机动车缉查布控即席分析引擎
Posted qq_33160722
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机动车缉查布控即席分析引擎相关的知识,希望对你有一定的参考价值。
原文地址:http://user.qzone.qq.com/165162897/blog/1476716158
自2012年以来,公安部交通管理局在全国范围内推广了机动车缉查布控系统(简称卡口系统),通过整合共享各地车辆智能监测记录等信息资源,建立了横向联网、纵向贯通的全国机动车缉查布控系统,实现了大范围车辆缉查布控和预警拦截、车辆轨迹、交通流量分析研判、重点车辆布控、交通违法行为甄别查处及侦破涉车案件等应用。在侦破肇事逃逸案件、查处涉车违法行为、治安防控以及反恐维稳等方面发挥着重要作用。
随着联网单位和接入卡口的不断增加,各省市区部署的机动车缉查布控系统积聚了海量的过车数据。截至目前,全国32个省(区、市)已完成缉查布控系统联网工作,接入卡口超过50000个,汇聚机动车通行数据总条数超过2000亿条。以一个中等规模省市为例,每地市每日采集过车信息300万条,每年采集过车信息10亿条,全省每年将汇聚超过200亿条过车信息。如何将如此海量的数据管好、用好成为各省市所面临的巨大挑战。
一、典型需求
1.行车轨迹查询分析
精确查询:通过号牌种类、号牌号码、时间等条件查询机动车通行数据;模糊查询:通过模糊的号牌号码、卡口、时间、车身颜色、车辆类型等条件查询机动车通行数据。
2.嫌疑车辆分析
挖掘在不同地点多次同行的车辆。根据确认的车辆,寻找同行车。挖掘不同时间段通过一个或多个卡口的车辆筛选分析。分析判断在某一区域、某一特定时间段第一次出现的车辆。分析判断部分车辆某个时间点进城后不出城或是晚上某个时间点进城或出城,筛选出有规律性的车辆。
3.数据碰撞分析
跨地区的海量机动车过车数据碰撞,分析出假套牌车辆,通过识别车辆品牌、颜色等特征信息,比对车辆登记信息,发现套牌假牌车辆;重点车辆、报废车辆与过车数据的分析碰撞,发现未按照规定时间、线路、已报废仍在路面行驶的车辆信息。
4.重点车辆分析
根据统计一定区域范围内的客运、危险品运输、特殊车辆等重点车辆通行数量,研判发现通行规律。对在路段内行驶时间异常的车辆、首次在本路段行驶、预期报废、未年检仍在道路上行驶的重点车辆、2到5点仍在道路上行驶的客运车辆等进行预警提示。
5.车辆出入统计分析
挖掘统计一段时间内在某一个区域内(可设定中心城区、地市区域、省市区域、高速公路等区域)、进出区域、主要干道的经常行驶车辆、“候鸟”车辆、过路车辆的数量以及按车辆类型、车辆发证地的分类统计。
二、关键能力
1.数据规模
能够承载日均数亿条增量,未来三到五年,数百亿,甚至数千亿条数据总量。
2.即席分析
根据不同的城市,往往在逻辑上有较大的区别,不同的案件也会有较大的不同,故一个查询系统要求非常灵活,可以处理复杂的业务逻辑,算法,而不是一些常规的简单的统计。
3.高时效性
对数据时效性要求较高,要求某一车辆在经过某一卡口后,可达到分钟级别内系统可查可分析。对检索性能要求很高,以上典型需求均要求能够在秒级内返回结果及明细。
4.企业级特性
易于部署,易于扩容,易于数据迁移;
多数据副本保护,无单点故障;
服务自动检测及恢复;
三、备选方案—优缺点分析
1.开源大数据系统解决方案(Hadoop、Spark、Hive、Impala)
| 数据规模 | √ | 基于hdfs之上,数据可无限拓展,存储PB级的数据很轻松。 |
| 时效性 | × | hdfs的特性导致数据延迟较大,常规应用均是T+1数据,即延迟一天。 |
