Velocity工作原理解析和优化
Posted wade&luffy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Velocity工作原理解析和优化相关的知识,希望对你有一定的参考价值。
在MVC开发模式下,View离不开模板引擎,在Java语言中模板引擎使用得最多是JSP、Velocity和FreeMarker,在MVC编程开发模式中,必不可少的一个部分是V的部分。V负责前端的页面展示,也就是负责生产最终的html,V部分通常会对应一个编码引擎,当前众多的MVC框架都已经可以将V部分独立开来,可以与众多的模板引擎集成。
Velocity总体架构
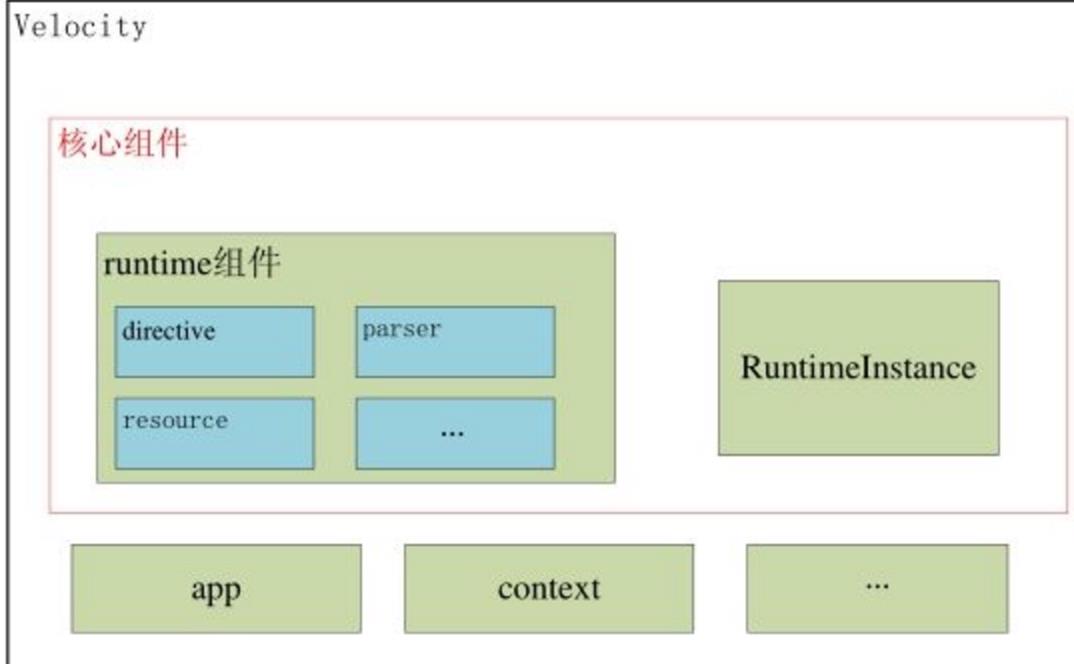
从代码结构上看,Velocity主要分为app、context、runtime和一些辅助util几个部分。
APP模块
其中app主要封装了一些接口,暴露给使用者使用。主要有两个类,分别是Velocity(单例)和VelocityEngine。
前者主要封装了一些静态接口,可以直接调用,帮助你渲染模板,只要传给Velocity一个模板和模板中对应的变量值就可以直接渲染。
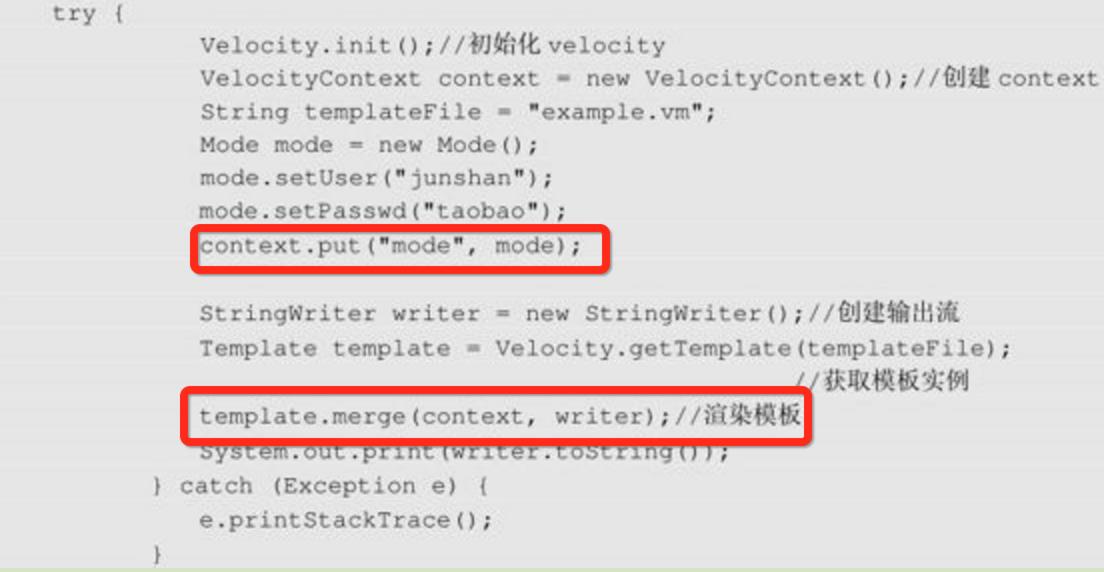
VelocityEngine类主要是供一些框架开发者调用的,它提供了更加复杂的接口供调用者选择,MVC框架中初始化一个VelocityEngine:
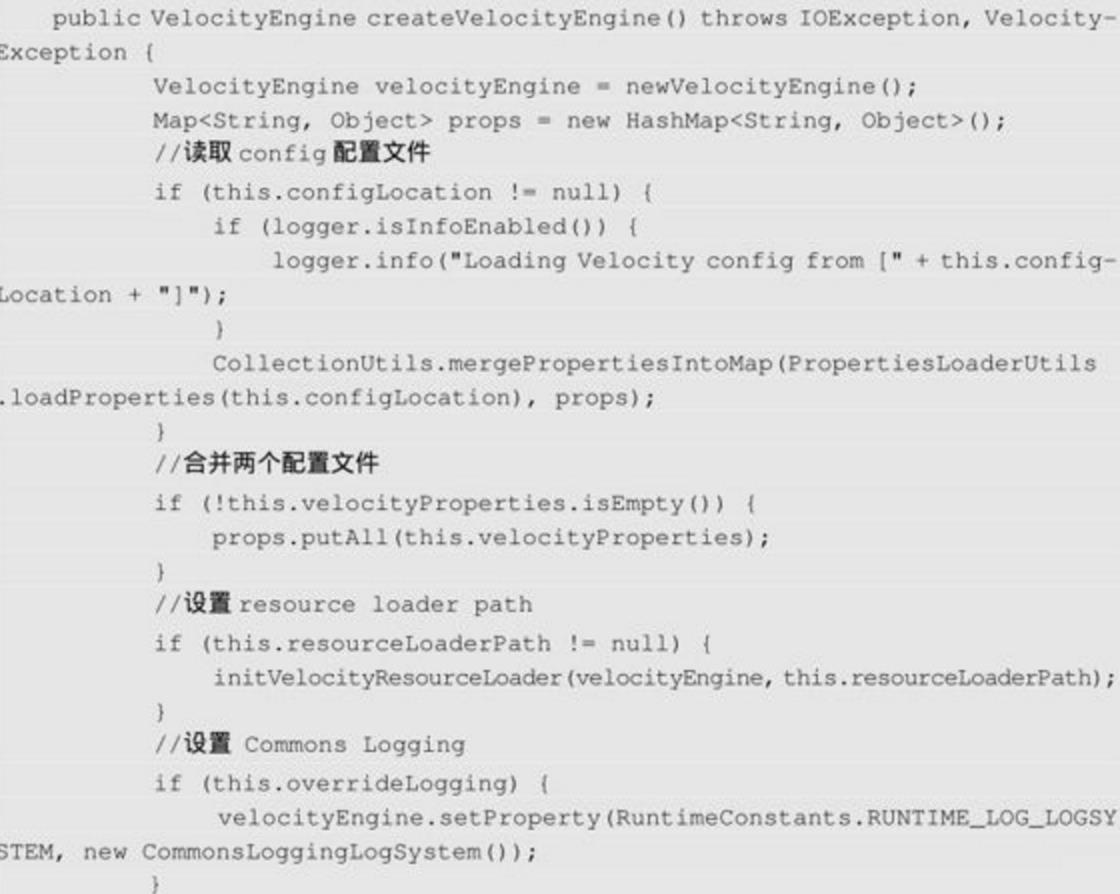

以上是Spring MVC创建Velocity模板引擎的VelocityEngine实例的代码段,先创建一个VelocityEngine实例,再将配置参数设置到VelocityEngine的Property中,最终调用init方法初始化。
Context模块
Context模块主要封装了模板渲染需要的变量,它的主要作用有两点:
- 便于与其他框架集成,起到一个适配器的作用,如MVC框架内部保存的变量往往在一个Map中,这样MVC框架就需要将这个Map适配到Velocity的context中。
- Velocity内部做数据隔离,数据进入Velocity的内部的不同模块需要对数据做不同的处理,封装不同的数据接口有利于模块之间的解耦。
Context类是外部框架需要向Velocity传输数据必须实现的接口,具体实现时可以集成抽象类AbstractContext,例如,Spring MVC中直接继承了VelocityContext,调用构造函数创建Velocity需要的数据结构。
另外一个接口InternetEventContext主要是为扩展Velocity事件处理准备的数据接口,当你扩展了事件处理、需要操作数据时可以实现这个接口,并且处理你需要的数据。
Runtime模块
整个Velocity的核心模块在runtime package下,这里会将加载的模板解析成JavaCC语法树,Velocity调用mergeTemplate方法时会渲染整棵树,并输出最终的渲染结果。
RuntimeInstance类
RuntimeInstance类为整个Velocity渲染提供了一个单例模式,它也是Velocity的一个门面,封装了渲染模板需要的所有接口,拿到了这个实例就可以完成渲染过程了。它与VelocityEngine不同,VelocityEngine代表了整个Velocity引擎,它不仅包括模板渲染,还包括参数设置及数据的封装规则,RuntimeInstance仅仅代表一个模板的渲染状态。
JJTree渲染过程解析
下面是一段Velocity的模板代码vm和这段代码解析成的语法树:
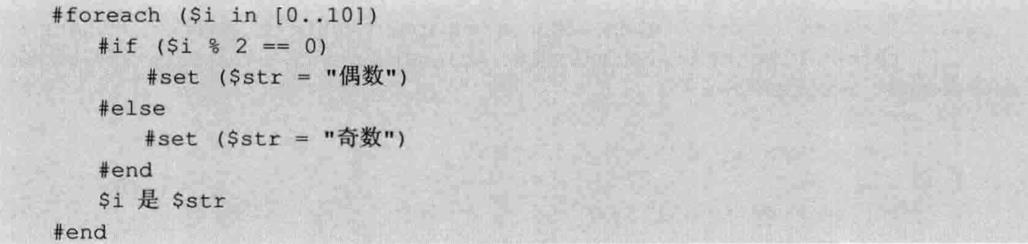
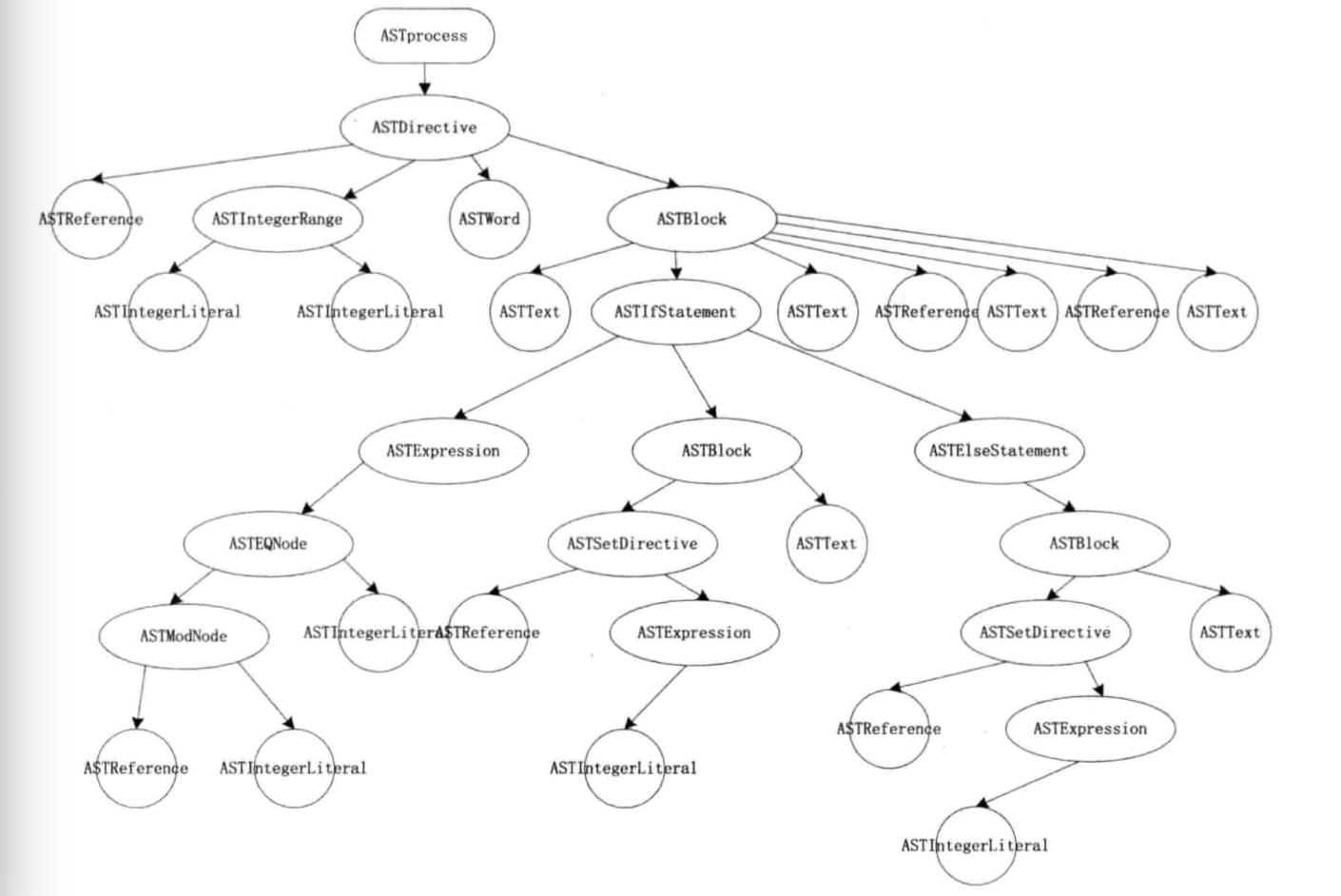
Velocity渲染这段代码将从根节点ASTproces开始,按照深度优先遍历算法开始遍历整棵树,遍历的代码如下所示:

如代码所示,依次执行当前节点的所有子节点的render方法,每个节点的渲染规则都在render方法中实现,对应到上面的vm代码,#foreach节点对应到ASTDirective。这种类型的节点是一个特殊的节点,它可以通过directiveName来表示不同类型的节点,目前ASTDirective已经有多个,如#break、#parse、#include、#define等都是ASTDirective类型的节点。这种类型的节点通常都有一个特点,就是它们的定义类似于一个函数的定义,一个directiveName后面跟着一对括号,括号里含有参数和一些关键词,如#foreach,directiveName是foreach,括号中的$i是ASTReference类型,in是关键词ASTWord类型,[1 ..10]是一个数组类型ASTIntegerRange,在#foreach和#end之间的所有内容都由ASTBlock表示。
所谓的指令指的就是在页面上能用一些类似标签的东西。Velocity默认的指令文件位置在org/apache/velocity/runtime/defaults/directive.properties。
在这个文件中定义了一些默认的指令,例如:
directive.1=org.apache.velocity.runtime.directive.Foreach
