Pentaho Kettle 6.1连接CDH5.4.0集群
Posted Syn良子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pentaho Kettle 6.1连接CDH5.4.0集群相关的知识,希望对你有一定的参考价值。
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 欢迎转载
最近把之前写的Hadoop MapReduce程序又总结了下,发现很多逻辑基本都是大致相同的,于是想到能不能利用ETL工具来进行配置相关逻辑来实现MapReduce代码自动生成并执行,这样可以简化现有以及之后的一部分工作.于是选取了上手容易并对Hadoop支持的比较成熟的Pentaho Kettle来测试,把一些配置过程和遇到的坑记录下来.
Kettle可以在官网下载到,但是官网会让你注册才能下载而且速度不稳定,所以推荐在这个链接进行下载,各个版本都有,我用的是PDI(Pentaho Data Integration)6.1,需要连接的集群是Hadoop2.6.0-CDH5.4.0.
进入链接里的6.1文件夹直接下载pdi-ce-6.1.0.1-196.zip解压,进入data-integration根目录启动Spoon.bat,等待kettle启动成功.
一.准备工作
在配置PDI连接Bigdata source之前,需要检查下需要连接的source版本和对应的Pentaho的组件是否兼容,如下图
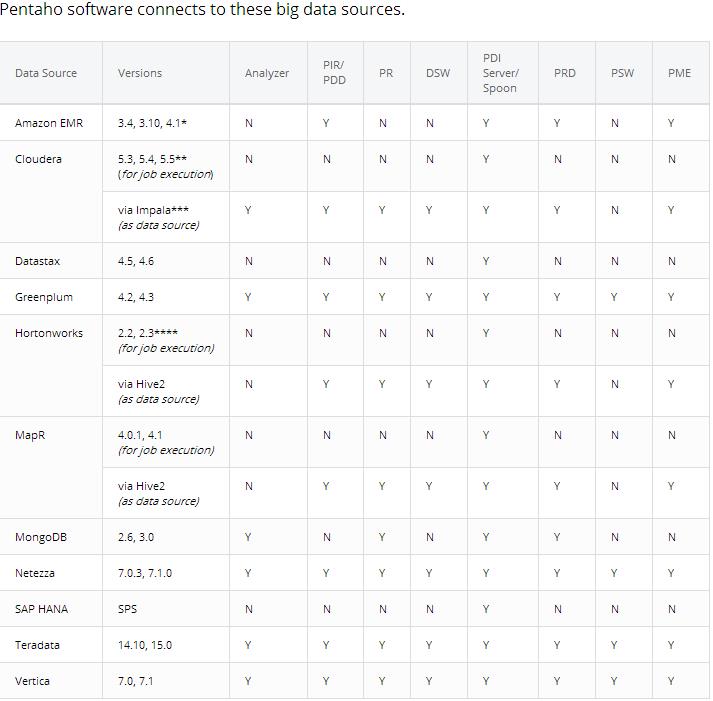
可以看到,之前下载的PDI(上表中属于PDI Spoon),基本上是支持连接CDH,MapR,EMR,HDP等主流数据源的.我连接的集群是CDH5.4,也在支持范围内.
二.配置Pentaho组件Shims
Shims这里我的理解是Pentaho提供的一系列连接各个source的适配器,具体配置位置根据Pentaho的组件来决定,现在的PDI Spoon的配置位置在../data-integration/plugins/pentaho-big-data-plugin/hadoop-configurations 下,注意这个地方要配置好对应数据源的shims,如下图有好几种数据源,

比如我当前连接的是CDH5.4.0,那么我先清空cdh55下的内容,随后下载对应的shims来解压拷贝到该目录下,具体shims下载位置在
https://sourceforge.net/projects/pentaho/files/Big%20Data%20Shims
选择相应的PDI版本进入,下载对应的CDH版本的shims,我需要下载的是 pentaho-hadoop-shims-cdh54-package-61.2016.04.01-196-dist.zip,打开该zip,双击install.bat进行shims解压,将解压后的cdh54目录下的内容全部拷贝到hadoop-configurations下的默认的cdh55文件下里面去(其实cdh55这个应该可以改名为cdh54,但是修改完这个文件夹名称的话,PDI找不到该配置了,应该可以在哪儿设置,暂时没找到,找到的同学可以告诉我).
