基于ARM处理器的反汇编器软件简单设计及实现
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于ARM处理器的反汇编器软件简单设计及实现相关的知识,希望对你有一定的参考价值。
写在前面
2012年写的,仅供参考
反汇编的目的
缺乏某些必要的说明资料的情况下, 想获得某些软件系统的源代码、设计思想及理念, 以便复制, 改造、移植和发展;
从源码上对软件的可靠性和安全性进行验证,对那些直接与CPU 相关的目标代码进行安全性分析;
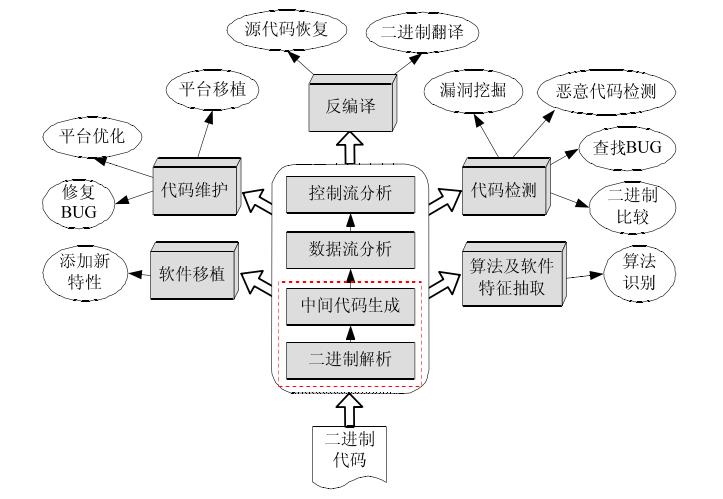
涉及的主要内容
- 分析ARM处理器指令的特点,以及编译以后可执行的二进制文件代码的特征;
- 将二进制机器代码经过指令和数据分开模块的加工处理;
- 分解标识出指令代码和数据代码;
- 然后将指令代码反汇编并加工成易于阅读的汇编指令形式的文件;
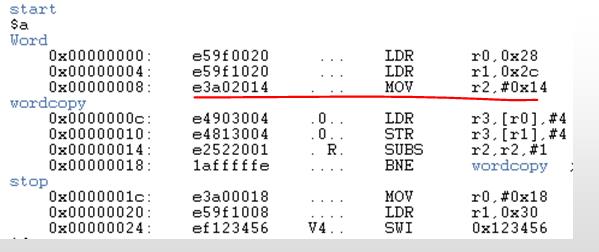
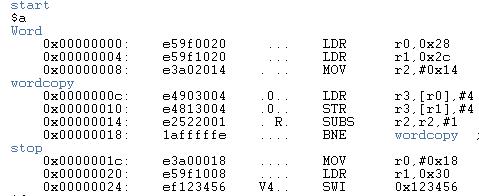
下面给出个示例,汇编源代码,对应的二进制代码,以及对应的反汇编后的结果
源代码:

二进制代码:

反汇编后的结果:
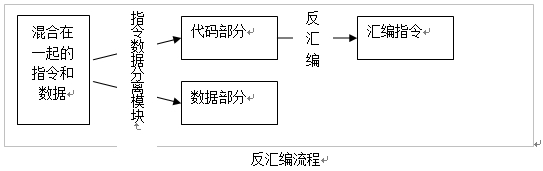
反汇编软件要完成的工作就是在指令和数据混淆的二进制BIN文件中,分解并标识出指令和数据,然后反汇编指令部分,得到易于阅读的汇编文件,如下图:
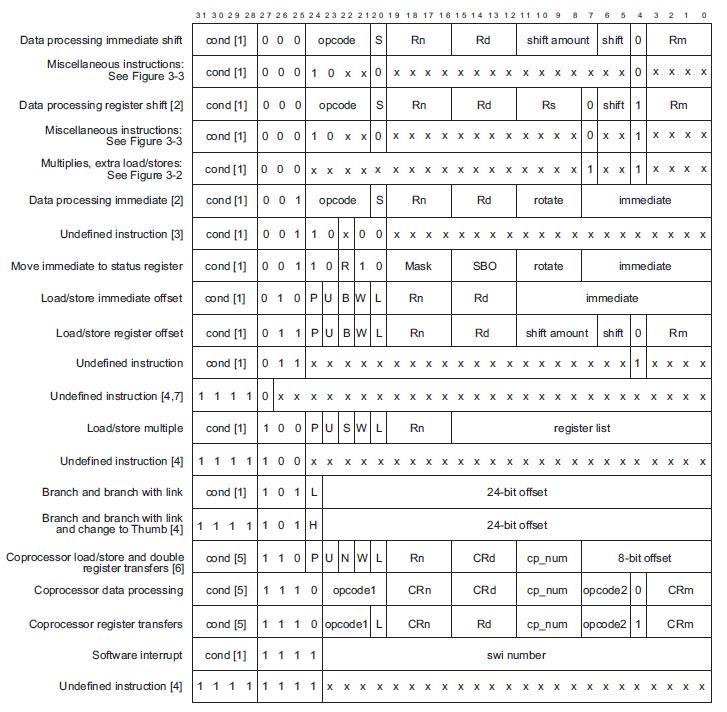
ARM体系结构及指令编码规则分析
略,请参考相关资料,如ARM Limited. ARM Architecture Reference Manual [EB/OL]. http://infocenter.arm.com/等;
主要可参考下图,ARM指令集的编码:
ARM可执行二进制BIN文件分析
目前主要的ARM可执行文件种类:
ELF文件格式:Linux系统下的一种常用、可移植目标文件格式;
BIN文件:直接的二进制文件,内部没有地址标记,里面包括了纯粹的二进制数据;一般用编程器烧写时,从0开始,而如果下载运行,则下载到编译时的地址即可;
HEX格式:Intel HEX文件是记录文本行的ASCII文本文件;
本文主要研究BIN文件的反汇编;
BIN映像文件的结构
ARM程序运行时包含RO,RW,ZI三部分内容,RO(READONLY),是代码部分,即一条条指令,RW(READWRITE),是数据部分,ZI,是未初始化变量。其中RO和RW会包含在映像文件中,因为一个程序的运行是需要指令和数据的,而ZI是不会包含在映像文件的,因为其中数据都为零,程序运行前会将这部分数据初始化为零。