directive.2=org.apache.velocity.runtime.directive.Include
directive.3=org.apache.velocity.runtime.directive.Parse
directive.4=org.apache.velocity.runtime.directive.Macro
directive.5=org.apache.velocity.runtime.directive.Literal
directive.6=org.apache.velocity.runtime.directive.Evaluate
directive.7=org.apache.velocity.runtime.directive.Break
directive.8=org.apache.velocity.runtime.directive.Define
我们在vm文件中可以直接使用foreach等指令来让我们的页面更加的灵活。
Velocity的语法相对简单,所以它的语法节点并不是很多,总共有50几个,它们可以划分为如下几种类型。
- 块节点类型:主要用来表示一个代码块,它们本身并不表示某个具体的语法节点,也不会有什么渲染规则。这种类型的节点主要由ASTReference、ASTBlock和ASTExpression等组成。
- 扩展节点类型:这些节点可以被扩展,可以自己去实现,如我们上面提到的#foreach,它就是一个扩展类型的ASTDirective节点,我们同样可以自己再扩展一个ASTDirective类型的节点。
- 中间节点类型:位于树的中间,它的下面有子节点,它的渲染依赖于子节点才能完成,如ASTIfStatement和ASTSetDirective等。
- 叶子节点:它位于树的叶子上,没有子节点,这种类型的节点要么直接输出值,要么写到writer中,如ASTText和ASTTrue等。
Velocity读取vm模板根据JavaCC语法分析器将不同类型的节点按照上面的几个类型解析成一个完整的语法树。
在调用render方法之前,Velocity会调用整个节点树上所有节点的init方法来对节点做一些预处理,如变量解析、配置信息获取等。这非常类似于Servlet实例化时调用init方法。Velocity在加载一个模板时也只会调用init方法一次,每次渲染时调用render方法就如同调用Servlet的service方法一样。
#set语法
#set语法可以创建一个Velocity的变量,#set语法对应的Velocity语法树是ASTSetDirective类,翻开这个类的代码,可以发现它有两个子节点:分别是RightHandSide和LeftHandSide,分别代表“=”两边的表达式值。与Java语言的赋值操作有点不一样的是,左边的LeftHandSide可能是一个变量标识符,也可能是一个set方法调用。变量标识符很好理解,如前面的#set($var=“偶数”),另外是一个set方法调用,如#set($person.name=”junshan”),这实际上相当于Java中person.setName(“junshan”)方法的调用。
#set语法如何区分左边是变量标识符还是set方法调用?看一下ASTSetDirective类的render方法:
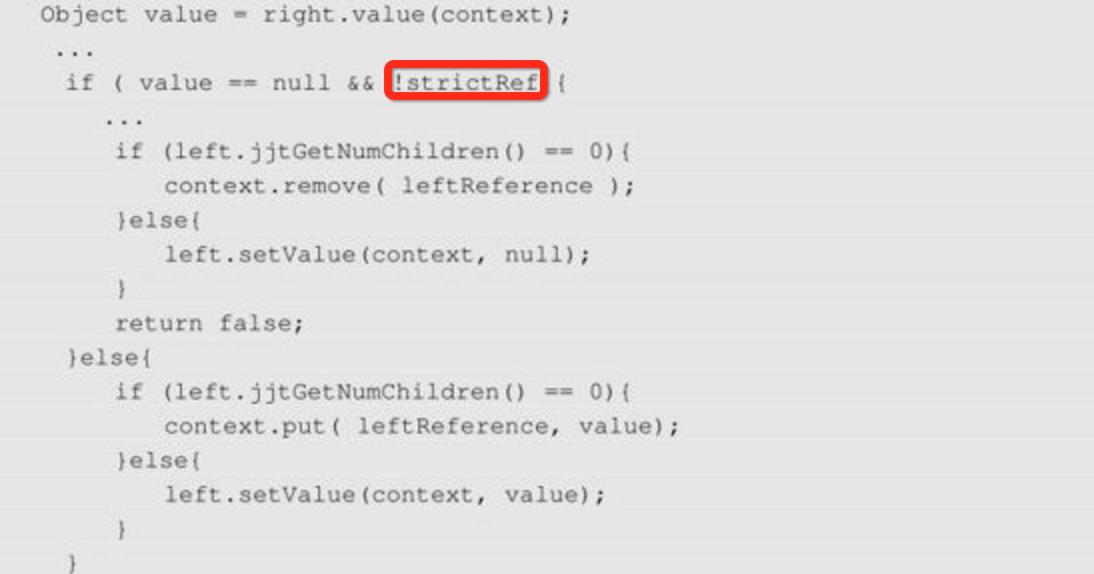
从代码中可以看到,先取得右边表达式的值,然后根据左边是否有子节点判断是变量标识符还是调用set方法。通过#set语法创建的变量是否有有效范围,从代码中可以看到会将这个变量直接放入context中,所以这个变量在这个vm模板中是一直有效的,它的有效范围和context也是一致的。所以在vm模板中不管在什么地方通过#set创建的变量都是一样的,它对整个模板都是可见的。
Velocity的方法调用
Velocity的方法调用方式有多种,它和我们熟悉的Java的方法调用还是有一些区别之处的,如果你不熟悉,可能会产生一些误解,下面举例介绍一下。
Velocity通过ASTReference类来表示一个变量和变量的方法调用,ASTReference类如果有子节点,就表示这个变量有方法调用,方法调用同样是通过“.”来区分的,每一个点后面会对应一个方法调用。ASTReference有两种类型的子节点,分别是ASTIdentifier和ASTMethod。它们分别代表两种类型的方法调用,其中ASTIdentifier主要表示隐式的“get”和“set”类型的方法调用。而ASTMethod表示所有其他类型的方法调用,如所有带括号的方法调用都会被解析成ASTMethod类型的节点。
所谓隐式方法调用在Velocity中通常有如下几种。
1.Set类型,如#set($person.name=”junshan”),如下:
- person.setName(“junshan”)
- person.setname(“junshan”)
- person.put(“name”,”junshan”)
2.Get类型,如#set($name=$person.name)中的$person.name,如下:
- person.getName()
- person.getname()
- person.get(“name”)
- person.isname()
- person.isName()
