Spark Streaming编程指南
Posted dabokele
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Streaming编程指南相关的知识,希望对你有一定的参考价值。
本文基于Spark Streaming Programming Guide原文翻译, 加上一些自己的理解和小实验的结果。
一、概述
Spark Streaming是基于Core Spark API的可扩展,高吞吐量,并具有容错能力的用于处理实时数据流的一个组件。Spark Streaming可以接收各种数据源传递来的数据,比如Kafka, Flume, Kinesis或者TCP等,对接收到的数据还可以使用一些用高阶函数(比如map, reduce, join及window)进行封装的复杂算法做进一步的处理。最后,处理好的数据可以写入到文件系统,数据库,或者直接用于实时展示。除此之外,还可以在数据流上应用一些机器学习或者图计算等算法。

上图展示了Spark Streaming的整体数据流转情况。在Spark Streaming中的处理过程可以参考下图,Spark Streaming接收实时数据,然后把这些数据分割成一个个batch,然后通过Spark Engine分别处理每一个batch并输出。
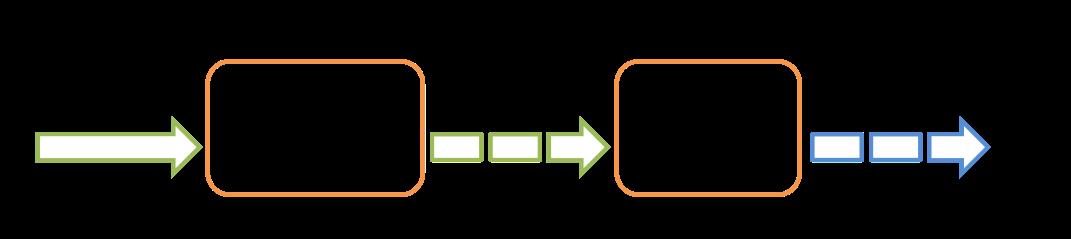
Spark Streaming中一个最重要的概念是DStream,即离散化数据流(discretized stream),DStream由一系列连续的数据集组成。DStream的创建有两种办法,一种是从数据源接收数据生成初始DStream,另一种是由DStream A通过转换生成DStream B。一个DStream实质上是由一系列的RDDs组成。
本文介绍了如何基于DStream写出Spark Streaming程序。Spark Streaming提供了Scala, Java以及Python接口,在官方文档中对这三种语言都有示例程序的实现,在这里只分析Scala写的程序。
二、示例程序
在深入分析Spark Streaming的特性和原理之前,以写一个简单的Spark Streaming程序并运行起来为入口先了解一些相关的基础知识。这个示例程序从TCP socket中接收数据,进行Word Count操作。
1、Streaming程序编写
首先需要导入Spark Streaming相关的类,其中StreamingContext是所有Streaming程序的主要入口。接下来的代码中创建一个local StreamingContext,batch时间为1秒,execution线程数为2。
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// 创建一个local StreamingContext batch时间为1秒,execution线程数为2
// master的线程数数最少为2,后面会详细解释
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, econds(1))使用上面这个ssc对象,就可以创建一个lines变量用来表示从TCP接收的数据流了,指定机器名为localhost端口号为9999
// 创建一个连接到hostname:port的DStream, 下面代码中使用的是localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)lines中的每一条记录都是TCP中的一行文本信息。接下来,使用空格将每一行语句进行分割。
// 将每一行分割成单词
val words = lines.flatMap(_.split(" "))上面使用的flatMap操作是一个一对多的DStream操作,在这里表示的是每输入一行记录,会根据空格生成多个单词,这些单词形成一个新的DStream words。接下来统计单词个数。
import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// 统计每个batch中的不同单词个数
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// 打印出其中前10个单词出现的次数
wordCounts.print() 上面代码中,将每一个单词使用map方法映射成(word, 1)的形式,即paris变量。然后调用reduceByKey方法,将相同单词出现的次数进行叠加,最终打印出统计的结果。
写完上面的代码,Spark Streaming程序还没有运行起来,需要写入以下两行代码使Spark Streaming程序能够真正的开始执行。
ssc.start() // 开始计算
ssc.awaitTermination() // 等待计算结束2、TCP发送数据并运行Spark Streaming程序
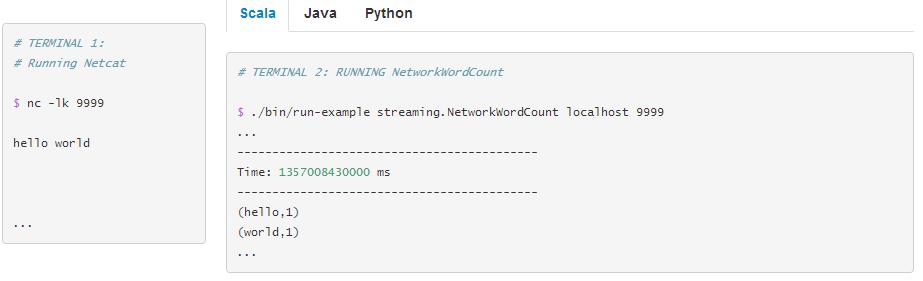
(1)运行Netcat
使用以下命令启动一个Netcat
nc -lk 9999接下来就可以在命令行中输入任意语句了。
(2)运行Spark Streaming程序
./bin/run-example streaming.NetworkWordCount localhost 9999 程序运行起来后Netcat中输入的任何语句,都会被统计每个单词出现的次数,例如
三、基本概念
这一部分详细介绍Spark Streaming中的基本概念。
1、依赖配置
Spark Streaming相关jar包的依赖也可以使用Maven来管理,写一个Spark Streaming程序的时候,需要将下面的内容写入到Maven项目中
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.0.0</version>
</dependency> 对于从Kafka,Flume,Kinesis这些数据源接收数据的情况,Spark Streaming core API中不提供这些类和接口,需要添加下面这些依赖。