ARM映像文件是一个层次性结构的文件,包括了域(region),输出段(output section)和输入段(input section)。一个映像文件由一个或者多个域组成,每个域最多由三个输出段(RO,RW,IZ)组成,每个输出段又包含一个或者多个输入段,各个输入段包含了目标文件中的代码和数据。
- 域(region):一个映像文件由一个或多个域组成。是组成映象文件的最大结构。所谓域指的就是整个bin映像文件所在的区域,又分为加载域和运行域,一般简单的程序只有一个加载域。
- 输出段(output section):有两个输出段,RO和RW。
- 输入段(input section):两个输入段,CODE和DATA部分,CODE部分是代码部分,只读的属于RO输出段,DATA部分,可读可写,属于RW输出段。
ARM的BIN映像文件的结构图

举一个例子,ADS1.2自带的examples里的程序
AREA Word, CODE, READONLY ; name this block of code num EQU 20 ; Set number of words to be copied ENTRY ; mark the first instruction to call start LDR r0, =src ; r0 = pointer to source block LDR r1, =dst ; r1 = pointer to destination block MOV r2, #num ; r2 = number of words to copy wordcopy LDR r3, [r0], #4 ; a word from the source STR r3, [r1], #4 ; store a word to the destination SUBS r2, r2, #1 ; decrement the counter BNE wordcopy ; ... copy more stop MOV r0, #0x18 ; angel_SWIreason_ReportException LDR r1, =0x20026 ; ADP_Stopped_ApplicationExit SWI 0x123456 ; ARM semihosting SWI AREA BlockData, DATA, READWRITE src DCD 1,2,3,4,5,6,7,8,1,2,3,4,5,6,7,8,1,2,3,4 dst DCD 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 END
可以看出,该程序由两部分组成,CODE和DATA,即代码部分和数据部分。其中代码部分,READONLY,属于RO输出段;数据部分,READWRITE,属于RO输出段。
