数据作为基准值,将所有的数据分为3组,使得第一组中各数据均小于或等于基准值,第二组便是做基准值的数据,第三组中个数据均大于或等于基准值。这就实现了第一趟分割,然后对第一组和第三组分别重复上述方法,以此类推,直到每组中只有一个数据为止。
代码:
1 #include <stdio.h>
2 void qusort(int s[], int start, int end)
3 /*自定义函数qusort()*/
4 {
5 int i, j;
6 /*定义变量为基本整型*/
7 i = start;
8 /*将每组首个元素赋给i*/
9 j = end;
10 /*将每组末尾元素赋给j*/
11 s[0] = s[start];
12 /*设置基准值*/
13 while (i < j)
14 {
15 while (i < j && s[0] < s[j])
16 j--;
17 /*位置左移*/
18 if (i < j)
19 {
20 s[i] = s[j];
21 /*将s[j]放到s[i]的位置上*/
22 i++;
23 /*位置右移*/
24 }
25 while (i < j && s[i] <= s[0])
26 i++;
27 /*位置右移*/
28 if (i < j)
29 {
30 s[j] = s[i];
31 /*将大于基准值的s[j]放到s[i]位置*/
32 j--;
33 /*位置右移*/
34 }
35 }
36 s[i] = s[0];
37 /*将基准值放入指定位置*/
38 if (start < i)
39 qusort(s, start, j - 1);
40 /*对分割出的部分递归调用函数qusort()*/
41 if (i < end)
42 qusort(s, j + 1, end);
43 }
44 main()
45 {
46 int a[11], i;
47 /*定义数组及变量为基本整型*/
48 printf("please input numbers:\\n");
49 for (i = 1; i <=