Get&Set反射调用
Set 继承SetExecutor:当Velocity在解析#set($person.name=”junshan”)时,它会找到$person对应的对象,然后创建一个SetPropertyExecutor对象并查找这个对象是否有setname(String)方法,如果没有,再查找setName(String)方法,如果再没有,那么再创建MapSetExecutor对象,看看$person对应的对象是不是一个Map。如果是Map,就调用Map的put方法,如果不是Map,再创建一个PutExecutor对象,检查一下$person对应的对象有没有put(String)方法,如果存在就调用对象的put方法。
Get:除去Set类型的方法调用,其他的方法调用都继承了AbstractExecutor类,如#set($name=$person.name)中解析$person.name时,创建PropertyExecutor对象封装可能存在的getname(String)或getName(String)方法。否则创建MapGetExecutor检查$person变量是否是一个Map对象。如果不是,创建GetExecutor对象检查$person变量对应的对象是否有get(“Name”)方法。如果还没有,创建BooleanPropertyExecutor对象并检查$person变量对应的对象是否有isname()或者isName()方法。找到对应的方法后,将相应的java.lang.reflect.Method对象封装在对应的封装对象中。
以上这些查找顺序中,某个方法找到后就直接返回某种类型的Executor对象包装的Method,然后通过反射调用Method的invoke方法。Velocity的反射调用是通过Introspector类来完成的,它定义了类对象的方法查找规则。
显式调用:除去以上对两种隐式的方法调用的封装外,Velocity还有一种简单的方法调用方式,就是带有括号的方法调用,如$person.setName(“junshan”),这种精确的方法调用会直接查找变量$person对应的对象有没有setName(String)方法,如果有,会直接返回一个VelMethod对象,这个对象是对通用的方法调用的封装,它可以处理$person对应的对象是数组类型或静态类时的情况。数组的情况如string=newString[]{“a”,”b”,”c”},要取的第二个值在Java中可以通过string[1]来取,但在Velocity中可以通过$string.get(1)取得数组的第二个值。为何能这样做呢?可以看一下Velocity中相应的代码:
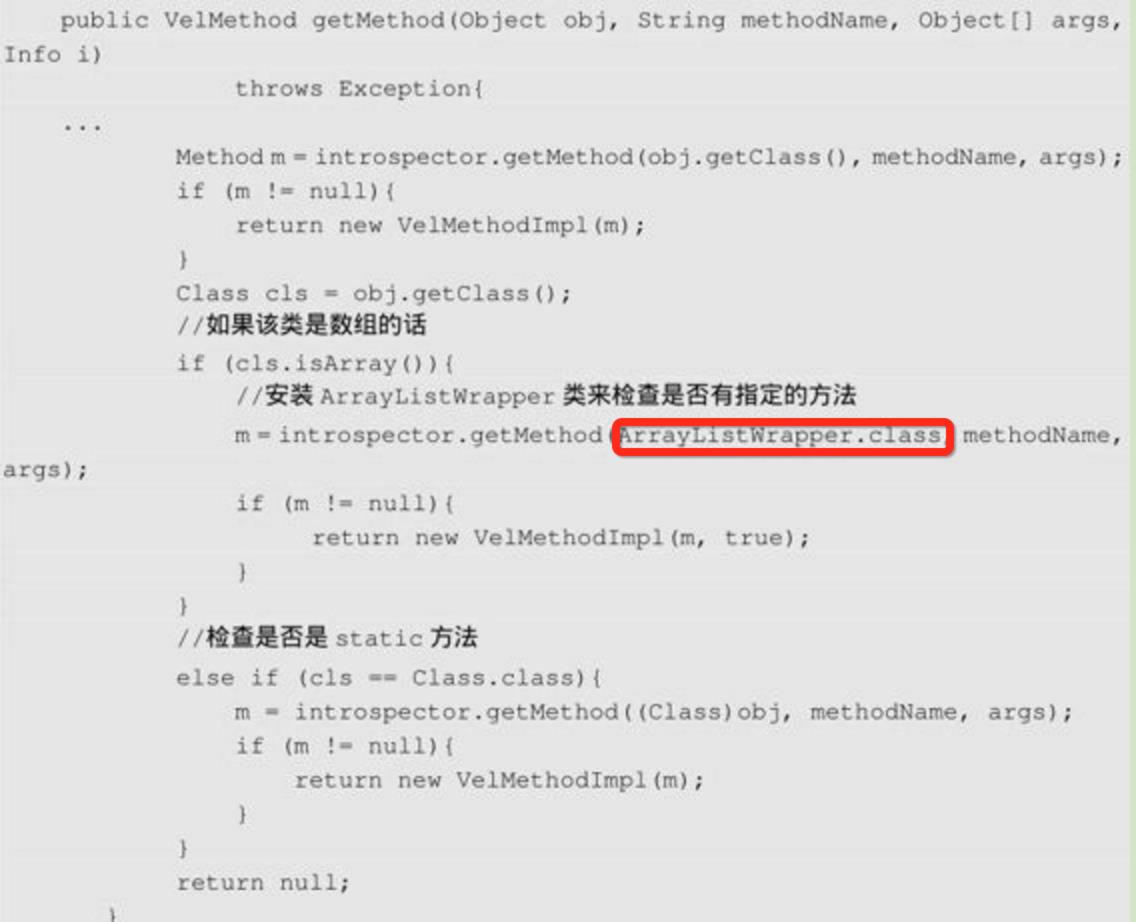
从上面的代码中我们可以发现,精确查找方法的规则是查找$person对应的对象是否有指定的方法,然后检查该对象是否是数组,如果是数组,把它封装成List,然后按照ArrayListWrapper类去代理访问数组的相应值。如果$person对应的对象是静态类,可以调用其静态方法。
#if、#elseif和#else语法
#if和#else节点是Velocity中的逻辑判断节点,它的语法规则几乎和Java是一样的,主要的不同点在条件判断上,如Velocity中判断#if($express)为true的情况是只要$express变量的值不为null和false就行,而Java中显然不能这样判断。
除单个变量的值判断之外,Velocity还支持Java的各种表达式判断,如“>”、“<”、“==”和逻辑判断“&&”、“||”等。每一个判断条件都会对应一个节点类,如“==”对应的类为ASTEQNode,判断两个值是否相等的条件为:先取得等号两边的值,如果是数字,比较两个数字的大小是否相等,再判断两边的值是否都是null,都为null则相等,否则其中一个为null,肯定不等;再次就是取这两个值的toString(),比较这两个值的字符值是否相等。值得注意的是,Velocity中并不能像Java中那样判断两个变量是否是同一个变量,也就是object1==object2与object1. equals(object2)在Velocity中是一样的效果。
特别要注意的是,很多人在写Velocity代码时有类似这样的写法,如#if("$example.user"== "null")和#if("$example.flag" == "true"),这些写法都是不正确的,正确的写法是#if($example.user)和#if($example.flag)。
若要使用 #ifnull() 或 #ifnotnull(), 要使用#ifnull ($foo)这个特性必须在velocity.properties文件中加入:
userdirective = org.apache.velocity.tools.generic.directive.Ifnull
userdirective = org.apache.velocity.tools.generic.directive.Ifnotnull
如果有多个#elseif节点,Velocity会依次判断每个子节点,从#if节点的render方法代码中我们可以看出,第一个子节点就是#if中的表达式判断,这个表达式的值为true则执行第二个子节点,第二个子节点就是#if下面的代码块。如果#if中表达式判断为false,则继续执行后面的子节点,如果存在其他子节点肯定就是#elseif或者#else节点了,其中任何一个为true将会执行这个节点的render方法并且会直接返回。