接下来再看看上述代码经过编译生成的BIN映像文件的二进制形式,及该映像文件反汇编后的汇编文件,如下图:
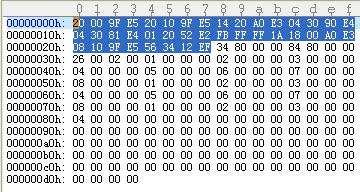
从图中我们很容易发现,BIN文件分成了两部分,指令部分和数据部分。先看一下左图,从中我们发现,BIN文件的第一条指令编码是0xe59f0020,即右图中的00000000h到00000003h,由于存储方式的原因,小端模式,指令的低字节存放在低地址部分,不过这不影响我们的分析。在BIN文件中从00000000h开始一直到00000027h都是指令部分,即RO输出段,最后一条指令0xef123456存储在在BIN文件的00000024h到00000027h。剩下的为数据部分,即RW输出段,有兴趣的读者可以对照源代码一一查找之间的对应关系。
ARM反汇编软件设计要解决的主要问题
一、指令与数据的分离
冯·诺依曼机器中指令和数据是不加区别共同存储的,以 0、1 二进制编码形式存在的目标代码对于分析人员来说,很难读懂其含义。二进制程序中指令和数据混合存放,按地址寻址访问,反汇编如果采取线性扫描策略,将无法判断读取的二进制编码是指令还是数据,从而无法实现指令和数据的分离。
那么,怎样才能实现指令和数据的分离?
众所周知,凡是指令,控制流是必经之处,凡是数据,数据流是必到之处,存取指令一定会访问,对于一般指令,控制流是按地址顺序递增而走向的,只有在出现各种转移指令时,控制流才出现偏离。因此,抓住控制流这一线索,即跟踪程序的控制流[9]走向而遍历整个程序的每一条指令,从而达到指令与数据分开的目的。
怎样才能跟踪程序的控制流呢?
一般来说控制流与控制转移指令有关,控制转移指令一般可分为两大类:
- 单分支指令,即直接跳转,如B;BL;MOV PC,**;LDR PC,**等等;
- 双分支指令,有条件的跳转,如BNE;MOVNE PC,**等等
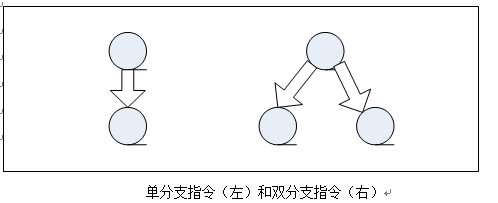
当该指令为双分支指令时,会有两个转向地址,我们把条件满足时的转向地址称为显示地址,条件不满足时的地址称为隐式地址。
在跟踪控制流的过程中,还要设置三个表:
(1)段表,将所有转移指令除条件转移的转移地址填入此表包括本指令地址和转向地址。其实可以不要这个表,但是加进去,会得到若干段的代码段,比较清晰明了。
(2)返回表,用于记录程序调用时的返回地址。
(3)显示表,碰到双分支指令时,将其显示地址和现场(程序各寄存器的值)填入该表中。
以上都准备好之后,就可以开始跟踪程序控制流了具体步骤如下:
(1)将程序的起始地址填入段表,且作为当前地址。
(2)按当前地址逐条分析指令类型,若非无条件转移指令及二分支指令,则直至终结语句并转(7), 否则转(3)。
(3)若为无条件转移指令(B指令,MOV PC,0x16等),则将此指令所在地址填段表,其显式地址填段表,且将显式地址作为当前地址,然后转(2),否则转(4)。
