协同过滤-基于物品的过滤
Posted 曹孟德
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了协同过滤-基于物品的过滤相关的知识,希望对你有一定的参考价值。
现在假设你有100万个用户,每次对一个用户进行一次推荐时,需要计算100万次距离。如果每一秒需要进行多次推荐的话计算次数会十分巨大,系统会很慢。正式的说话是,基于令居的推荐系统的主要缺点是延迟性太差。
1 )基于用户的过滤的两个主要问题:
1.扩展性问题: 随着用户数量的增大,计算量会增大,基于用户的过滤在几千用户时效果还可以,但是有上百万用户时,扩展性成了问题
2.稀疏性问题:大部分推荐系统中,用户和商品有很多,但是用户评级的商品数却很少,有的时候可能找不到令居
2)基于物品的过滤:
基于物品的过滤是对上述基于用户过滤的改进。基于物品的过滤是可以计算出最相似的两件物品(基于用户的过滤是寻找最相近的用户),并结合用户对物品的评价结果来生成推荐。
特别注意:基于用户的过滤也称为基于内存的协同过滤,原因是必须保存所有的评级结果来进行推荐。基于物品的过滤也称为基于模型的协同过滤,原因是不需要保存所有的平均结果,取而代之的是构建一个模型来表示物品间的相似度。
3)调准后的余弦相似度:
由于用户的个人习惯,很多用户的评级会超过预期,这种就是“分数贬值”。为了抵消分数贬值,我们会从每个评级结果中减去平均评级结果。这样得到以下调准后的余弦相似度公式:
 、
、
假设数据是以json方式传入的,计算改进的余弦相似度代码如下:
def similarity(band1,band2,userRatings):
average = {}
for (key,ratings) in userRatings.items():
average[key] = float(sum(ratings.values()))/len(ratings.values())
num = 0
dem1 = 0
dem2 = 0
for (key,ratings) in userRatings.items():
if band1 in ratings and band2 in ratings:
num += (ratings[band1] - average[key]) * (ratings[band2] - average[key])
dem1 += (ratings[band1] - average[key])**2
dem2 += (ratings[band2] - average[key])**2
return num / sqrt(dem1*dem2)
接下来运用物品的相似度矩阵来预测用户的评分:

用 max和min分别表示最大和最小平级结果,Ru,N是用户u对用物品N的当前平级结果,用NRu,N表示归一化后的平级结果,归一化计算公式如下:
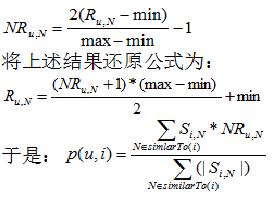
注意:调准后的余弦相似度公式是一种基于模型的协同过滤的方法。与基于内存的方法相比,这类方法计算时间更快,需要内存也更少。在通常情况下,用于用户的个人打分风格,例如我可能对我喜欢的歌手打4分,不喜欢的歌手打3分,但是你却对喜欢的打5分,而对不喜欢的打1分。调准后的余弦相似度通过减去每个用户给出的平均分来处理这个问题。
以上是关于协同过滤-基于物品的过滤的主要内容,如果未能解决你的问题,请参考以下文章