HTTP Headers解析
Posted Zhao-Pace
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HTTP Headers解析相关的知识,希望对你有一定的参考价值。
什么是HTTP Headers? 它包含了哪些内容? 利用requests.get()函数对豆瓣读书进行请求, 返回的r.headers如下所示:
>>> import requests >>> r = requests.get(\'https://book.douban.com/\') >>> r.headers {\'X-Powered-By-ADS\': \'chn-shads-4-12\', \'X-Xss-Protection\': \'1; mode=block\', \'X-DAE-App\': \'book\', \'X-Content-Type-Options\': \'nosniff\', \'Content-Encoding\': \'gzip\', \'Transfer-Encoding\': \'chunked\', \'Set-Cookie\': \'bid=ZT-mRsxMMX0; Expires=Mon, 23-Oct-17 03:11:40 GMT; Domain=.douban.com; Path=/, __ads_session=2Yy49z4EzghqOiuo9gA=; domain=.douban.com; path=/\', \'Expires\': \'Sun, 1 Jan 2006 01:00:00 GMT\', \'Vary\': \'Accept-Encoding\', \'X-DAE-Node\': \'nain3\', \'Server\': \'ADSSERVER/44619\', \'X-Douban-Mobileapp\': \'0\', \'Connection\': \'keep-alive\', \'Pragma\': \'no-cache\', \'Cache-Control\': \'must-revalidate, no-cache, private\', \'Date\': \'Sun, 23 Oct 2016 03:11:40 GMT\', \'Strict-Transport-Security\': \'max-age=15552000;\', \'X-DOUBAN-NEWBID\': \'ZT-mRsxMMX0\', \'Content-Type\': \'text/html; charset=utf-8\'}
\'Content-Type\': \'text/html; charset=utf-8\'
这个是文档的mime-type, 浏览器根据此参数来决定如何对文档进行解析. 例如一个html页面返回值就是:
\'text/html; charset=utf-8\';
/前的\'text\'表示文档类型, /后面的\'html\'表示文档的子类型;
如果是图片,则返回: \'image/jpeg\', 表示目标是一个图像(image), 具体是一个jpeg图像.
>>> p = requests.get(\'http://pic33.nipic.com/20130916/3420027_192919547000_2.jpg\') >>> p.headers[\'content-type\'] \'image/jpeg\'
如果是pdf文档, 则返回\'application/pdf\'
>>> import requests >>> s = requests.get(\'http://www.em-consulte.com/showarticlefile/738819/main.pdf\') >>> s.headers[\'Content-Type\'] \'application/pdf\'
mime-type类型不止这三个, 还有其他的mime-type类型在这里可以看到.
\'Cache-Control\': \'must-revalidate, no-cache, private\'
缓存控制字段用于指定所有缓存机制在整个请求/响应中必须服从的指令. 常见的取值有: private(默认), no-cache, max-age, must-revalidate
| Cache指令 | 说明 |
| public | 所有的内容都将被缓存(客户端和代理服务器都可缓存) |
| private | 内容只缓存到私有缓存中(客户端可缓存,代理服务器不可) |
| no-cache | 必须先与服务器确认返回的相应是否被更改,然后才能使用该响应来满足对同一个网址的请求 |
| must-revalidate | 若缓存内容失效,请求必须发送到服务器/代理以进行重新验证 |
| max-age=*** | 缓存内容将在***s之后失效 |
缓存技术可以减轻服务器负载, 降低网络阻塞, 其基本思想是利用了客户访问的时间局部性(temporary location)原理, 将客户访问的内容在Cache里面放一个副本, 这样, 如果该内容再次被访问, 则不用再次发送请求, 而且直接将次网页从Cache里面拿出. 这个机制很好, 但是也可能造成问题: 1) 用户可能再次请求获取到的内容是过期的内容; 2) 如果缓存失效, 客户的访问延迟反而会比直接请求要增加;
\'Expires\': \'Sun, 1 Jan 2006 01:00:00 GMT\'
Expires(期限)提供一个日期和时间, 响应在该日期和时间后被认为失效. 在过期时间前可以从缓存中取得数据, 而不需要再次请求.
它有一个缺点是它返回的是服务器端的时间, 如果客户端时间和服务器端时间不相同或者差别很大, 那么误差比较大. 有了Cache-control的max-age, 这个expires功能被替代.