(4)若为无条件转移指令子程序调用指令(BL指令),则将此指令所在地址填段表,返回地址和现场信息填入返回表,显式地址填段表,且将显式地址作为当前地址,然后转 (2), 否则转(5)。
(5)若为无条件转移指令中的返回指令(MOV PC,LR),则在返回地址表中按“后进先出”原则找到返回地址,将此指令所在地址填段表,其返回地址填段表,且将返回地址作为当前地址,然后转(2),否则转(6)。
(6)若为二叉点指令(BEQ,MOVEQ PC,0x16等等), 则将显式地址和现场信息填入显式表,然后将隐式地址作为当前地址转(2)。
(7)判显式表空否,若空则算法终止,否则从显式表中按“先进先出”顺序取出一个显式地址作为当前地址,且恢复当时的现场信息转(2)。
经过以上处理,可以遍历到所有的指令,且当访问到该条指令后,要把改地址处的指令标记为指令。接下来可以采用线性扫描策略,当遇到标记为指令的二进制代码时,把它反汇编成汇编指令即可。
不过,在实现跟踪程序控制流过程中还有一个比较难处理的问题,就是间接转移类指令的处理,因为这类指令的转移地址隐含在寄存器或内存单元中,无法由指令码本身判断其值,而且这些隐含在寄存器内或内存单元中的值往往在程序执行时,被动态地进行设置或修改,因此很难判断这类指令的转移地址,从而难以完整的确定程序的指令区。
本软件处理这个问题的方法是设置多个寄存器全局变量,在紧跟程序控制流的过程中,实时更新各寄存器的值,因此可以确定这类指令的转移地址。
二、代码部分的反汇编
ARM指令集中的每天指令都有一个对应的二进制代码,如何从二进制代码中翻译出对应的指令,即代码部分反汇编所要完成的工作。
ARM 指令的一般格式可以表示为如下形式:
<opcode>{condition}{S}<operand0>{!},<operand1>{, <operand2>}
指令格式中<·>符号内的项是必须的,{·}符号内的项是可选的,/ 符号表示选其中之一,其中opcode 表示指令操作符部分,后缀 conditon、S 及!构成了指令的条件词,operand0、operand1、operand2 为操作数部分。指令反汇编就是将指令的各组成部分解析出来。
为了使指令反汇编更加清晰、高效,可以采用分类的思想方法来解决该问题,把那些具有相同编码特征的指令分成同一种类型的指令,然后为每一类指令设计一个与之对应的处理函数。
指令的反汇编的步骤,首先是判断哪条指令,可以由操作符及那些固定位来确定,然后是指令条件域的翻译,这个与二进制编码也有唯一的对应关系,然后操作数的翻译,在操作数的翻译过程中,可能涉及到各种操作数的计算方法,移位操作等情况。
ARM反汇编软件的设计
ARM反汇编软件的总体设计方案如下图:
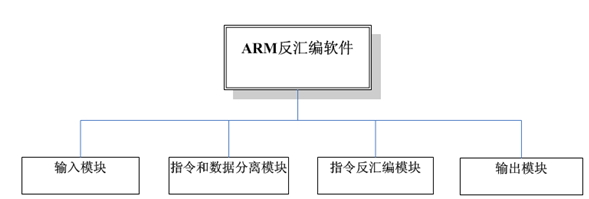