#foreach语法
Velocity中的循环语法只有这一种,它与Java中的for循环的语法糖形式十分类似,如#foreach($child in $person.children) $person.children表示的是一个集合,它可能是一个List集合或者一个数组,而$child表示的是每个从集合中取出的值。从render方法代码中可以看出,Velocity首先是取得$person.children的值,然后将这个值封装成Iterator集合,然后依次取出这个集合中的每一个值,将这个值以$child为变量标识符放入context中。除此以外需要特别注意的是,Velocity在循环时还在context中放入了另外两个变量,分别是counterName和hasNextName,这两个变量的名称分别在配置文件配置项directive.foreach.counter.name和directive.foreach.iterator.name中定义,它们表示当前的循环计数和是否还有下一个值。前者相当于for(int i=1;i<10;i++)中的i值,后者相当于while(it.hasNext())中的it.hasNext()的值,这两个值在#foreach的循环体中都有可能用到。由于elementKey、counterName和hasNextName是在#foreach中临时创建的,如果当前的context中已经存在这几个变量,要把原始的变量值保存起来,以便在这个#foreach执行结束后恢复。如果context中没有这几个变量,那么#foreach执行结束后要删除它们,这就是代码最后部分做的事情,这与我们前面介绍的#set语法没有范围限制不同,#foreach中临时产生的变量只在#foreach中有效。
#parse语法
#parse语法也是Velocity中十分常用的语法,它的作用是可以让我们对Velocity模板进行模块化,可以将一些重复的模块抽取出来单独放在一个模板中,然后在其他模板中引入这个重用的模板,这样可以增加模板的可维护性。而#parse语法就提供了引入一个模板的功能,如#parse(‘head.vm’)引入一个公共页头。当然head.vm可以由一个变量来表示。#parse和#foreach一样都是通过扩展节点ASTDirective来解析的,所以#parse和#foreach一样都共享当前模板执行环境的上下文。虽然#parse是单独一个模板,但是这个模板中变量的值都在#parse所在的模板中取得。Velocity中的#parse我们可以仅理解为只是将一段vm代码放在一个单独的模板中,其他没有任何变化。 从代码中可以看出执行分为三部分,首先取得#parse(‘head.vm’)中的head.vm的模板名,然后调用getTemplate获取head.vm对应的模板对象,再调用该模板对应的整个语法树的render方法执行渲染。#parse语法的执行和其他的模板的渲染没有什么区别,只不过模板渲染时共用了父模板的context和writer对象而已。
事件处理机制
Velocity的事件处理机制所涉及的类在org.apache.velocity.app.event下面, EventHandler是所有类的父接口,EventHandler类有5个子类,分别代表5种不同的事件处理类型。
- ReferenceInsertionEventHandler:表示针对Velocity中变量的事件处理,当Velocity在渲染输出某个“$”表示的变量时可以对这个变量做修改,如对这个变量的值做安全过滤以防止恶意JS代码出现在页面中等。
- NullSetEventHandler:顾名思义是对#set语法赋值为null时的事件做处理。
- MethodExceptionEventHandler:这个事件是对Velocity在反射执行某个方法调用时出错后,有机会做一些处理,如捕获异常、控制返回一些特殊值等。
- InvalidReferenceEventHandler:表示Velocity在解析“$”变量出现没有找到对应的对象时做如何处理。
- IncludeEventHandler:在处理#include和#parse时提供了处理和修改加载外部资源的机会。
Velocity提供的这些事件处理机制也为我们扩展Velocity提供了机会,如果你想扩展Velocity,必须对它的事件处理机制有很好的理解。
如何调用到扩展的EventHandler?Velocity提供了两种方式,Velocity在渲染时遇到符合的事件都会检查以下的EventCartridge:
- 把你新创建的EventHandler直接加到org.apache.velocity.runtime.RuntimeInstance类的eventCartridge属性中,直接将自定义的EventHandler通过配置项eventCartridge.classes来设置,Velocity在初始化RuntimeInstance时会解析配置项,然后会实例化EventHandler。