| 查询性能与并发 | × | 该类系统并非为即席查询而设计,比较适合离线分析,通常来说一个hiveSQL运行时间从几分钟到几小时不等,如果是百亿规模的数据分析时间可能会达到数个小时,如果以现有XX部门的预算来看,可能需要数天的时间,究其根本原因是该类系统是采用暴力扫描的方式,即如果是100亿条数据,也是采用从头遍历到末尾的方式扫描,性能可想而知, 基本无并发性可言。单并发就需要数小时。 |
| 灵活性 | √ | 1.SQL支持较为齐全。 2.与周边系统的集成非常方便,数据导入导出灵活。 3.支持jdbc方式,可以与常见的报表系统无缝集成。 |
| 运维 | √ | 硬件损坏,机器宕机后可自动迁移任务,不需要人工干预,中间不影响服务。 |
| 扩容迁移容灾 | √ | 1.从一开始设计之初,hadoop即假设所有的硬件均不可靠,一旦硬件损坏,数据不会丢失,有多份副本可以自动恢复数据。 2.数据迁移以及机器扩容有比较完备的方案,中间不停服务,动态扩容。 |
2.流计算系统(Storm、SparkStreaming)
| 数据规模 | √ | 基于hdfs之上,数据可无限拓展, |
| 时效性 | √ | 时效性非常好,一般与kafka采用消息队列的方式导入,时效性可达几秒可见。 |
| 查询性能与并发 | √ | 1.预先将需要查询的数据计算好,查询的时候直接访问预计算好的结果,性能非常好。 2.预计算完毕的结果集存储在hbase或传统数据库里,因数据规模并不大故并发性比较好。 |
| 灵活性 | × | 无法查看明细数据,只能看特定粒度的汇总结果,而过车记录是无法先计算出来的,即无法预知那个车有可能会犯罪,那个车会出事故,故无法预计算。 |
| 运维 | √ | 损坏的机器会自动摘除,进行会自动迁移,服务不中断。 |
| 扩容迁移容灾 | √ | 数据迁移,扩容,容灾均有完善的方案,storm的扩容需要简单的rebanlance即可。 |
3.全文检索系统(Solr、ElasticSearch)
| 数据规模 | × | 1.典型使用场景在千万级别,如果给予较大内存,数据量可上亿。 2.本身系统内存的限定,百亿以上降会是巨大的挑战。 |
| 时效性 | × | 1.支持实时导入,在千万数据规模下导入性能较好。 2.数据过亿后,生产系统实时导入经常会出现OOM,以及CPU负载太高的问题,故过亿数据无法实时导入数据,一般都采用离线创建索引的方式,即数据时效性延迟一天。 |
| 查询性能与并发 | √ | 1.采用倒排索引,直接根据索引定位到相关记录,而不需要采用全表暴力扫描的方式,检索查询性能特别高。 2.在千万级别以下,并且给予较多内存的情况下,并发情况很好。 |
| 灵活性 | × | 1.为搜索引擎的场景而生,分析功能较弱。只有最简单的统计功能,无法满足过车记录复杂的统计分析需求。 2.与周边系统的集成麻烦,数据导入导出太麻烦,甚至不可行,第三方有SQL引擎插件,但均是简单SQL,且由于Merger server是单节点的问题,很多SQL的查询性能很低,不具备通用性。 3.无法与常见的支持jdbc标准的报表系统集成,定制开发代价较大。 |
| 运维 | × | 1.数据规模一旦过百亿,就会频繁的出现OOM,节点调片的情况。 2.一旦调片后无法自动恢复服务,需要运维人员去重启相关服务。 3.系统无过载保护,经常是一个人员做了一个复杂的查询,导致集群整体宕机,系统崩溃。 |
| 扩容迁移容灾 | × | 1.数据存储在本地磁盘,一旦本地将近20T的存储盘损坏,需要从副本恢复后才能继续服务,恢复时间太长。 2.数据迁移不完善,如若夸机房搬迁机器,需要运维人员细心的进行索引1对1复制,搬迁方案往往要数星期,且非常容易出错。 3.数据如若想导出到其他系统很难,超过百万级别的导出基本是不可行的,更别提复杂计算后的导出,没有成型的高可用的导出方案。 |
四、最终方案(万亿秒查)
针对上述典型场景,我们最终将多个系统整合,发挥系统的各自优势,扬长避短,深度集成。延云YDB作为机动车缉查布控即席分析引擎,已经在近10个城市的成功部署或测试,取得非常好的效果,有的甚至超过了客户的预期。