其中,各模块主要完成以下功能:
- 输入模块:要解决如何从外部文件中读取二进制格式的文件,另外对读进来的目标代码要合理组织和存储,便于接下来的后续处理。
- 指令和数据分离模块:在内存中对读进来的二进制源代码进行分析,指令流可以到达的部分标识为代码,最后剩下的指令流未经过的部分为数据,这样就分离出代码和数据。
- 指令反汇编模块:对分离出来的代码段部分,按照各条指令编码的对应关系进行反汇编,生成目标代码对应的汇编文件,包括ARM指令地址,ARM指令,可以用于阅读。
- 输出模块:即要将反汇编后的汇编文件显示在窗口,且可以生成文件在磁盘上。
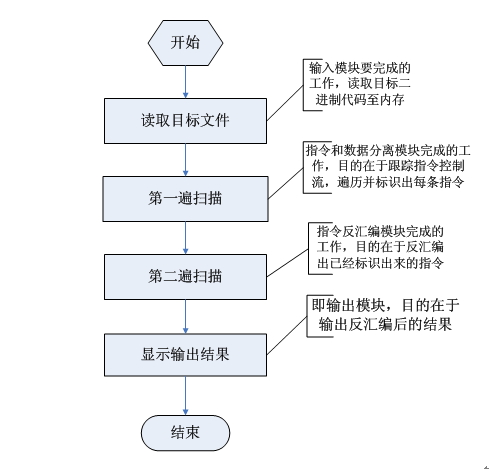
ARM处理器反汇编软件流程
ARM反汇编软件的整体工作流程如下图所示,首先是读取目标二进制文件至内存,然后采用两遍扫描的策略,第一遍扫描的目的是区分指令和数据,第二遍扫描是将指令部分反汇编成汇编指令形式,将数据部分直接翻译成数据,最后将结果输出显示。
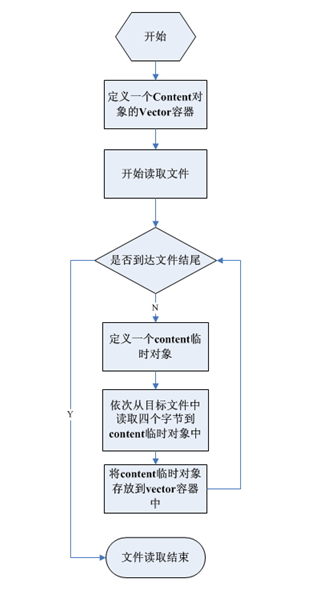
模块设计-输入模块
输入模块的流程图如下图所示,首先从目标二进制代码中读取四个字节存放到Content对象里,再将Content对象存放到Vector容器里,然后按上述操作继续读取文件,直到文件结尾。这里有一点要说明的是,由于时间等原因,本软件只考虑32位ARM指令的反汇编,Thumb指令反汇编不会涉及,所以每次都读取4个字节。
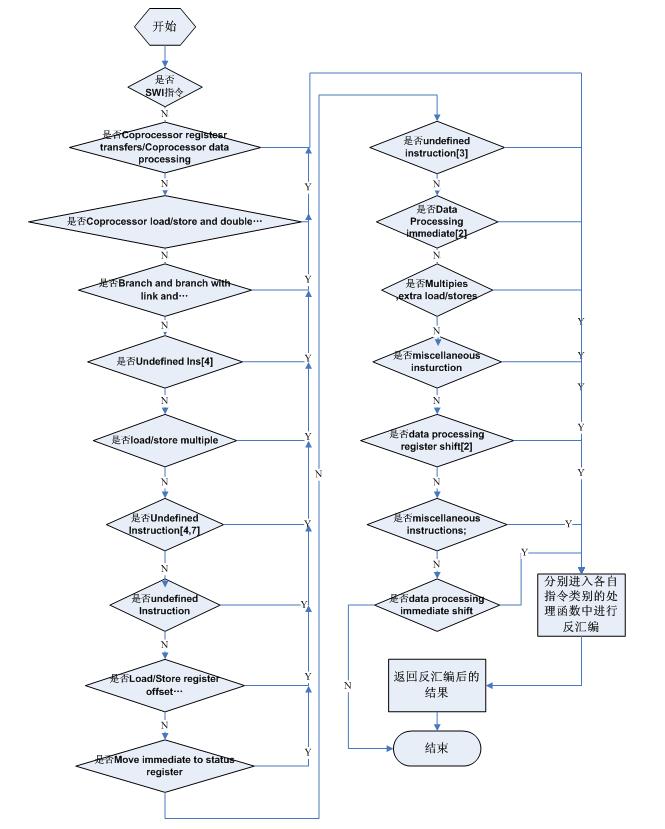
模块设计-指令和数据分离模块
指令和数据分离模块的设计如下图所示,由于指令和数据分离模块设计的关键是跟踪程序的控制流,标识出每一条指令,所以此模块的关键就是要遍历每一条指令,而遍历每一条指令的关键是要紧跟PC值。
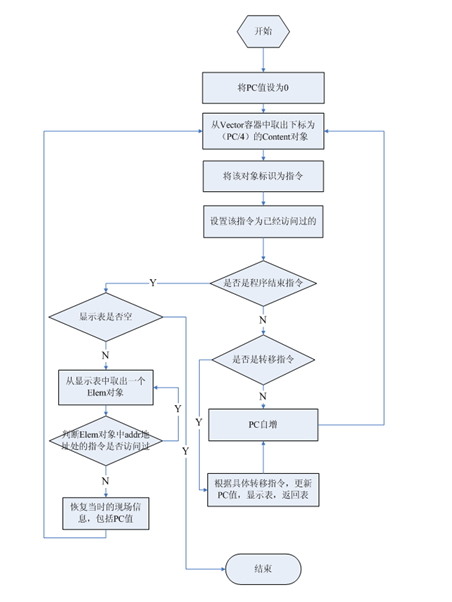
关于段表,显示表,返回表的概念前面已经说明过了。另外,在程序流程图中的“根据具体转移指令,更新PC值,显示表,返回表”,这里的具体情况如下:
(1)若为无条件转移指令(B指令等,MOV PC,0x16),则将此指令所在地址填段表,其显式地址填段表,且将显式地址作为当前PC地址。
(2)若为无条件转移指令子程序调用指令(BL指令),则将此指令所在地址填段表,返回地址填入返回地址表,显式地址填段表,且将显式地址作为当前PC地址
(3)若为无条件转移指令中的返回指令(MOV PC,LR),则在返回地址表中按“后进先出”原则找到返回地址,将此指令所在地址填段表,其返回地址填段表,且将返回地址作为当前PC地址。
(4)若为二叉点指令(BEQ,MOVEQ PC,0x16等等), 则将显式地址填入显式地址表(还要保存当时的寄存器值),然后将隐式地址作为当前PC地址。