| Source | Artifact |
|---|---|
| Kafka | spark-streaming-kafka-0-8_2.11 |
| Flume | spark-streaming-flume_2.11 |
| Kinesis | spark-streaming-kinesis-asl_2.11 [Amazon Software License] |
2、初始化StreamingContext
Spark Streaming程序的主要入口是一个StreamingContext对象,在程序的开始,需要初始化该对象,代码如下
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1)) 其中的参数appName是当前应用的名称,可以在Cluster UI上进行显示。master是Spark的运行模式,可以参考 Spark, Mesos or YARN cluster URL,或者设置成local[*]的形式在本地模式下运行。在生产环境中运行Streaming应用时,一般不会将master参数写死在代码中,而是在使用spark-submit命令提交时动态传入--master参数,具体可以参考 launch the application with spark-submit 。
至于batch时间间隔的设置,需要综合考虑程序的性能要求以及集群可提供的资源情况。
也可以基于SparkContext对象,生成一个StreamingContext对象,使用如下代码
import org.apache.spark.streaming._
val sc = ... // 已有的SparkContext对象
val ssc = new StreamingContext(sc, Seconds(1))当context初始化后,还需要做的工作有:
- 根据数据源类型生成输入
DStreams - 通过调用
transformation以及输出操作处理输入的DStreams - 使用代码
streamingContext.start()启动程序,开始接收并处理数据 - 使用代码
streamingContext.awaitTermination()等待程序运行终止(包括手动停止,或者遇到Error后退出应用) - 可以使用
streamingContext.stop()手动停止应用
需要注意的点:
- 当一个
context开始运行后,不能再往其中添加新的计算逻辑 - 当一个
context被停止后,不能restart - 在一个JVM中只能同时有一个
StreamingContext对象处于运行状态 StreamingContext中的stop()方法同样会终止SparkContext。如果只需要停止StreamingContext,将stop()方法的可选参数设置成false,避免SparkContext被终止- 一个
SparkContext对象,可以用于构造多个StreamingContext对象,只要在新的StreamingContext对象被创建前,旧的StreamingContext对象被停止即可。
3、离散化数据流(Discretized Streams, DStreams)
DStream是Spark Streaming中最基本最重要的一个抽象概念。DStream由一系列的数据组成,这些数据既可以是从数据源接收到的数据,也可以是从数据源接收到的数据经过transform操作转换后的数据。从本质上来说一个DStream是由一系列连续的RDDs组成,DStream中的每一个RDD包含了一个batch的数据。

DStream上的每一个操作,最终都反应到了底层的RDDs上。比如,在前面那个Word Count代码中将lines转化成words的逻辑,lines上的flatMap操作就以下图中所示的形式,作用到了每一个底层的RDD上。
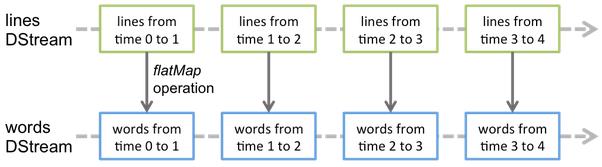
这些底层RDDs上的转换操作会有Spark Engine进行计算。对于开发者来说,DStream提供了一个更方便使用的高阶API,从而开发者无需过多的关注每一个转换操作的细节。
DStream上可以执行的操作后续文章中会有进一步的介绍。
4、输入和接收DStream
(1)基本数据源
在前面Word Count的示例程序中,已经使用到了ssc.socketTextStream(...),这个会根据TCP socket中接收到的数据创建一个DStream。除了sockets之外,StreamingContext API还支持以文件为数据源生成DStream。
- 文件数据源:如果需要从文件系统,比如HDFS,S3,NFS等中接收数据,可以使用以下代码
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)Spark Streaming程序会监控用户输入的dataDirectory路径,接收并处理该路径中的所有文件,不过不支持子文件夹中的文件。
需要注意的地方有:
a、所有的文件数据格式必须相同
b、该路径下的文件应该是原子性的移动到该路径,或者重命名到该路径
c、文件进入该路径后不可再发生变化,所以这种数据源不支持数据连续写入的形式
对于简单的text文件,有一个简单的StreamingContext.textFileStream(dataDirectory)方法来进行处理。并且文件数据源的形式不需要运行一个receiver进程,所以对Execution的核数没有要求。
- 基于自定义Receiver的数据源:DStream也支持从用户自定义Receivers中读取数据。
- RDDs序列数据源:使用
streamingContext.queueStream(queueOfRDDs),可以将一系列的RDDs转化成一个DStream。该queue中的每一个RDD会被当做DStream中的一个batcn,然后以Streaming的形式处理这些数据。
(2)高阶数据源
(3)自定义数据源
除了上面两类数据源之外,也可以支持自定义数据源。自定义数据源时,需要实现一个可以从自定义数据源接收数据并发送到Spark中的用户自定义receiver。具体可以参考 Custom Receiver Guide。