- 把自定义的EventHandler加到自己创建的EventCartridge对象中,然后在渲染时把这个EventCartridge对象通过调用attachToContext方法加到context中,但是这个context必须要继承InternalEventContext接口,因为只有这个接口才提供了attachToContext方法和取得EventCartridge的getEventCartridge方法。动态地设置EventHandler,只要将EventHandler加到渲染时的context中,Velocity在渲染时就能调用它。
EventCartridge中保存了所有的EventHandler,并且EventCartridge把它们分别保存在5个不同的属性集合中,分别是referenceHandlers、nullSetHandlers、methodExceptionHandlers、includeHandlers和invalidReferenceHandlers。如何找到EventHandle?Velocity在渲染时分别在两个地方检查可能存在的EventHandler,那就是RuntimeInstance对象和渲染时的context对象,这两个对象在Velocity渲染时随时都能访问到。何时被触发?有一个类EventHandlerUtil,它就负责在合适的事件触发时调用事件处理接口来处理事件。如变量在输出到页面之前会调用value = EventHandlerUtil.referenceInsert(rsvc, context, literal(), value)来检查是否有referenceHandlers需要调用。其他事件也是类似处理方式。
ps:
扩展Velocity的事件处理会涉及对Context的处理,Velocity增加了一个ContextAware接口,如果你实现的EventHandler需要访问Context,那么可以继承这个接口。Velocity在调用EventHandler之前会把渲染时的context设置到你的EventHandler中,这样你就可以在EventHandler中取到context了。如果要访问RuntimeServices对象,同样可以继承RuntimeServicesAware接口。
Velocity还支持另外一种扩展方式,就是在渲染某个变量的时候判断这个变量是不是Renderable类的实例,如果是,将会调用这个实例的render( InternalContextAdapter context, Writer writer)方法,这种调用是隐式调用,也就是不需要在模板中显式调用render()方法。
优化的理论基础
程序的语言层次结构和这个语言的执行效率形成一对倒立的三角形结构。从图中可以看出,越是上层的高级语言,它的执行效率往往越低。这很好理解,因为最底层的程序语言只有计算机能明白,与人的思维很不接近,为什么我们开发出这么多上层语言,很重要的目的就是对底层的程序做封装,使得我们开发更方便,很显然这些经过重重封装的语言的执行效率肯定比没有经过封装的底层程序语言的效率要差很多,否则和硬件相关的驱动程序也不会用C语言或汇编语言来实现了。
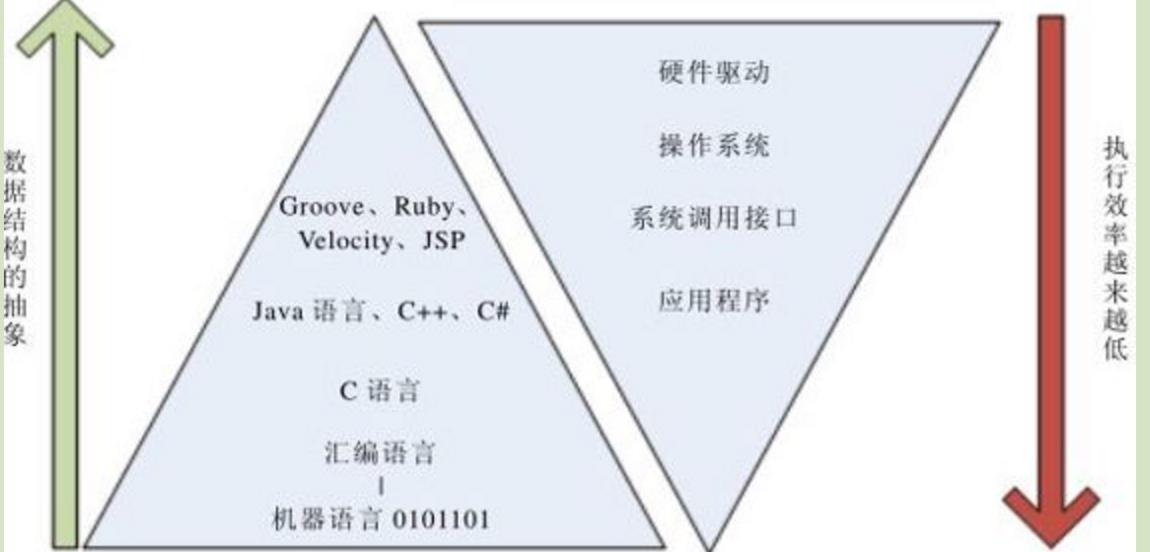
数据结构减少抽象化
程序的本质是数据结构加上算法,算法是过程,而数据结构是载体。程序语言也是同样的道理,越是高级的程序语言必然数据结构越抽象化,这里的抽象化是指它们的数据结构与人的思维越接近。有些语言(如Python)的语法规则非常像我们的人语言,即使没有学过编程的人也很容易理解它。这里所说的数据结构去抽象化是指把需要调用底层的接口的程序改由我们自己去实现,减少这个程序的封装程度,从而达到提升性能的目的,所以并不是改变程序语法。
简单的程序复杂化
先举一个例子,我们想从数据库中去掉一行数据,目前的环境中已经有人提高了一个调数据库查询的接口,这个接口的实现使用了iBatis作为数据层调用数据库查询数据,实际上它封装了对象与数据字段的关系映射及管理数据库连接池等。使用起来很方便,但是它的执行效率是不是比我们直接写一个简单的JDBC连接、提交一个SQL语句的效率高呢?很显然,后面的执行效率更高,抛去其他因素,显然没有经过封装的复杂程序要比简单的调用上层接口效率要高很多。所以我们要做的就是适当地让我们的程序复杂一点,而不要偷懒,也许这样我们的程序效率会增加不少。
减少翻译的代价
我们知道与不同国家的人交流是要通过翻译的,但是这个翻译实在是耗时间。程序设计同样存在翻译的问题,如我们的编码问题,美国人的所有字符一个字节就能全部表示,所以他们的所有字符就是一个字节,也就是一个ASSCII码,所以对他们来说不存在字符编码问题,但是对其他国家的程序员来说,不得不面临一个让人头疼的字符编码问题,需要将字节与字符之间来回翻译,而且还很容易出现错误。我们要尽量减少这种翻译,至少在真正与人交流时把一些经常用的词汇提前就翻译好,从而在面对面交流时减少需要翻译的词汇的数量,从而提升交流效率。
变的转化为不变
现在的网页基本上都是动态网页,但是所谓的动态网页中仍然有很多静态的东西,如模板中仍然有很多是HTML代码,它们和一些变量共同拼接成一个完整的页面,但是这些内容从程序员写出来到最终在浏览器里渲染,都是一成不变的。既然是不变的,那么就可以对它们做一些预处理,如提前将它们编码或者将它们放到CDN上。另外,尽量把一些变化的内容转化成不变的内容,如我们可能将一个URL作为一个变量传给模板去渲染,但是这个URL中真正变化的仅仅是其中的一个参数,整个主体肯定是不会变化的,所以我们仍然可以从变化的内容中分离出一部分作为不变的来处理。这些都是细节,但是当这些细节组合在一起时往往就会带来让你意想不到的好的结果。
