[Math] Hidden Markov Model
Posted 机器学习水很深
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Math] Hidden Markov Model相关的知识,希望对你有一定的参考价值。
看上去不错的网站:http://iacs-courses.seas.harvard.edu/courses/am207/blog/lecture-18.html
SciPy Cookbook:http://scipy-cookbook.readthedocs.io/items/KalmanFiltering.html
讲解思路貌似是在已知迭代结果的基础上做讲解,不是很透彻。
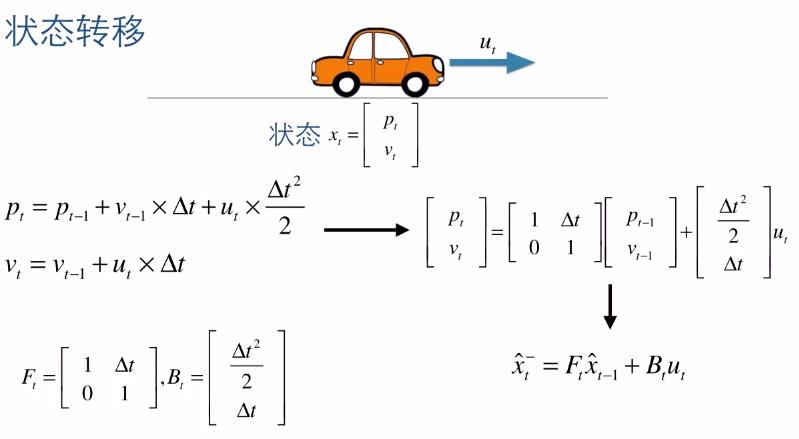
1. 用矩阵表示
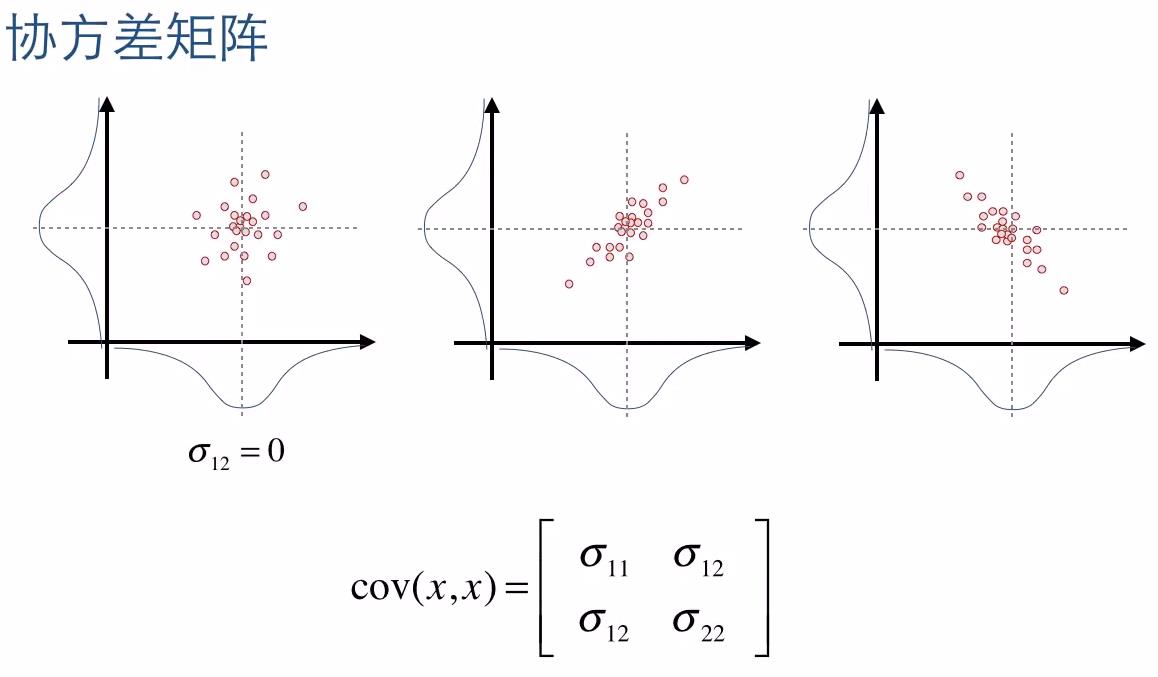
2. 本质就是:二维高斯的协方差与sampling效果
3. 不确定性在状态之间的传递
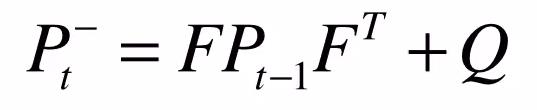
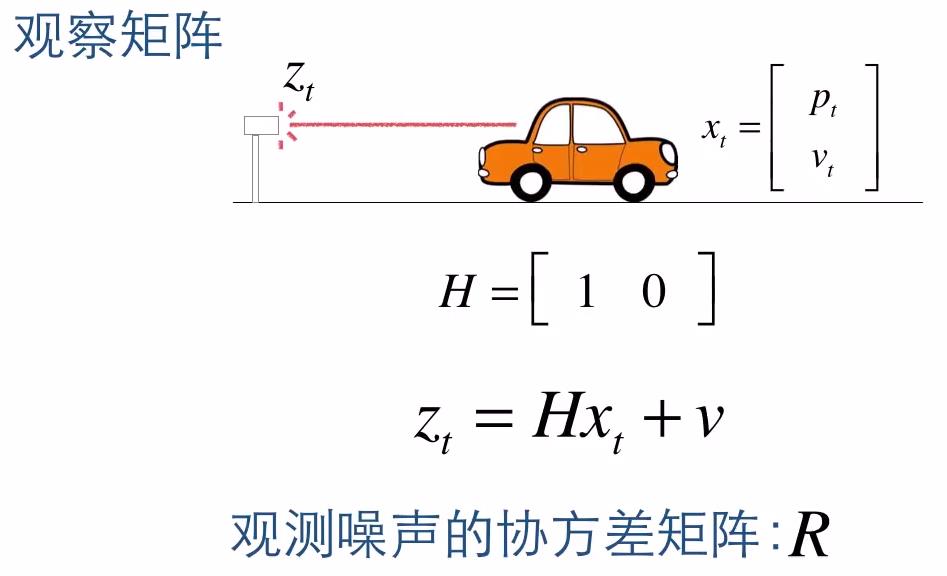
4. 矩阵表示观察数据
5. Kalman系数
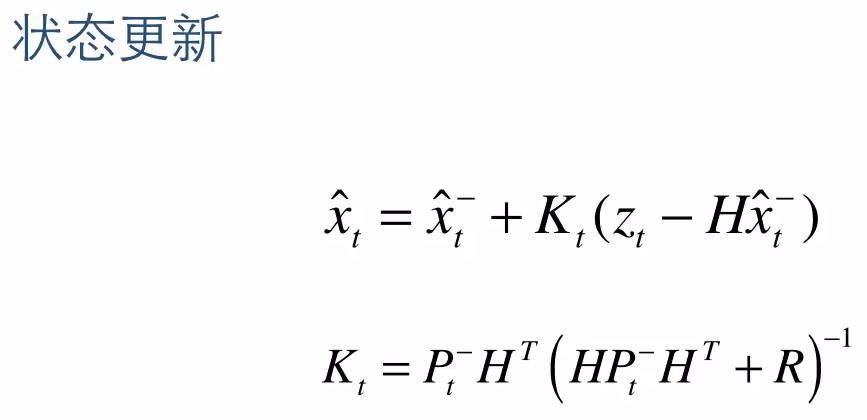
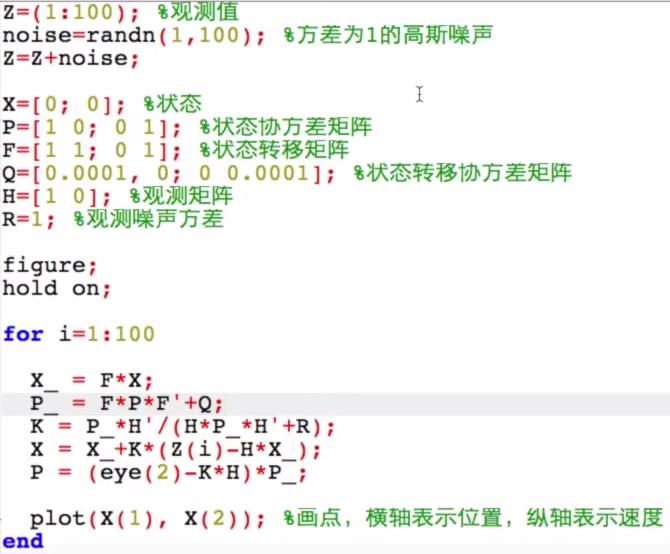
6. 噪声协方差矩阵的更新
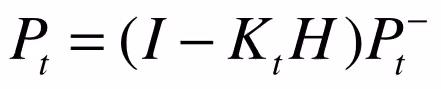
7. Matlab实现
思考:
与数学领域 openBUGS 的估参的关系是什么?[Bayes] openBUGS: this is not the annoying bugs in programming
一个是对逐渐增多数据的实时预测;一个是对总体数据的回归拟合。
代码示例:纯python代码
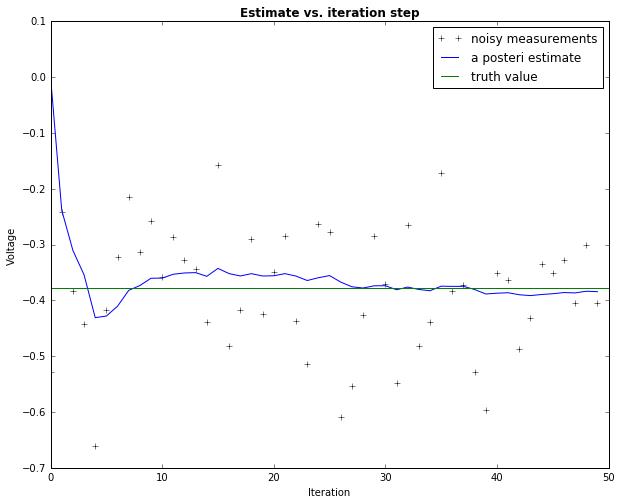
# Kalman filter example demo in Python # A Python implementation of the example given in pages 11-15 of "An # Introduction to the Kalman Filter" by Greg Welch and Gary Bishop, # University of North Carolina at Chapel Hill, Department