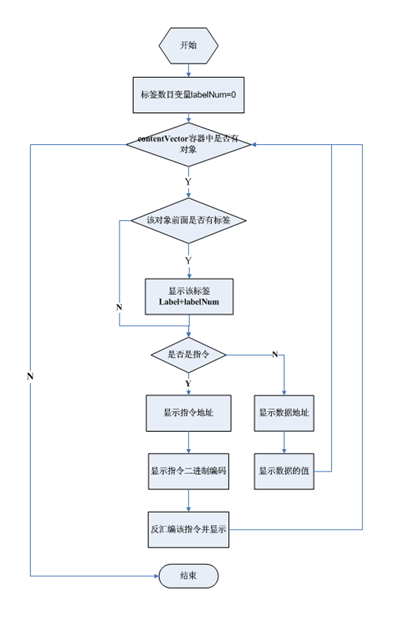
模块设计-反汇编模块
在反汇编模块中除了要反汇编指令,还要翻译数据。总的设计思想是依次从装满对象的contentVector容器中依次取出对象,判断该对象是指令还是数据,指令的话,就反汇编成汇编指令形式,数据的话,直接翻译成数据的值,如下图所示。
上述流程图是总的反汇编模块,在图中的指令反汇编部分,是该模块的重点,也是整个反汇编软件设计的重点,其流程图如下图所示。
模块设计-输出模块
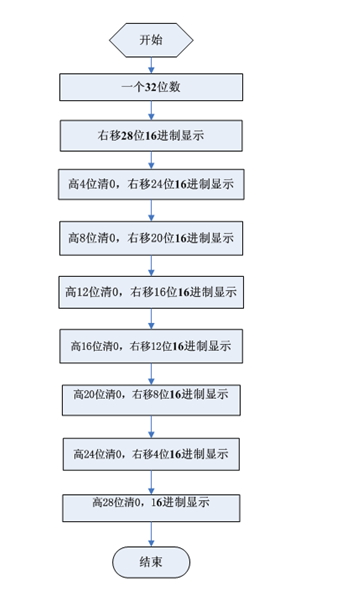
关于显示模块,比较简单,直接把结果显示出来即可,该模块跟第三个模块反汇编模块联系最紧密,在反汇编模块中,其实已经包含了输出模块。不过输出模块也有自己的特殊任务。比如说如何以十六进制形式显示一个32位数(显示地址的时候)以及如何显示一个8位数(显示读进来数据的编码,因为是一个字节一个字节读进来的,存放的时候也是一个字节一个字节存放在Content对象中),如下图就是一个显示32位数的流程图。
ARM反汇编软件的具体实现
ARM反汇编软件主要有四个大模块组成,二进制可执行代码读取模块、指令和数据分离模块、指令反汇编模块、输出模块。本章节将结合程序中的源代码主要介绍ARM反汇编软件各模块具体实现。由于时间等因素影响,本软件设计只考虑到了ARM指令,THUMB指令不在考虑范围,不过其实都是同样道理的事情,ARM指令能够实现的话,THUMB指令添加进去只是时间的问题。
一、数据组织方式
读进来的内容的组织如下所示:
class Content { public: unsigned int addr; //地址 bool isInstruction; //指令标记 bool isVisited; //访问标记 bool isHasLable; //是否有标签标记 unsigned int firstB; //第1个字节 unsigned int secondB; unsigned int thirdB; unsigned int fourthB; };
在该类中,addr表示该内容的地址,是逻辑字节地址;isInstruction判断该内容是否是指令代码;isVisited判断是否被访问过;isHasLable,判断该指令前面要不要加一个标签,firstB表示内容从左到右表示的第一个字节,secondB、thirdB、fourthB以此类推。
读源文件类
class MyRead { public: vector <Content> contentVector; //内容存储容器 void readSourceFile(char * addr); //读取源文件函数 };
内容容器contentVector,用于存储从源文件读进来的内容,4个字节为一个元素;readSourceFile方法,读取源文件二进制代码,并按个字节一个存储在容器里。