常用优化技巧
Velocity渲染模板是先把模板解析成一棵语法树,然后去遍历这棵树分别渲染每个节点,知道了它的工作原理,我们就可以根据它的工作机制来优化渲染的速度。既然是遍历这棵树来渲染节点的,而且是顺序遍历的,那么很容易想到有两种办法来优化渲染:
- 减少树的总节点数量。
- 减少渲染耗时的节点数量。
- 改变Velocity的解释执行,变为编译执行。
- 方法调用的无反射优化
- 字符输出改成字节输出
- 去掉页面输出中多余的非中文空格。我们知道,页面的HTML输出中多余的空格是不会在HTML的展示时有作用的,多个连续的空格最终都只会显示一个空格的间距,除非你使用“ ”表示空格。虽然多余的空格并不能影响HTML的页面展示样式,但是服务端页面渲染和网络数据传输这些空格和其他字符没有区别,同样要做处理,这样的话,这些空格就会造成时间和空间维度上的浪费,所以完全可以将多个连续的空格合并成一个,从而既减少了字符又不会影响页面展示。
- 压缩TAB和换行。同样的道理,还可以将TAB字符合并成一个,以及将多余的换行也合并一下,也能减少不少字符。
- 合并相同的数据。在模板中有很多相同数据在循环中重复输出,如类目、商品、菜单等,可以将相同的重复内容提取出来合并在CSS中或者用JS来输出。
- 异步渲染。将一些静态内容抽取出来改成异步渲染,只在用户确实需要时再向服务器去请求,也能够减少很多不必要的数据传输。
减少树的总节点数量
既然一个模板输出的内容是确定的,那么这个模板的vm代码应该是固定的,减少节点数量必然删去一部分vm代码才能做到?其实并不是这样的,虽然最终渲染出来的页面是一样的,但是vm的写法却有很大不同,笔者在检查vm代码时遇到很多不优美的写法,导致无谓增加了很多不必要的语法节点。如下面一段代码:

这段代码实际上只是要计算一个值,但是由于不熟悉Velocity的一些语法,写得很麻烦,其实只要一个表达式就好了,如下:
![]()
这样可以减少很多语法节点。
减少渲染耗时的节点数量
Velocity的方法调用是通过反射执行的,显然反射执行方法是耗时的,那么又如何减少反射执行的方法呢?这个改进就如同Java中一样,可以增加一些中间变量来保存中间值,而减少反射方法的调用。如在一个模板中要多次调用到$person.name,那么可以通过#set创建一个变量$name来保存$person.name这个反射方法的执行结果。如#set($name=$person.name),这样虽然增加了一个#set节点,但是如果能减少多次反射调用仍然是很值得的。
另外,Velocity本身提供了一个#macro语法,它类似于定义一个方法,然后可以调用这个方法,但在没有必要时尽量少用这种语法节点,这些语法节点比较耗时。还有一些大数计算等,最好定义在Java中,通过调用Java中的方法可以加快Velocity的执行效率。
解释执行转换成编译执行
也就是将vm模板先编译成Java类,再去执行这个Java对象,从而渲染出页面。Sketch模版引擎,主要分为两个部分:运行时环境和编译时环境。前者主要用来将模板渲染成HTML,后者主要是把模板编译成Java类。当请求渲染一个vm模板时,通过调用单例RuntimeServer获取一个模板编译后的Java对象,然后调用这个模板对应的Java对象的render方法渲染出结果。如果是第一次调用一个vm模板,Sketch框架将会加载该vm模板,并将这个vm模板编译成Java,然后实例化该Java类,实例化对象放入RuntimeContext集合中,并根据Context容器中的变量对应的对象值渲染该模板。一个模板将会被多次编译,这是一个不断优化的过程。
我们优化Velocity模板的一个目的就是将模板的解释执行变为编译执行,从前面的理论分析可知,vm中的语法最终被解释成一棵语法树,然后通过执行这棵语法树来渲染出结果。我们要将它变成编译执行的目的就是要将简单的程序复杂化,如一个#if语法在Velocity中会被解释成一个节点,显然执行这个#if语法要比真正执行Java中的if语句要复杂很多。虽然表面上只需调用一个树的render方法,但是如果要将这个树变成真正的Java中的if去执行,这个过程要复杂很多。所以我们要将Velocity的语法翻译成Java语法,然后生成Java类再去执行这个Java类。理论上Velocity是动态解释语言而Java是编译性语言,显然Java的执行效率更高。
如何将Velocity的语法节点变成Java中对应的语法?实现思路大体如下。
仍然沿用Velocity中将一个vm模板解释成一棵AST语法树,但是重新修改这棵树的渲染规则,我们将重新定义每个语法节点生成对应的Java语法,而不是渲染出结果。在SimpleNode类中重新定义一个generate方法,这个方法将会执行所有子类的generater方法,它会将每个Velocity的语法节点转化成Java中对应的语法形式。除这个方法外还有value方法和setValue方法,它们分别是获取这个语法节点的值和设置这个节点的值,而不是输出。
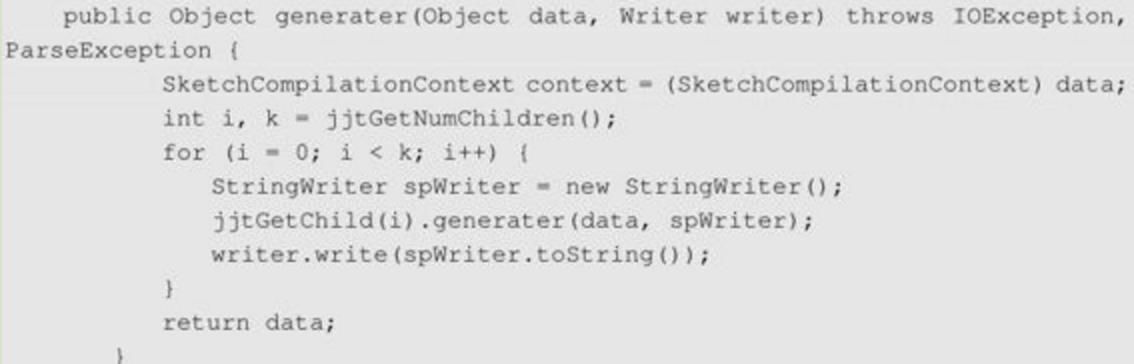
总之,要将所有的Velocity的语法都翻译成对应的Java语法,这样才能将整个vm模板变成一个Java类。那么整个vm又是如何组织成一个Java类的呢?