of Computer # Science, TR 95-041, # http://www.cs.unc.edu/~welch/kalman/kalmanIntro.html # by Andrew D. Straw import numpy as np import matplotlib.pyplot as plt plt.rcParams[\'figure.figsize\'] = (10, 8) # intial parameters n_iter = 50 sz = (n_iter,) # size of array x = -0.37727 # truth value (typo in example at top of p. 13 calls this z) z = np.random.normal(x,0.1,size=sz) # observations (normal about x, sigma=0.1) # 已获得一组随机数
Q = 1e-5 # process variance # allocate space for arrays xhat =np.zeros(sz) # a posteri estimate of x P =np.zeros(sz) # a posteri error estimate xhatminus =np.zeros(sz) # a priori estimate of x Pminus =np.zeros(sz) # a priori error estimate K =np.zeros(sz) # gain or blending factor R = 0.1**2 # estimate of measurement variance, change to see effect # intial guesses xhat[0] = 0.0 P[0] = 1.0
# 开始迭代 for k in range(1, n_iter): # time update xhatminus[k] = xhat[k-1] Pminus[k] = P[k-1]+Q # measurement update K[k] = Pminus[k]/( Pminus[k]+R ) xhat[k] = xhatminus[k]+K[k]*(z[k]-xhatminus[k]) P[k] = (1-K[k])*Pminus[k] plt.figure() plt.plot(z,\'k+\',label=\'noisy measurements\') plt.plot(xhat,\'b-\',label=\'a