C#中使用Redis不同数据结构的内存占有量的疑问和对比测试
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C#中使用Redis不同数据结构的内存占有量的疑问和对比测试相关的知识,希望对你有一定的参考价值。
最近在大量使用Redis来进行数据统计前的清洗和整理,每天的数据量超5千万+,在开发过程中,数据量小,着重注意业务规则的处理,在上线基本测试后发现了大量的问题,其中之一就是Redis存储数据过多,内存的使用量大大增加。进过简单分析,对存储非常频繁的实体类进行了改进,字段名字进行缩写处理,一下子就减少了很多内存使用量。在对Redis的研究过程中,发现了以下这篇文章:Redis上踩过的一些坑-美团 ,发现其中 有一节内容:“四、redis内存使用优化 ”,对Redis不同的存储结构的使用量进行了对比,对此很敢兴趣,也发现自己在使用过程中可能存储误区,所以就根据自己的业务情况进行了同样的测试,看看有没有优化的余地。
1.测试环境和对比项目
C# 4.0 + ServiceStack.Redis 3.9 + Windows Redis 2.6.2
测试同样数据结构下,测试存储的Key 的个数100万:
1) 普通K-V结构存储
2) 列表结构存储
3) 独立哈希结构存储
4) 多个哈希结构存储
下面看看简单的代码和结果,为了简单起见,我们使用同一个实体结构和同样的数据,这个实体是业务中用到的,对字段值进行了模糊处理。
由于上述美团的文章的存储结构比较简单,所以我选择了一个比较接近实际使用的实体结构。7个字段,值类型也基本都有。
static SendScanMsg GetEntity()
{
return new SendScanMsg()
{
SN = "测试测试",
NN = "测试",
SM = "颜色身高7",
SC = "123445.888",
P = "A59115901094",
ST = Convert.ToDateTime("2016-01-18 09:54:53"),
RT = Convert.ToDateTime("2016-01-18 10:59:44")
};
}
2.单独的Key-Value存储
简单代码,其中的redis操作经过了封装,看懂意思即可。K-V存储可以想象肯定存储空间是最大的,因为到了一定数量级,Key的长度很关键,也很占内存。
public static void TestKeyMemorySingle()
{
String key = "701183714183_8801_6222";
var model = GetEntity();
Int32 N = 1000000;
for (int i = 0; i < N; i++)
{
MsgRedis.RedisHelper.Item_Set<SendScanMsg>(key + i.ToString(), model, new TimeSpan(10, 0, 0));
}
}
结果如下:
# Memory used_memory:317253140 used_memory_human:302.56M used_memory_rss:317253140 used_memory_peak:317253324 used_memory_peak_human:302.56M used_memory_lua:31744 mem_fragmentation_ratio:1.00 mem_allocator:libc
3. List列表结构存储
看看代码,List结构只数组类型,理论上也是最节省空间的,因为只有1个Key,看看结果:
public static void TestKeyMemoryList()
{
String key = "701183714183_8801_6222";
var model = GetEntity();
Int32 N = 1000000;
for (int i = 0; i < N; i++)
{
MsgRedis.RedisHelper.List_Add<SendScanMsg>(key, model);
}
}
结果如下:
# Memory used_memory:220861160 used_memory_human:210.63M used_memory_rss:220861160 used_memory_peak:410351028 used_memory_peak_human:391.34M used_memory_lua:31744 mem_fragmentation_ratio:1.00 mem_allocator:libc
4.单独哈希结构
代码如下,原理和上面类似。实际使用中,哈希结构使用还是很频繁的,但是也有一些相应的不方便,比如不能针对单个Key设置过期时间,只能对整体的哈希Key设置过期时间,不能分页获取等,具体使用根据情况选择即可。
public static void TestKeyMemoryHash()
{
String key = "701183714183_8801_6222";
var model = GetEntity();
Int32 N = 1000000;
for (int i = 0; i < N; i++)
{
MsgRedis.RedisHelper.Hash_Set<SendScanMsg>(key,i.ToString(), model);
}
}
结果如下,可以看到结果比列表多了不多,应该是Key的原因导致的:
# Memory used_memory:253009020 used_memory_human:241.29M used_memory_rss:253009020 used_memory_peak:471307216 used_memory_peak_human:449.47M used_memory_lua:31744 mem_fragmentation_ratio:1.00 mem_allocator:libc
5.多个哈希结构存储
根据上面那篇文章提供的信息,多个哈希结构存储要比单个哈希更节省空间。所以我也特意对比了一下,我们将哈希的ID分为用0-100的队列,取余实现:
public static void TestKeyMemorySplitHash()
{
String key = "701183714183_8801_6222";
var model = GetEntity();
Int32 N = 1000000;
for (int i = 0; i < N; i++)
{
MsgRedis.RedisHelper.Hash_Set<SendScanMsg>(key+(i%100).ToString(),i.ToString(), model);
}
}
结果如下,其实和单个哈希相差不大,分析原因,可能和具体的使用实体类的Key有关系。并不是所有的情况都是差距好几倍。这也是我测试的真正目的,看看真的差距是不是有这么多。
# Memory used_memory:264309588 used_memory_human:252.07M used_memory_rss:264309588 used_memory_peak:266261980 used_memory_peak_human:253.93M used_memory_lua:31744 mem_fragmentation_ratio:1.00 mem_allocator:libc
6.结论
上述结果的直接对比如下图,由于实际使用的实体结构和上述提到的文章不一样,所以结果没有对比性,大家也不能完全迷信我的结果,具体问题,具体分析,我们只能从测试中发现大概的趋势,至于具体的差距会根据实际情况不同而不同:
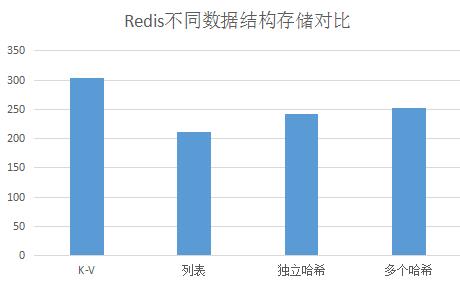
Redis使用上对Key的存储和具体业务要相关,至于是列表还是哈希搞清楚其特点也不难,至于独立的哈希结构和多个哈希节省空间的问题,大部分差不多,也需要在使用上根据业务划分为好,也不能单独的为了节省内存空间丢失业务的灵活性。下面简单说说几种数据结构的区别:
-
独立的K-V结构:好处是单个存储可以灵活设置过期时间,同时同一种数据类型内存占有量会增加;在Redis中结构性不明显;
-
List结构:List结构好处是可以很灵活的获取一定范围的数据,或者分页,同时也是最省内存的,但是实体独立查找比较困难;只能对整个List结构设置过期时间;
-
哈希结构:最大的好处是元素的查找效率高,很灵活,但缺点是不能像List那样按照范围获取,也只能设置过期时间;
在经过一段时间的开发后,对数据分析过程中的不同问题和业务采样合适的结构也有了很深的理解。每种结构的优缺点其实是互补的,只要耐心,仔细分析,其实这几种结构非常强大。时间进展,至于Redis的使用经验,个人还有很多不足,如有问题,还请指正。
以上是关于C#中使用Redis不同数据结构的内存占有量的疑问和对比测试的主要内容,如果未能解决你的问题,请参考以下文章