YDB是一个基于Hadoop分布式架构下的实时的、多维的、交互式的查询、统计、分析引擎,具有万亿数据规模下的万级维度秒级统计分析能力,并具备企业级的稳定可靠表现。
YDB是一个细粒度的索引,精确粒度的索引。数据即时导入,索引即时生成,通过索引高效定位到相关数据。YDB与Spark深度集成,Spark直接对YDB检索结果集分析计算,同样场景让Spark性能加快百倍。
整体技术架构如下:
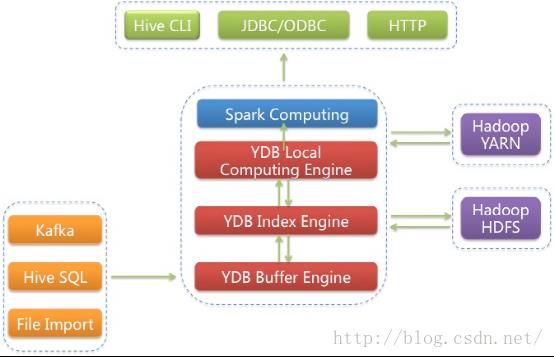
详细原理请参考这里:https://yunpan.cn/c6KINvxiIHVSr
| 数据规模 | √ | 在政府某部门:用4~10台普通PC即可支撑百亿规模的数据。 在IBM的小型机上:用10台机器就支持一万亿的数据规模。 在某互联网公司:支撑了每天7000亿,总量几万亿的数据查询。 |
| 时效性 | √ | 结合了storm流式处理的优点,采用对接消息队列(如kafka)的方式,数据导入kafka后大约1~2分钟即可在ydb中查到。 |
| 并发查询性能 | √ | 1.借鉴了solr与elastic search,使用了倒排索引,查询的时候直接定位到相关记录,避免了对数据的暴力扫描。 2.借鉴spark的process local方式,让同一份数据尽量在同一个进程内重用,以便能够高效的Cache。 3.结合标签技术、不必读取列的值本身,而是只读取其数值字典代号,更小的IO,能够让数据比常规计算能够更快的进行process local级的combine。 4.延迟列加载技术,可以让一些列的值在最终返回给用户的时候在读取,相比spark的列存储方式通常可以节省该列90%以上的IO。 5.采用列存储计算,列与列之间在存储上分开, 6.百亿规模1秒内响应,万亿规模10台IBM机器3~5秒响应。一般根据数据量,常规查询可支撑200~300个人一起并发查询。 |
| 灵活性 | √ | 1.我们将索引集成到了spark内部,这样结合Spark可以做很多复杂的计算,但又兼顾了倒排索引的高性能。用户可以写复杂的SQL,可以嵌套、可以join、可以distinct、可以自定义UDF\\UDAF\\UDTF函数来扩中SQL的功能。 2.因HIVE已经成为大数据的实时标准,YDB采用HIVE SQL的方式与周边系统的集成非常方便,数据导入导出灵活。 3.HIVE本身支持jdbc方式,可以与常见的报表系统无缝集成。 |
| 运维 | √ | 1.采用spark yarn的方式,系统宕机,硬件损坏,服务会自动迁移,数据不丢失。 2.延云YDB只需要部署在一台机器上,由yarn自动分发,不需要维护一堆机器的配置,改参数很方便。 |
| 扩容迁移容灾 | √ | 数据存储在hdfs之上,不存储在本地硬盘,扩容,迁移,容灾与hadoop一样,稳定可靠。 |
五、性能测试(2台机器200亿条数据)
延云YDB的性能无论是精确查询还是模糊查询都在毫秒级响应,延云单独搭建一套测试环境,将数据规模扩大到现在的 20~40倍(200亿条),机器数量缩减到两台普通的PC机,以展示在数据量暴增后延云YDB的性能表现,以下为压测记录。
测试时间
2016年10月16日
硬件配置
| 硬件配置项 | 详细信息 |
| 机器型号 | IBM 3650 M3 |
| CPU | 2*6核2台 |
| 内存 | DDR3 64GB |
| 数据盘 | SAS盘 300G 6块裸盘挂载 |
| Raid 配置 | RAID 0 |
| 网卡 | 千兆网卡 |
| 交换机 | TPLINK千兆交换机 |
| 路由器 | 华为百兆路由器 |
以上是关于机动车缉查布控即席分析引擎的主要内容,如果未能解决你的问题,请参考以下文章