(4)数据接收的可靠性
5、DStreams上的Transformations
类似于RDDs,transformations可以使输入DStream中的数据内容根据特定逻辑发生转换。DStreams上支持很多RDDs上相同的一些transformations。
具体含义和使用方法可参考另一篇博客:Spark Streaming中的操作函数分析
在上面这些transformations中,有一些需要进行进一步的分析
(1)UpdateStateByKey操作
(2)Transform操作
transform操作及其类似的一些transformwith操作,可以使DStream中的元素能够调用任意的RDD-to-RDD的操作。可以使DStream调用一些只有RDD才有而DStream API没有提供的算子。例如,DStream API就不支持一个data DStream中的每一个batch数据可以直接和另外的一个数据集做join操作,但是使用transform就可以实现这一功能。这个操作可以说进一步丰富了DStream的操作功能。
再列举一个这个操作的使用场景,将某处计算到的重复信息与实时数据流中的记录进行join,然后进行filter操作,可以当做一种数据清理的方法。
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // 一个包含重复信息的RDD
val cleanedDStream = wordCounts.transform(rdd => {
rdd.join(spamInfoRDD).filter(...) // 将重复信息与实时数据做join,然后根据指定规则filter,用于数据清洗
...}) 这里需要注意的是,transform传入的方法是被每一个batch调用的。这样可以支持在RDD上做一些时变的操作,即RDD,分区数以及广播变量可以在不同的batch之间发生变化。
(3)Window操作
Spark Streaming提供一类基于窗口的操作,这类操作可以在一个滑动窗口中的数据集上进行一些transformations操作。下图展示了窗口操作的示例
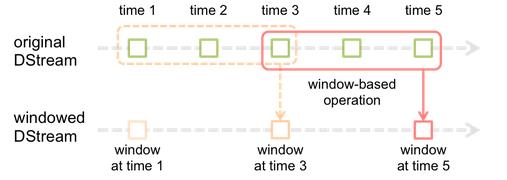
上图中,窗口在一个DStream源上滑动,DStream源中暴露在该窗口中的RDDs可以让这个窗口进行相关的一些操作。在上图中可以看到,该窗口中任一时刻都只能看到3个RDD,并且这个窗口每2秒中往前滑动一次。这里提到的两个参数,正好是任意一个窗口操作都必须指定的。
- 窗口长度:例如上图中,窗口长度为3
滑动间隔:指窗口多长时间往前滑动一次,上图中为2。
需要注意的一点是,上面这两个参数,必须是batch时间的整数倍,上图中的batch时间为1。
接下来展示一个简单的窗口操作示例。比如说,在前面那个word count示例程序的基础上,我希望每隔10秒钟就统计一下当前30秒时间内的每个单词出现的次数。这一功能的简单描述是,在
paris DStream的当前30秒的数据集上,调用reduceByKey操作进行统计。为了实现这一功能,可以使用窗口操作reduceByKeyAndWindow。
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10)) 更多的窗口操作可以参考:Spark Streaming中的操作函数分析
6、DStreams上的输出操作
DStream上的输出操作,可以使DStream中的数据发送到外部系统,比如数据库或文件系统中。DStream只有经过输出操作,其中的数据才能被外部系统使用。并且下面这些输出操作才真正的触发DStream对象上调用的transformations操作。这一点类似于RDDs上的Actions算子。
输出操作的使用和功能请参考:Spark Streaming中的操作函数分析
下面主要进一步分析foreachRDD操作往外部数据库写入数据的一些注意事项。
dstream.foreachRDD是DStream输出操作中最常用也最重要的一个操作。关于这个操作如何正确高效的使用,下面会列举出一些使用方法和案例,可以帮助读者在使用过程中避免踩到一些坑。
通常情况下,如果想把数据写入到某个外部系统中时,需要为之创建一个连接对象(比如提供一个TCP连接工具用于连接远程服务器),使用这个连接工具才能将数据发送到远程系统。在Spark Streaming中,开发者很可能会在Driver端创建这个对象,然后又去Worker端使用这个对象处理记录。比如下面这个例子
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // 在driver端执行
rdd.foreach { record =>
connection.send(record) // 在wroker端执行
}} 上面这个使用方法其实是错误的,当在driver端创建这个连接对象后,需要将这个连接对象序列化并发送到wroker端。通常情况下,连接对象都是不可传输的,即wroker端无法获取该连接对象,当然也就无法将记录通过这个连接对象发送出去了。这种情况下,应用系统的报错提示可能是序列化错误(连接对象无法序列化),或者初始化错误(连接对象需要在wroker端完成初始化),等等。
正确的做法是在worker端创建这个连接对象。
但是,即使是在worker创建这个对象,又可能会犯以下错误。
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}} 上面代码会为每一条记录创建一个连接对象,导致连接对象太多。 连接对象的创建个数会受到时间和系统资源情况的限制,因此为每一条记录都创建一个连接对象会导致系统出现不必要的高负载,进一步导致系统吞吐量降低。
一个好的办法是使用rdd.foreachPartition操作,然后为RDD的每一个partition,使一个partition中的记录使用同一个连接对象。如下面代码所示
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}}