example_vm是模板example.vm编译成的Java类,它继承了AbstractTemplateInstance类,这个类是编译后模板的父类,也是遵照设计模板中的模板模式来设计的。这个类定义了模板的初始化和销毁的方法,同时定义了一个render方法供外部调用模板渲染,而TemplateInstance类很显然是所有模板的接口类,它定义了所有模板对外提供的方法
TemplateConfig类非常重要,它含有一些模板渲染时需要调用的辅助方法,如记录方法调用的实际对象类型及方法参数的类型,还有一些出错处理措施等。_TRACE方法在执行编译后的模板类时需要记录下vm模板中被执行的方法的执行参数,_COLLE方法当模板中的变量输出时可以触发各种注册的触发事件,如变量为空判断、安全字符转义等。我们可以发现有个内部类I,这个类只保存一些变量属性,用于缓存每次模板执行时通过Context容器传过来的变量的值。
上面vm例子中的#foreach语法被编译成了一个单独的方法,这是为什么呢?因为我们的模板如果非常大,将所有的代码都放在一个方法中(如render),这个方法可能会超过64KB,我们知道Java编译器的方法的最大大小限制是64KB,这个问题在JSP中也会存在,所有JSP中引入了标签,每个标签都被编译成一个方法,也是为了避免方法生成的Java类过长而不能编译。
ps:上面代码中还有两个地方要注意:一个地方是$exampleDO.getItemList()代码被解析成_I.exampleDO).getItemList()方法调用(第一次编译时是通过反射调用,多次编译后通过方法调用),也就是将Velocity的动态反射调用变成了Java的原生方法调用;另外一个地方是将静态字符串解析成byte数组,页面的渲染输出改成了字节流输出。
方法调用的无反射优化
一个地方是$exampleDO.getItemList()代码被解析成_I.exampleDO).getItemList()方法调用(第一次编译时是通过反射调用,多次编译后通过方法调用)。
只有当模板真正执行时才会知道$exampleDO变量实际对应的Java对象,才知道这个对象对应的Java类。而要能确定一个方法,不仅要知道这个方法的方法名,还要知道这个方法对应的参数类型。所以在这种情况下要多次执行才能确定每个方法对应的Java对象及方法的参数类型。
第一次编译时不知道变量的类型,所以所有的方法调用都以反射方式执行,$exampleDO.getItemList()的调用变成了_TRACE方法调用,这个方法有点特殊,它会记录下这个$exampleDO.getItemList()这次调用传过来的对象context.get("exampleDO")及方法参数new Object[]{},并以这个方法的hash值作为key保存下来。当第二次编译时遇到$exampleDO.getItemList()语法节点时将会将这个语法节点解析成(Mode) _I.exampleDO).getItemList()。由于一个模板中一次执行并不能执行到所有的方法,所以一次执行并不能将所有的方法调用转变成反射方式。这种情况下就会多次生成模板对应的Java类及多次编译。
字符输出改成字节输出
另外一个地方是将静态字符串解析成byte数组,页面的渲染输出改成了字节流输出。
静态字符串直接是out.write(_S0),这里的_S0是一个字节数组,而vm模板中是字符串,将字符串转成字节数组是在这个模板类初始化时完成的。字符的编码是非常耗时的,如果我们将静态字符串提前编码好,那么在最终写Socket流时就会省去这个编码时间,从而提高执行效率。从实际的测试来看,这对提升性能很有帮助。另外,从代码中还可以发现,如果是变量输出,调用的是out.write(_EVTCK(context,"$str", context.get("str"))),而_EVTCK方法在输出变量之前检查是否有事件需要调用,如XSS安全检查、为空检查等。
与JSP比较
JSP渲染机制
在实际应用中通常用两种方式调用JSP页面,一种方式是直接通过org.apache.jasper. servlet.JspServlet来调用请求的JSP页面,另一种方式是通过如下方式调用:

两种方式都可以渲染JSP,前一种方式更加方便,只要中配置的路径符合JspServlet就可以直接渲染,后一种方式更加灵活,不需要特别的配置就行。虽然两种调用方式有所区别,但是最终的JSP渲染原理都是一样的。下面以一个最简单的JSP页面为例看它是如何渲染的:

如上面这个index.jsp页面,把它放在Tomcat的webapps/examples/jsp目录下,我们通过第二种方式来调用,访问一个Servlet,然后在这个Servlet中通过RequestDispatcher来渲染这个JSP页面。调用代码如下:
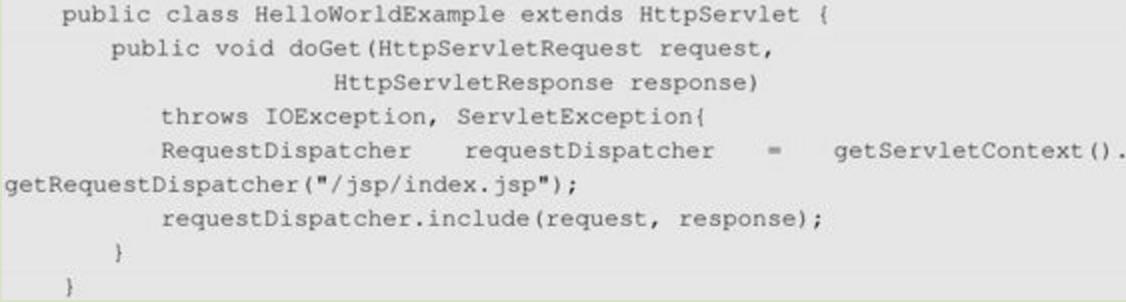
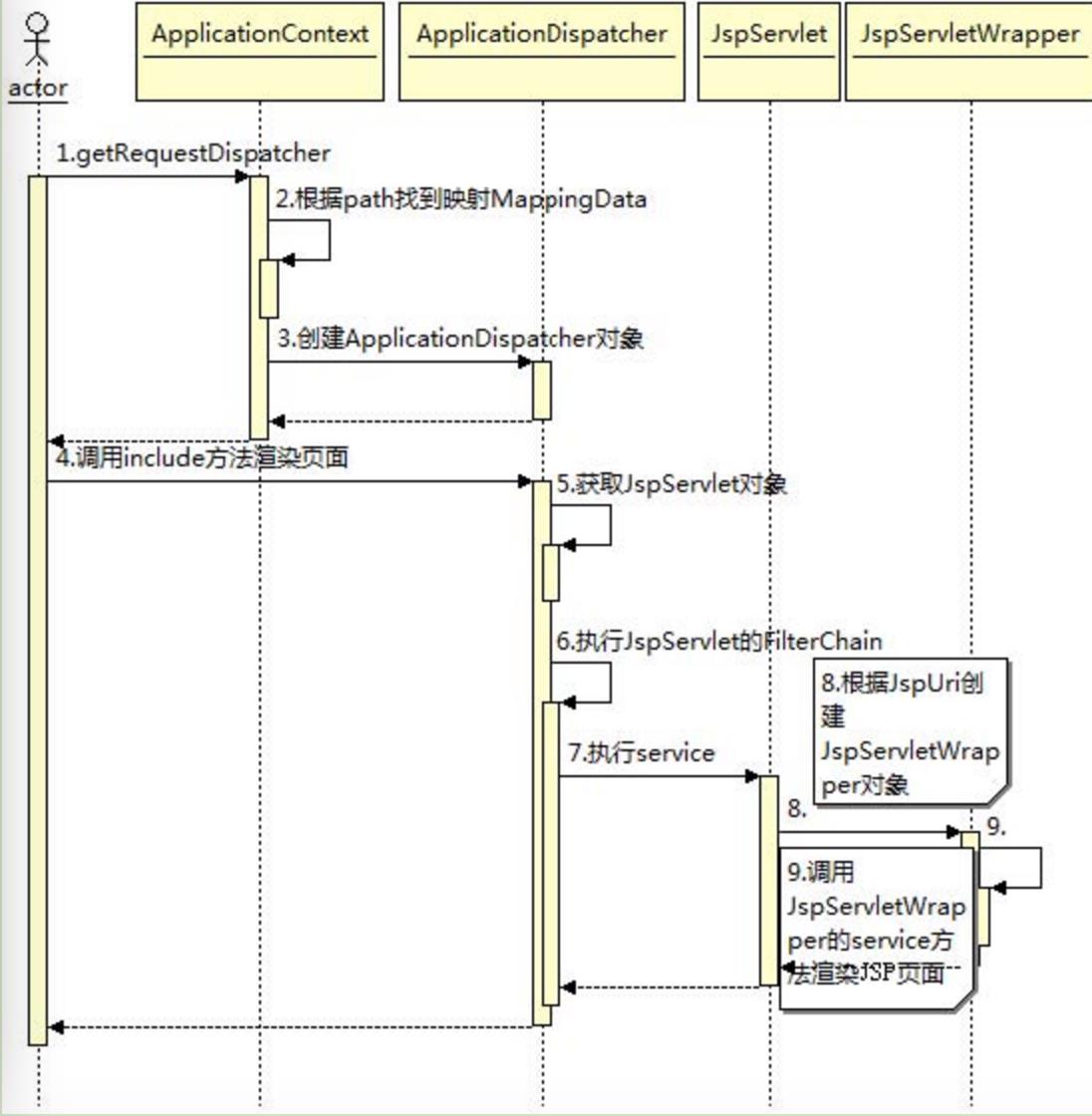