Cache-control的优先级高于Expires, 都是用来指明当前资源的有效期. 但是Cache-control的设置更加细致.
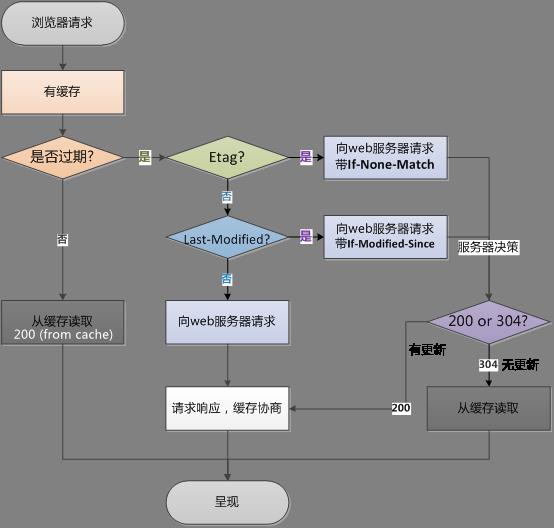
第一次请求的过程:

第二次请求的过程:
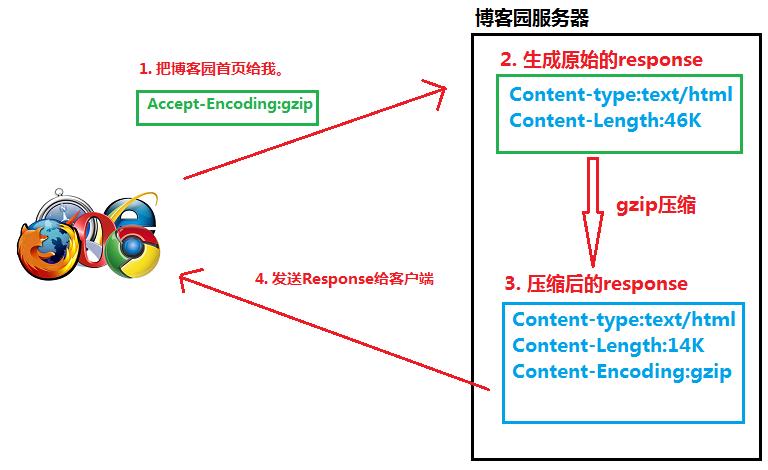
\'Content-Encoding\': \'gzip\'
1. 客户端向服务器发送HTTP request, request里面有Accept-Encoding: gzip, deflate (告诉服务器浏览器支持gzip压缩)
2. 服务器收到请求后, 生成原始的response, 其中有原始的Content-Type, Content-Length
3. 服务器通过gzip对response进行编码, 编码后的headers里面有Content-Type, Content-Length, 而且还有Content-Encoding: gzip, 然后把此response发送给客户端
4. 客户端收到response后, 根据Content-Encoding: gzip对response进行解码, 获取未压缩的response.
\'Set-Cookie\': \'bid=ZT-mRsxMMX0; Expires=Mon, 23-Oct-17 03:11:40 GMT; Domain=.douban.com; Path=/, __ads_session=2Yy49z4EzghqOiuo9gA=; domain=.douban.com; path=/\'
cookie是web服务器向客户端发送的一段ASCII码文本, 一旦收到了cookie, 浏览器会把cookie的信息片段以"名/值"对(name-value pairs)的形式存储在本地. 这以后, 每当向同一个web服务器请求一个新文档时, web服务器变回发送之前存储在本地的cookie. 创建cookie最初的目的是想让web 服务器能够通过多个HTTP请求追踪客户.
参考:
[1] 浏览器 HTTP 协议缓存机制详解: https://my.oschina.net/leejun2005/blog/369148
[2] HTTP请求中的缓存(cache)机制: http://blog.chinaunix.net/uid-11639156-id-3214858.html
[3] http压缩 Content-Encoding: gzip: http://liuviphui.blog.163.com/blog/static/20227308420141843933379/
[4] 完整的Set-Cookie 头: http://blog.sina.com.cn/s/blog_70c4d9410100z3il.html
以上是关于HTTP Headers解析的主要内容,如果未能解决你的问题,请参考以下文章