最后,可以通过使用连接对象池进一步对上面的代码进行优化。使用连接对象池可以进一步提高连接对象的使用效率,使得多个RDDs/batches之间可以重复使用连接对象。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// 连接对象池是静态的,并且建立对象只有在真正使用时才被创建
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // 使用完之后,将连接对象归还到池中以便下一次使用
}}需要注意的是,连接对象池中的对象最好设置成懒生成模式,即在真正使用时才去创建连接对象,并且给连接对象设置一个生命周期,一定时间不使用则注销该连接对象。
总结一下关键点:
DStreams的transformations操作是由输出操作触发的,类似于RDDs中的actions操作。上面列举出某些DStream的输出操作中可以将其中的元素转化成RDD,进而可以调用RDD提供的一些API操作,这时如果对RDD调用actions操作会立即强制对接收到的数据进行处理。因此,如果用户应用程序中DStream不需要任何的输出操作,或者仅仅对DStream使用一些类似于dstream.foreachRDD操作但是在这个操作中不调用任何的RDD action操作时,程序是不会进行任何实际运算的。系统只会简单的接收数据,任何丢弃数据。- 默认情况下,输出操作是顺序执行的。
7、累加器和广播变量
Spark Streaming的累加器和广播变量无法从checkpoint恢复。如果在应用中既使用到checkpoint又使用了累加器和广播变量的话,最好对累加器和广播变量做懒实例化操作,这样才可以使累加器和广播变量在driver失败重启时能够重新实例化。参考下面这段代码
object WordBlacklist {
@volatile private var instance: Broadcast[Seq[String]] = null
def getInstance(sc: SparkContext): Broadcast[Seq[String]] = {
if (instance == null) {
synchronized {
if (instance == null) {
val wordBlacklist = Seq("a", "b", "c")
instance = sc.broadcast(wordBlacklist)
}
}
}
instance
}}
object DroppedWordsCounter {
@volatile private var instance: Accumulator[Long] = null
def getInstance(sc: SparkContext): Accumulator[Long] = {
if (instance == null) {
synchronized {
if (instance == null) {
instance = sc.accumulator(0L, "WordsInBlacklistCounter")
}
}
}
instance
}}
wordCounts.foreachRDD((rdd: RDD[(String, Int)], time: Time) => {
// Get or register the blacklist Broadcast
val blacklist = WordBlacklist.getInstance(rdd.sparkContext)
// Get or register the droppedWordsCounter Accumulator
val droppedWordsCounter = DroppedWordsCounter.getInstance(rdd.sparkContext)
// Use blacklist to drop words and use droppedWordsCounter to count them
val counts = rdd.filter { case (word, count) =>
if (blacklist.value.contains(word)) {
droppedWordsCounter += count
false
} else {
true
}
}.collect()
val output = "Counts at time " + time + " " + counts})查看完整代码请移步 source code
8、DataFrame和SQL操作
在streaming数据上也可以很方便的使用到DataFrames和SQL操作。为了支持这种操作,需要用StreamingContext对象使用的SparkContext对象初始化一个SQLContext对象出来,SQLContext对象设置成一个懒初始化的单例对象。下面代码对前面的Word Count进行一些修改,通过使用DataFrames和SQL来实现Word Count的功能。每一个RDD都被转化成一个DataFrame对象,然后注册成一个临时表,最后就可以在这个临时表上进行SQL查询了。
val words: DStream[String] = ...
words.foreachRDD { rdd =>
// 获取单例SQLContext对象
val sqlContext = SQLContext.getOrCreate(rdd.sparkContext)
import sqlContext.implicits._
// 将RDD[String]转化成DataFrame
val wordsDataFrame = rdd.toDF("word")
// 注册表
wordsDataFrame.registerTempTable("words")
// 在该临时表上执行sql语句操作
val wordCountsDataFrame =
sqlContext.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()} 查看完整代码请移步 source code.