从图中可以看出,ServletContext根据path来找到对应的Servlet,这个映射是在Mapper.map方法中完成的,Mapper的映射有7种规则,这次映射是通过扩展名“.jsp”来找到JspServlet对应的Wrapper的。然后根据这个JspServlet创建ApplicationDispatcher对象。接下来就和调用其他Servlet一样调用JspServlet的service方法,由于JspServlet专门处理渲染JSP页面,所以这个Servlet会根据请求的JSP文件名将这个JSP包装成JspServletWrapper对象。JSP在执行渲染时会被编译成一个Java类,而这个Java类实际上也是一个Servlet,那么JSP文件又是如何被编译成Servlet的呢?这个Servlet到底是什么样子的?每一个Servlet在Tomcat中都被包装成一个最底层的Wrapper容器,那么每一个JSP页面最终都会被编译成一个对应的Servlet,这个Servlet在Tomcat容器中就是对应的JspServletWrapper。
HttpJspBase类是所有JSP编译成Java的基类,这个类也继承了HttpServlet类、实现了HttpJspPage接口,HttpJspBase的service方法会调用子类的_jspService方法。被编译成的Java类的_jspService方法会生成多个变量:pageContext、application、config、session、out和传进来的request、response,显然这些变量我们都可以直接引用,它们也被称为JSP的内置变量。对比一下JSP页面和生成的Java类可以发现,页面的所有内容都被放在_jspService方法中,其中页面直接输出的HTML代码被翻译成out.write输出,页面中的动态“<%%>”包裹的Java代码直接写到_jspService方法中的相应位置,而“<%=%>”被翻译成out.print输出。
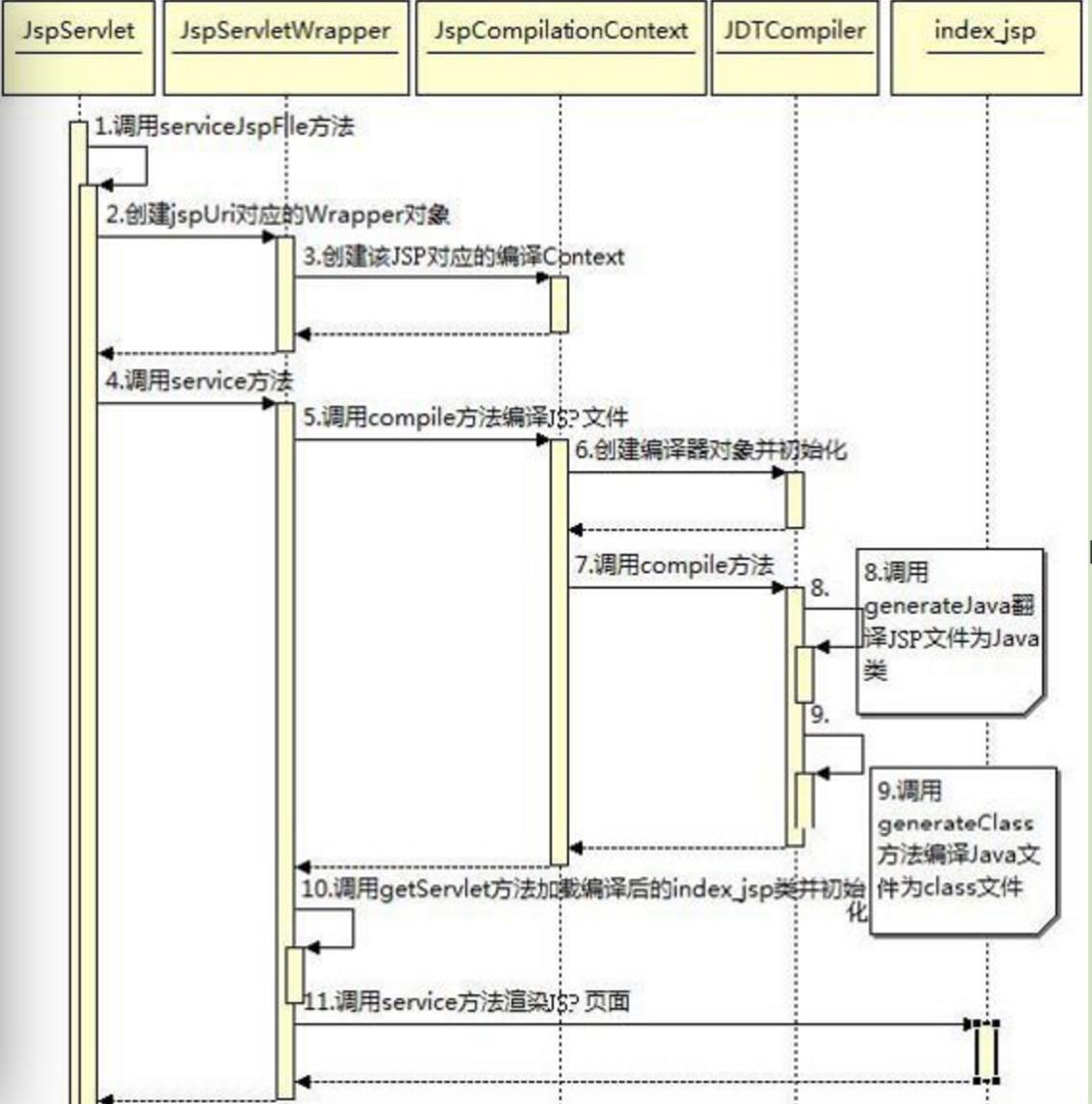
我们从JspServlet的service方法开始看一下index.jsp是怎么被翻译成index_jsp类的,首先创建一个JspServletWrapper对象,然后创建编译环境类JspCompilationContext,这个类保存了编译JSP文件需要的所有资源,包括动态编译Java文件的编译器。在创建JspServletWrapper对象之前会首先根据jspUri路径检查JspRuntimeContext这个JSP运行环境的集合中对应的JspServletWrapper对象是否已经存在。在JDTCompiler调用generateJava方法时会生产JSP对应的Java文件,将JSP文件翻译成Java类是通过ParserController类完成的,它将JSP文件按照JSP的语法规则解析成一个个节点,然后遍历这些节点来生成最终的Java文件。具体的解析规则可以查看这个类的注释。翻译成Java类后,JDTCompiler再将这个类编译成class文件,然后创建对象并初始化这个类,接下来就是调用这个类的service方法,完成最后的渲染。下图这个过程的时序图。
Velocity与JSP
从上面的JSP渲染机制我们可以看出JSP文件渲染其实和Velocity的渲染机制很不一样,JSP文件实际上执行的是JSP对应的Java类,简单地说就是将JSP的HTML转化成out.write输出,而JSP中的Java代码直接复制到翻译后的Java类中。最终执行的是翻译后的Java类,而Velocity是按照语法规则解析成一棵语法树,然后执行这棵语法树来渲染出结果。所以它们有如下这些区别。
- 执行方式不一样:JSP是编译执行,而Velocity是解释执行。如果JSP文件被修改了,那么对应的Java类也会被重新编译,而Velocity却不需要,只是会重新生成一棵语法树。
- 执行效率不同:从两者的执行方式不同可以看出,它们的执行效率不一样,从理论上来说,编译执行的效率明显好于解释执行,一个很明显的例子在JSP中方法调用是直接执行的,而Velocity的方法调用是反射执行的,JSP的效率会明显好于Velocity。当然如果JSP中有语法JSTL,语法标签的执行要看该标签的实现复杂度。
- 需要的环境支持不一样:JSP的执行必须要有Servlet的运行环境,也就是需要ServletContext、HttpServletRequest和HttpServletResponse类。而要渲染Velocity完全不需要其他环境类的支持,直接给定Velocity模板就可以渲染出结果。所以Velocity不只应用在Servlet环境中。
以上是关于Velocity工作原理解析和优化的主要内容,如果未能解决你的问题,请参考以下文章
根据浏览器渲染引擎工作原理(reflow/repaint),来优化DOM的操作