这个地方一定要下载好对应的shims,否则PDI中即使你配置好正确的CDH连接信息,那么随后在使用过程中也会报各种莫名其妙的错误.
三.编辑Cluster配置文件
完成上一步内容后,进入cdh55目录下,将CDH5.4集群上的hive-site.xml,mapred-site.xml,hbase-site.xml,core-site.xml,hdfs-site.xml,yarn-site.xml等配置文件拷贝到当前目录覆盖.然后进行一些必要的修改.如下
修改hive-site.xml,将hive的metastore修改为和集群保持一致
<property>
<name>hive.metastore.uris</name>
<value>修改为集群的thrift地址</value>
</property>
修改mapred-site.xm,如没有则添加并和集群保持一致
<property>
<name>mapreduce.jobhistory.address</name>
<value>修改为集群的jobhistory地址</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
修改yarn-site.xml对应属性值,如没有则添加并和集群保持一致
<property> <name>yarn.application.classpath</name> <value>$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>clouderamanager.cdh5.test</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>clouderamanager.cdh5.test:8032</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>clouderamanager.cdh5.test:8033</value> </property>
修改config.properties添加如下属性,注意我这里CDH5.4测试用,没有开启Kerberos认证
authentication.superuser.provider=NO_AUTH
如果开启了Kerberos认证,则需要修改更多参数.
四.新建Cluster连接并测试
完成上述配置后,启动Spoon.bat, 进入PDI开发界面.菜单栏中选择Tools->Hadoop Distribution,然后选择Cloudera CDH5.4并点击ok,然后重启PDI.
在左边的View视图下会看到Hadoop clusters然后右键新建Cluster,如下图

配置好对应的集群连接信息(可以参考shims下集群的*.xml配置文件),点击"Test"进行测试,如下
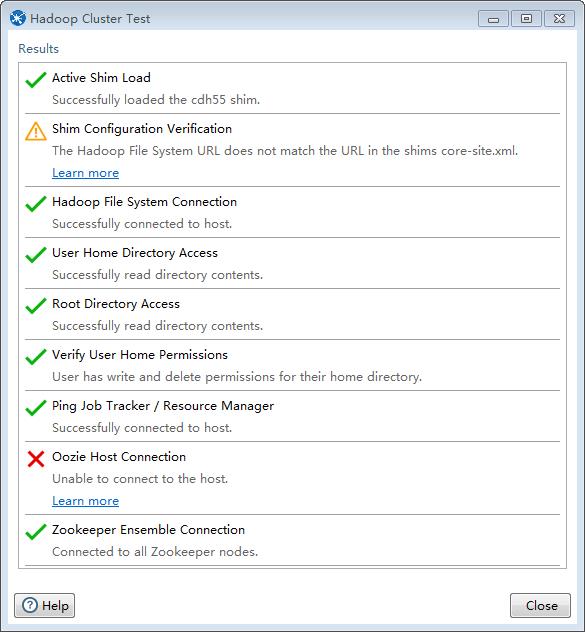
确保所有的结果都变为绿色则表示配置成功,如果有红色肯定是连接信息和集群不一致.
以上是关于Pentaho Kettle 6.1连接CDH5.4.0集群的主要内容,如果未能解决你的问题,请参考以下文章
应用Pentaho Data Integration(Kettle) 6.1 进行数据抽取以及指标计算(同构数据抽取)
Pentaho BIServer Community Edtion 6.1 使用教程 第三篇 发布和调度Kettle(Data Integration) 脚本 Job & Trans(示例代码
Pentaho Kettle 无效的 JNDI 连接无法创建与数据库服务器的连接