也可以在另一线程获取到的Streaming数据上进行SQL操作(这里涉及到异步运行StreamingContext)。StreamingContext对象无法感知到异步SQL查询的存在,因此有StreamingContext对象有可能在SQL查询完成之前把历史数据删除掉。为了保证StreamingContext不删除需要用到的历史数据,需要告诉StreamingContext保留一定量的历史数据。例如,如果你想在某一个batch的数据上执行SQL查询操作,但是你这个SQL需要执行5分钟的时间,那么,需要执行streamingContext.remember(Minutes(5))语句告诉StreamingContext将历史数据保留5分钟。
有关DataFrames的更多介绍,参考另一篇博客:Spark-SQL之DataFrame操作大全
9、MLlib操作
10、缓存和持久化
类似于RDDs,DStreams也允许开发者将stream中的数据持久化到内存中。在DStream对象上使用persist()方法会将DStream对象中的每一个RDD自动持久化到内存中。这个功能在某个DStream的数据需要进行多次计算时特别有用。对于窗口操作比如reduceByWindow,以及涉及到状态的操作比如updateStateByKey,默认会对DStream对象执行持久化。因此,程序在运行时会自动将窗口操作和涉及到状态的这些操作生成的DStream对象持久化到内存中,不需要开发者显示的执行persist()操作。
对那些通过网络接收到的streams数据(比如Kafka, Flume, Socket等),默认的持久化等级是将数据持久化到两个节点上,以保证其容错能力。
注意,不同于RDDs,默认情况下DStream的持久化等级是将数据序列化保存在内存中。这一特性会在后面的性能调优中进一步分析。有关持久化级别的介绍,可以参考rdd-persistence
11、检查点
当Streaming应用运行起来时,基本上需要7 * 24的处于运行状态,所以需要有一定的容错能力。检查点的设置就是能够支持Streaming应用程序快速的从失败状态进行恢复的。检查点保存的数据主要有两种:
1 . 元数据(Metadata)检查点:保存Streaming应用程序的定义信息。主要用于恢复运行Streaming应用程序的driver节点上的应用。元数据包括:
a、配置信息:创建Streaming应用程序的配置信息
b、DStream操作:在DStream上进行的一系列操作方法
c、未处理的batch:记录进入等待队列但是还未处理完成的批次
2 . 数据(Data)检查点:将计算得到的RDD保存起来。在一些跨批次计算并保存状态的操作时,必须设置检查点。因为在这些操作中基于其他批次数据计算得到的RDDs,随着时间的推移,计算链路会越来越长,如果发生错误重算的代价会特别高。
元数据检查点信息主要用于恢复driver端的失败,数据检查点主要用于计算的恢复。
(1)什么时候需要使用检查点
当应用程序出现以下两种情况时,需要配置检查点。
- 使用到状态相关的操作算子-比如updateStateByKey或者reduceByKeyAndWindow等,这种情况下必须为应用程序设置检查点,用于定期的对RDD进行检查点设置。
- Driver端应用程序恢复-当应用程序从失败状态恢复时,需要从检查点中读取相关元数据信息。
(2)检查点设置
一般是在具有容错能力,高可靠的文件系统上(比如HDFS, S3等)设置一个检查点路径,用于保存检查点数据。设置检查点可以在应用程序中使用streamingContext.checkpoint(checkpointDirectory)来指定路径。
如果想要应用程序在失败重启时使用到检查点存储的元数据信息,需要应用程序具有以下两个特性,需要使用StreamingContext.getOrCreate代码在失败时重新创建StreamingContext对象:
- 当应用程序是第一次运行时,创建一个新的
StreamingContext对象,然后开始执行程序处理DStream。 当应用程序失败重启时,可以从设置的检查点路径获取元数据信息,创建一个
StreamingContext对象,并恢复到失败前的状态。下面用Scala代码实现上面的要求。
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // 创建一个新的StreamingContext对象
val lines = ssc.socketTextStream(...) // 得到DStreams
...
ssc.checkpoint(checkpointDirectory) // 设置checkpoint路径
ssc
}
// 用checkpoint元数据创建StreamingContext对象或根据上面的函数创建新的对象
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
// 设置context的其他参数
context. ...