posteri estimate\') plt.axhline(x,color=\'g\',label=\'truth value\') plt.legend() plt.title(\'Estimate vs. iteration step\', fontweight=\'bold\') plt.xlabel(\'Iteration\') plt.ylabel(\'Voltage\') plt.figure() valid_iter = range(1,n_iter) # Pminus not valid at step 0 plt.plot(valid_iter,Pminus[valid_iter],label=\'a priori error estimate\') plt.title(\'Estimated $\\it{\\mathbf{a \\ priori}}$ error vs. iteration step\', fontweight=\'bold\') plt.xlabel(\'Iteration\') plt.ylabel(\'$(Voltage)^2$\') plt.setp(plt.gca(),\'ylim\',[0,.01]) plt.show()
Result:
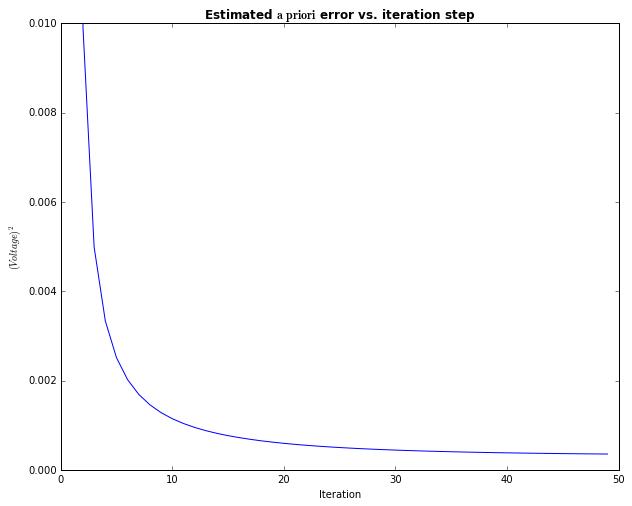
Goto: [OpenCV] Samples 14: kalman filter
其实,真正的Kalman Filter用得是如下理论,上述例子只是教小学生的入门读物。

Goto: https://www.youtube.com/watch?v=UVNeulkWWUM by XU Yida
关键需要理解: http://www.cnblogs.com/rubbninja/p/6220284.html
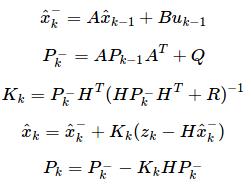

【重点】证明过程的理解关键是:
因为是线性滤波器,本身又具备一个alpha迭代的过程,那么先找出joint distribution,
然后,根据高斯的性质直接得出条件概率,即是Update Rule,这样正好对应于滤波器的alpha迭代过程的形式。
这个条件概率就是关于xt的,也就是最新的状态的概率分布,那么期望也就是miu,就是最新的xt。
大概就是这么个思路,笔记在本本上,具体请看视频。符号比较多,但大体就是如上脉络。
以上是关于[Math] Hidden Markov Model的主要内容,如果未能解决你的问题,请参考以下文章