内存管理
Posted 黑大米
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了内存管理相关的知识,希望对你有一定的参考价值。
一、内存管理的相关概念
内核把物理页作为内存管理的基本单位。
内核用struct page结构表示系统中的每个物理页。
内核使用区对具有相似特性的页进行分组。
内核把页划分为不同的区,主要使用了四种区:ZONE_DMA、ZONE_DMA32、ZONE_NORMAL、ZONE_HIGHEM。
二、获得页的接口
struct page * alloc_pages(gfp_t gfp_mask, unsigned int order); //该函数分配2的order次方即1<<order个连续的物理页; //并返回一个指针,该指针指向第一个页的page结构体; //如果出错,就返回NULL。 void * page_address(struct page * page); //该函数返回一个指针,指向给定物理页当前所在的逻辑地址。 unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order); //这个函数与alloc_pages()作用相同,不过它直接返回所请求的第一个页的逻辑地址。 struct page * alloc_page(gfp_t gfp_mask); unsigned long __get_free_page(gfp_mask); //这两个函数同上面两个函数工作方式相同,只不过传递给order的值为0,即分配一页。 unsigned long get_zeroed_page(unsigned int gfp_mask); //只分配一页,让其内容填充0,返回指向其逻辑地址的指针。 void __free_pages(struct page * page, unsigned int order); void __free_page(struct page * page); void free_pages(unsigned long addr, unsigned int order); void free_page(unsigned long addr); //释放分配的页
三、kmalloc()
kmalloc()在<linux/slab.h>中声明。
void * kmalloc(size_t size, gfp_t flags); //这个函数返回一个指向内存块的指针,其内存块至少要有size大小; //所分配的内存区在物理上是连续的; //出错时返回NULL void kfree(const void * ptr); //kfree()函数释放由kmalloc()分配出来的内存块。 gfp_mask标志 这些标志可以分为三类:行为修饰符、区修饰符、类型。 行为修饰符表示内核应当如何分配所需的内存。 //例如,中断处理程序就要求内核在分配内存的过程中不能睡眠。 __GFP_WAIT、__GFP_HIGH、__GFP_IO、__GFP_FS、__GFP_COLD、__GFP_NOWARN、 __GFP_REPEAT、__GFP_NOFALL、__GFP_NORETRY、__GFP_NO_GROW、__GFP_COMP 区修饰符表示内存区应当从何处分配。 __GFP_DMA、__GFP_DMA32、__GFP_HIGHMEM 类型标志指定所需的行为和区描述符以完成特殊类型的处理。 内核代码趋向于使用正确的类型标志,而不是一味地指定它可能需要用到的多个描述符。 GFP_ATOMIC、GFP_NOWAIT、GFP_NOIO、GFP_NOFS、GFP_KERNEL、GFP_USER、GFP_HIGHUSER、GFP_DMA
四、vmalloc()
vmalloc()函数声明在<linux/vmalloc.h>中,定义在<mm/vmalloc.c>中。
用法与用户空间的malloc()相同。
注意:vmalloc()函数的工作方式类似于kmalloc(),只不过前者分配的内存虚拟地址是连续的,而物理地址则无需连续。
void * vmalloc(unsigned long size); //返回一个指针,指向逻辑上连续的一块内存区,其大小至少为size。 //函数可能睡眠 void free(const void *addr); //释放通过vmalloc()函数分配的内存
五、slab层
slab分配器扮演了通用数据结构缓冲层的角色。
slab层把不同的对象划分为所谓高速缓冲组,其中每个高速缓冲都存放不同类型的对象。
slab由一个或多个物理上连续的页组成。一般情况下仅由一页组成。
每个slab处于三种状态之一:满、部分满、空。
每种对象类型对应一个高速缓存;
每个高速缓存可以由多个slab组成;
每个slab都包含一些对象成员,这里的对象指的是被缓存的数据结构。
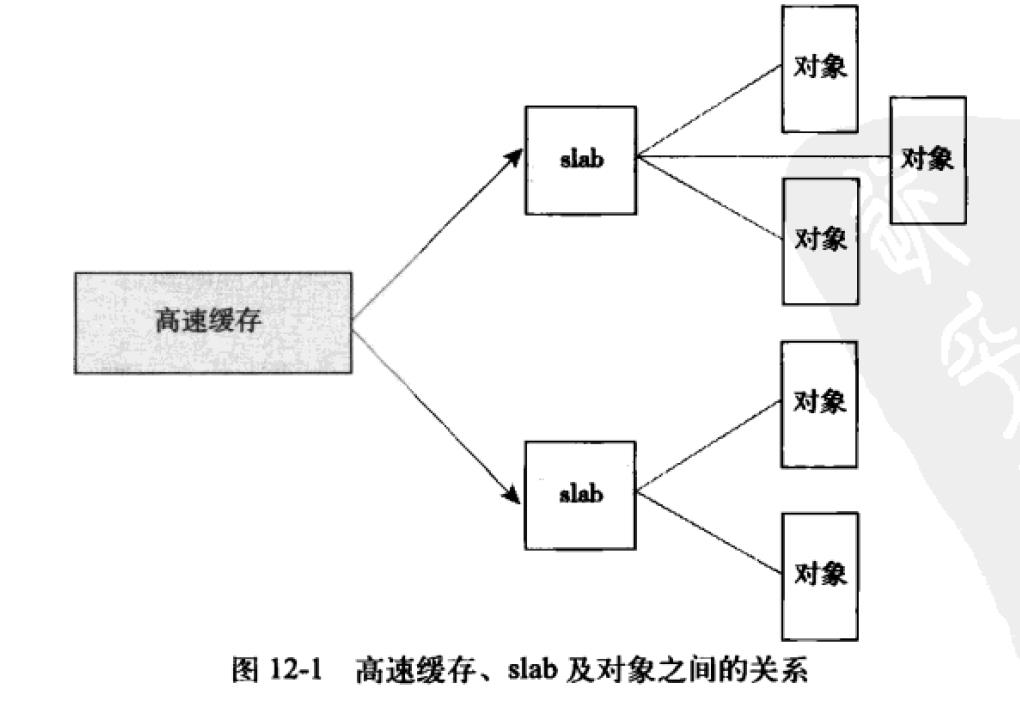
高速缓存使用struct kmem_cache结构表示;
slab描述符struct slab用来描述每个slab。