// 启动context
context.start()
context.awaitTermination() 如果checkpointDirectory路径存在,会使用检查点元数据恢复一个StreamingContext对象。如果路径不存在,或者程序是第一次运行,则会使用functionToCreateContext来创建一个新的StreamingContext对象。
RecoverableNetWorkWordCount示例代码演示了一个从检查点恢复应用程序的示例。
需要注意的是,想要用到上面的getOrCreate功能,需要在应用程序运行时使其支持失败自动重跑的功能。这一功能,在接下来一节中有分析。
另外,在往检查点写入数据这一过程,是会增加系统负荷的。因此,需要合理的设置写入检查点数据的时间间隔。对于小批量时间间隔(比如1秒)的应用,如果每一个batch都执行检查点写入操作,会显著的降低系统的吞吐性能。相反的,如果写入检查点数据间隔太久,会导致lineage过长。对那些状态相关的需要对RDD进行检查点写入的算子,检查点写入时间间隔最好设置成batch时间间隔的整数倍。比如对于1秒的batch间隔,设置成10秒。有关检查点时间间隔,可以使用dstream.checkpoint(checkpointInterval)。一般来说,检查点时间间隔设置成5~10倍滑动时间间隔是比较合理的。
12、部署应用程序
这一节主要讨论如何将一个Spark Streaming应用程序部署起来。
(1)需求
运行一个Spark Streaming应用程序,需要满足一下要求。
- 需要有一个具有集群管理器的集群 - 可以参考Spark应用部署文档
- 应用程序打成JAR包 - 需要将应用程序打成JAR包。接下来使用spark-submit命令来运行应用程序的话,在该JAR包中无需打入Spark和Spark Streaming相关JAR包。然而,如果应用程序中使用到了比如Kafka或者Flume等高阶数据源的话,需要将这些依赖的JAR包,以及这些依赖进一步的依赖都打入到应用JAR包中。比如,应用中使用到了
KafkaUtils的话,需要将spark-streaming-kafka-0.8_2.11以及其依赖都打入到应用程序JAR包中。 - 为Executor设置足够的内存 - 由于接收到的数据必须保存在内存中,必须为Executor设置足够的内存能容纳这些接收到的数据。注意,如果在应用程序中做了10分钟长度的窗口操作,系统会保存最少10分钟的数据在内存中。所以应用程序需要的内存除了由接收的数据决定之外,还需要考虑应用程序中的操作类型。
- 设置检查点 - 如果应用程序需要用到检查点,则需要在文件存储系统上设置好检查点路径。
- 为应用程序的Driver设置自动重启 - 为了实现driver失败后自动重启的功能,应用程序运行的系统必须能够监控driver进程,并且如果发现driver失败时能够自动重启应用。不同的集群使用不同的方式实现自动重启功能。
- Spark Standalone - 在这种模式下,driver程序运行在某个wroker节点上。并且,Standalone集群管理器会监控driver程序,如果发现driver停止运行,并且其状态码为非零值或者由于运行driver程序的节点失败导致driver失败,就会自动重启该应用。具体的监控和失败重启可以进一步参考Spark Standalone guide
- YARN - Yarn支持类似的自动重启应用的机制。更多的细节可以进一步参考YARN的相关文档
- Mesos - Mesos使用Marathon实现了自动重启功能
- 设置write ahead logs - 从Spark-1.2版本开始,引入了一个write ahead log机制来实现容错。如果设置了WAL功能,所有接收到的数据会写入write ahead log中。这样可以避免driver重启时出现数据丢失,因此可以保证数据的零丢失,这一点可以参考前面有关介绍。通过将
spark.streaming.receiver.writeAheadLog.enable=true来开启这一功能。然而,这一功能的开启会降低数据接收的吞吐量。这是可以通过同时并行运行多个接收进程(这一点在后面的性能调优部分会有介绍)进行来抵消该负面影响。另外,如果已经设置了输入数据流的存储级别为Storagelevel.MEMORY_AND_DISK_SET,由于接收到的数据已经会在文件系统上保存一份,这样就可以关闭WAL功能了。当使用S3以及其他任何不支持flushng功能的文件系统来write ahead logs时,要记得设置spark.streaming.driver.writeAheadLog.closeFileAfterWrite以及spark.streaming.receiver.writeAheadLog.closeFileAfterWrite两个参数。 - 设置Spark Streaming最大数据接收率 - 如果运行Streaming应用程序的资源不是很多,数据处理能力跟不上接收数据的速率,可以为应用程序设置一个每秒最大接收记录数进行限制。对于Receiver模式的应用,设置
spark.streaming.receiver.maxRate,对于Direct Kafka模式,设置spark.streaming.kafka.maxRatePerPartition限制从每个Kafka的分区读取数据的速率。假如某个Topic有8个分区,spark.streaming.kafka.maxRatePerpartition=100,那么每个batch最大接收记录为800。从Spark-1.5版本开始,引入了一个backpressure的机制来避免设置这个限制阈值。Spark Streaming会自动算出当前的速率限制,并且动态调整这个阈值。通过将spark.streaming.backpressure.enabled为true开启backpressure功能。
(2)升级应用代码
如果运行中的应用程序有更新,需要运行更新后的代码,有以下两种机制。
- 升级后的应用程序直接启动,与现有的应用程序并行执行。在新旧应用并行运行的过程中,会接收和处理一部分相同的数据。
- Gracefully停掉正在运行的应用,然后启动升级后的应用程序,新的应用程序会从旧的应用程序停止处开始继续处理数据。需要注意的是,使用这种方式,需要其数据源具有缓存数据的能力,否则在新旧应用程序衔接的间歇期内,数据无法被处理。比如Kafka和Flume都具有数据缓存的能力。并且,在这种情况下,再从旧应用程序的检查点重新构造
SparkStreamingContext对象不再合适,因为检查点中的信息可能不包含更新的代码逻辑,这样会导致程序出现错误。在这种情况下,要么重新指定一个检查点,要么删除之前的检查点。
13、监控应用程序
在Spark Streaming应用程序运行时,Spark Web UI页面上会多出一个Streaming的选项卡,在这里面可以显示一些Streaming相关的参数,比如Receiver是否在运行,接收了多少记录,处理了多少记录等。以及Batch相关的信息,包括batch的执行时间,等待时间,完成的batch数,运行中的batch数等等。这里面有两个时间参数需要注意理解一些:
- Processing Time - 每一个batch中数据的处理时间
Scheduling Delay - 当前batch从进入队列到开始执行的延迟时间
如果处理时间一直比batch时间跨度要长,或者延迟时间逐渐增长,表示系统已经无法处理当前的数据量了,这时候就需要考虑如何去降低每一个batch的处理时间。如何降低batch处理时间,可以参考第四节。
除了监控页面之外,Spark还提供了StreamingListener接口,通过这个接口可以获取到receiver以及batch的处理时间等信息。
四、性能调优
为了使Spark Streaming应用能够更好的运行,需要进行一些调优设置,这一节会分析一些性能调优中的参数和设置规则。在性能调优方面,主要需要考虑以下两个问题:
- 如何充分利用集群资源降低每个Batch的处理时间
- 如何设置合理的Batch大小,以便应用能够及时处理接收到的这些数据
1、降低每个Batch的处理时间
接下来的内容在Spark性能调优中已有介绍,这里再次强调一下在Streaming中需要注意的一些地方。
(1)接收数据进程的并行度
通过网络(比如Kafka, Flume, socket等)接收到的数据,首先需要反序列化然后保存在Spark中。当数据接收成为系统的瓶颈时,就需要考虑如何提高系统接收数据的能力了。每一个输入的DStream会在一个Worker节点上运行一个接收数据流的进程。如果创建了多个接收数据流进程,就可以生成多个输入DStream了。比如说,对于Kafka数据源,如果使用的是一个DStream接收来自两个Topic中的数据的话,就可以将这两个Topic拆开,由两个数据接收进程分开接收。当用两个receiver接收到DStream后,可以在应用中将这两个DStream再进行合并。比如下面代码中所示
val numStreams = 5
val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...) }
val unifiedStream = streamingContext.union(kafkaStreams)
unifiedStream.print() 需要注意一个参数spark.streaming.blockInterval。对于Receiver来说,接收到的数据在保存到Spark内存中之前,会以block的形式汇聚到一起。每个Batch中block的个数决定了程序运行时处理这些数据的task的个数。每一个receiver的每一个batck对应的task个数大致为(batch时间间隔 / block时间间隔)。比如说对于一个2m的batch,如果block时间间隔为200ms那么,将会有10个task。如果task的数量太少,对数据的处理就不会很高效。在batch时间固定的情况下,如果想增大task个数,那么就需要降低blockInterval参数了,这个参数默认值为200ms,官方建议的该参数下限为50ms,如果低于50ms可能会引起其他问题。
另一个提高数据并发处理能力的方法是显式的对接收数据重新分区,inputStream.repartition(<number of partitions>)。
(2)数据处理的并行度
对于reduceByKey和reduceByKeyAndWindow操作来说,并行task个数由参数spark.default.parallelism来控制。如果想要提高数据处理的并行度,可以在调用这类方法时,指定并行参数,或者将spark.default.parallelism参数根据集群实际情况进行调整。
(3)数据序列化
可以通过调整序列化相关的参数,来提高数据序列化性能。在Streaming应用中,有两类数据需要序列化操作。
- 输入数据:默认情况下,Receiver接收到的数据以