接口函数: struct kmem_cache * kmem_cache_create(const char * name, size_t size, size_t align, unsigned long flags, void (*ctor) (void *)); //第一个参数是一个字符串,存放着高速缓存的名字; //第二个参数是高速缓存中每个元素的大小; //第三个参数是slab内第一个对象的偏移,它用来确保在页内进行特定的对齐。通常0就可以满足。 //第四个参数是可选的设置项,用来控制高速缓存的行为。可以为0,表示没有特殊的行为。 //或者以下标志中的一个或多个进行“或”运算: //SLAB_HWCACHE_ALIGN 把一个slab内的所有对象按高速缓存行对齐。 //SLAB_POISON 用已知的值(a5a5a5a5)填充slab。 //SLAB_RED_ZONE 在已分配的内存周围插入“红色警戒区”以探测缓冲越界。 //SLAB_PANIC 当分配失败时提醒slab层。 //SLAB_CACHE_DMA 使用可以执行DMA的内存给每个slab分配空间。 //第五个参数是高速缓存的构造函数。由于内核代码并不需要它,因此已经被抛弃了。 注意:该函数可以引起睡眠。 int kmem_cache_destroy(struct kmem_cache * cachep); //撤销给定的高速缓存。 注意:该函数也可能睡眠。 void * kmem_cache_alloc(struct kmem_cache * cachep, gfp_t flags); //从给定的高速缓存cachep中返回一个指向对象的指针。 void * kmem_cache_free(struct kmem_cache * cachep, void * objp); //释放一个对象,并把它返回给原先的slab。
六、高端内存的映射
1.高端内存的映射
void * kmap(struct page * page);
//映射一个给定的page结构到内核地址空间;这个函数在高端内存或低端内存上都能用。
//这个函数可以睡眠
void kunmap(struct page * page);
//接触映射。允许永久映射的数量是有限的,当不再需要高端内存时,应该解除映射。
2.临时映射
void * kmap_atomic(struct page * page, enum km_type type);
void kunmap_atomic(void * kvaddr, enum km_type type);
//建立和取消一个临时映射,这两个函数不会导致睡眠。
enum km_type{
KM_BOUNCE_READ,
KM_SKB_SUNRPC_DATA,
KM_SKB_DATA_SOFTIRQ,
KM_USER0,
KM_USER1,
KM_BIO_SRC_IRQ,
KM_BIO_DST_IRQ,
KM_PTE0,
KM_PTE1,
KM_PTE2,
KM_IRQ0,
KM_IRQ1,
KM_SOFTIRQ0,
KM_SOFTIRQ1,
KM_SYNC_ICACHE,
KM_SYNC_DCACHE,
KM_UML_USERCOPY,
KM_IRQ_PTE,
KM_NMI,
KM_NMI_PTE,
KM_TYPE_NR
};
七、每个CPU的分配
1.自己创建的方法 unsigned long my_percpu[NR_CPUS]; int cpu; cpu = get_cpu(); //获得当前处理器,并禁止内核抢占 my_percpu[cpu]++; //对每个CPU的数据进行处理 put_cpu(); //激活内核抢占 2.新的每个CPU接口 编译时的每个CPU数据 DEFINE_PER_CPU(type, name); //定义每个CPU变量 DECLARE_PER_CPU(type, name); //在别处声明变量,以供其他地方使用。 get_cpu_var(name)++; //返回当前处理器上的指定变量,同时禁止抢占;并对其执行++ 操作 put_cpu_var(name); //重新激活抢占 per_cpu(name, cpu) ++; //增加指定处理器上的name变量的值 运行时的每个CPU数据 void * alloc_percpu(type); void * __alloc_percpu(size_t size, size_t align); void free_percpu(const void * ); 例如: struct rabid_cheetah ptr = alloc_percpu(struct rabid_cheetah); 等价于 struct rabid_cheetah ptr = __alloc_percpu(sizeof(struct rabid_cheetah), __alignof__(struct rabid_cheetah)); __alignof__是gcc的一个功能,它会返回指定类型所需的对齐字节数。它的语义和sizeof一样。 get_cpu_var(ptr); 返回了一个指向当前处理器数据的特殊实例,同时禁止内核抢占。 put_cpu_var(ptr); 重新激活内核抢占。 使用例子: void *percpu_ptr; unsigned long * foo; percpu_ptr = alloc_percpu(unsigned long); if(!percpu_ptr) /*内存分配错误*/ foo = get_cpu_var(percpu_ptr); /*操作foo*/ put_cpu_var(percpu_ptr); free_precpu(percpu_ptr);
以上是关于内存管理的主要内容,如果未能解决你的问题,请参考以下文章
java内存流:java.io.ByteArrayInputStreamjava.io.ByteArrayOutputStreamjava.io.CharArrayReaderjava.io(代码片段