StorageLevel.MEMORY_AND_DIS_SER_2的形式保存在Executor的内存中。也就是说,为了降低GC开销,这些数据会被序列化成bytes形式,并且还考虑到executor失败的容错。这些数据首先会保存在内存中,当内存不足时会spill到磁盘上。使用这种方式的一个明显问题是,Spark接收到数据后,首先需要反序列化这些数据,然后再按照Spark的方式对这些数据重新序列化。 Streaming操作中持久化的RDD:Streaming计算产生的RDD可能也会持久化到内存中。比如窗口操作函数会将数据缓存起来以便后续多次使用。并且Streaming应用中,这些数据的存储级别是
StorageLevel.MEMORY_ONLY_SET(Spark Core的默认方式是StorageLevel.MEMORY_ONLY)。Streaming对这些数据多了一个序列化操作,这主要也是为了降低GC开销。在上面这两种情况中,可以使用
Kyro方式对数据进行序列化,同时降低CPU和内存的开销。有关序列化可以进一步参考Spark调优。对于Kyro方式的参数设置,请参考Spark Kyro参数设置。
一般情况下,如果需要缓存的数据量不大,可以直接将数据以非序列化的形式进行存储,这样不会明显的带来GC的开销。比如说,batch时间只有若干秒,并且没有使用到窗口函数操作,那么可以在持久化时显示的指定存储级别,避免持久化数据时对数据的序列化操作。
(4)提高task启动性能
如果每秒启动的task个数太多(一般指50个以上),那么对task的频繁启动也是一个不容忽视的损耗。遇到这种情况时,需要考虑一下Execution模式了。一般来说,在Spark的Standalone模式以及coarse-grained Mesos模式下task的启动时间会比fine-grained Mesos模式要低。
2、如何正确设置Batch时间间隔
为了使一个Spark Streaming应用在集群上稳定运行,需要保证应用在接收到数据时能够及时处理。如果处理速率不匹配,随着时间的积累,等待处理的数据将会越来越多,最终导致应用无法正常运行。最好的情况是batch的处理时间小于batch的间隔时间。所以,正确合理的设置Batch时间间隔是很重要的。
3、内存调整
有关Spark内存的使用以及Spark应用的GC性能调节的更多细节在Spark调优中已经有了更加详细的描述。这里简单分析一些Spark Streaming应用程序会用到的参数。
一个Spark Streaming应用程序需要使用集群多少内存资源,很大程度上是由该应用中的具体逻辑来决定的,即需要看应用程序中的transformations的类型。比如代码中使用到长达10分钟的窗口操作时,就需要使用到能够把10分钟的数据都保存到内存中的内存量。如果使用updateStateByKey这种操作,而数据中不同key特别多,也会使用更多的内存。如果应用的逻辑比较简单,仅仅是接收-过滤-存储等一系列操作时,消耗的内存量会明显减少。
默认情况下,receivers接收到的数据会以StorageLevel.MEMORY_AND_DISK_SER_2级别进程存储,当内存中容纳不下时会spill到磁盘上,但是这样会降低应用的处理性能,所以为了应用能够更高效的运行,最好还是多分配一些内存以供使用。一般可以通过在少量数据的情况下,评估一下数据使用的内存量,继而计算出应用正式部署时需要分配的总内存量大小。
内存调节的另一方面是垃圾回收的设置。对一个低延迟的应用系统来说,JVM在垃圾回收时导致应用长时间暂停运行是一个很讨厌的场景。
下面有一些可用于调节内存使用量和GC性能的方面:
- DStreams的持久化级别:在前面已经提到,输入数据在默认情况下会以序列化的字节形式进行持久化。与非序列化存储相比,这样会降低内存使用率和降低垃圾回收的负担。使用
Kryo方式进行序列化能够进一步降低序列化后数据大小和内存的使用。想要进一步降低内存的使用量,可以在数据上再增加一个压缩功能,通过参数spark.rdd.compress来设置。 - 清除旧数据:默认情况下,所有输入数据和DStream通过不同的
transformations持久化的数据都会自动进行清理。Spark Streaming根据transformations的不同来决定哪些数据需要被清理掉。例如,当使用10分钟的窗口函数时,Spark Streaming会保存最少10分钟的数据。想要数据保存更长时间,可以设置streamingContext.remenber参数。 - 使用CMS垃圾回收算法:特别建议使用CMS垃圾回收机制来降低GC压力。driver上通过设置
spark-submit命令的--driver-java-options参数来指定,executor上通过设置spark.executor.extraJavaOptions参数来指定。 - 其他建议:进一步降低GC负担,可以使用以下一些方法。
- 使用Tachyon提供的
OFF_HEAP存储级别来持久化RDDs,可以参考RDD Persistence - 降低heap大小,使用更多executors。这样可以降低每个JVM堆的GC压力。
- 使用Tachyon提供的
五、容错性
本节主要讨论Spark Streaming应用程序失败后的处理办法。
1、背景
2、定义
3、基本概念
4、数据接收方式
(1)Files输入
(2)基于Receiverd 数据源
(3)Kafka Direct输入方式
5、输出操作
六、Spark Streaming的升级
七、继续
以上是关于Spark Streaming编程指南的主要内容,如果未能解决你的问题,请参考以下文章
Apache Spark 2.2.0 中文文档 - Spark Streaming 编程指南 | ApacheCN
Apache Spark 2.2.0 中文文档 - Spark Streaming 编程指南 | ApacheCN
Apache Spark 2.2.0 中文文档 - Structured Streaming 编程指南 | ApacheCN