指令编码内容的组织
指令编码的组织其实还是很关键的,好的组织方式可以大大节约后续工作的时间,后续开发或者维护都会变得更简单。由于篇幅关系,这里将介绍一些比较常用到的指令内容的组织。这里介绍的指令内容的组织都将采用结构体的形式,其实也可以用类来实现。
typedef unsigned int QByte; //32位无符号数
(1)SWI指令
typedef struct swi { QByte comment : 24; QByte mustbe1111 : 4; QByte condition : 4; } SWI;
SWI指令的编码格式:

由指令的编码格式我们可以看到,comment的内容表示immed_24,正好24位;mustbe1111是固定的,所有SWI指令的[27:24]都是1111,condition表示条件域,总共有16种情况,用4位表示即可。
(2) 分支指令
typedef struct branch { QByte offset : 23; QByte sign : 1; QByte L : 1; QByte mustbe101 : 3; QByte condition : 4; } Branch;
分支指令的编码格式:

从指令的编码格式中,我们发现,Offset其实是确定了转向地址的绝对值;sign表明正负数;L用于区分是否要把返回地址写入R14中;mustbe101表明这是一条分支指令,固定的,cond是条件域。
(3)加载/存储指令
typedef struct singledatatrans { QByte offset : 12; QByte Rd : 4; QByte Rn : 4; QByte L : 1; QByte W : 1; QByte B : 1; QByte U : 1; QByte P : 1; QByte I : 1; QByte mustbe01 : 2; QByte condition : 4; } SingleDataTrans;
加载/存储指令编码格式:

其中offset, I, P, U, W, Rn共同决定计算出内存中的地址,Rd是目的寄存器,
L位用于区分是LDR还是STR指令;B位用于区分unsigned byte (B==1) 和 a word (B==0)。
(4)数据处理指令
typedef struct dataproc { QByte operand2 : 12; QByte Rd : 4; QByte Rn : 4; QByte S : 1; QByte opcode : 4; QByte I : 1; QByte mustbe00 : 2; QByte condition : 4; } DataProc;
对应的编码格式如下:

其中operand2是第二操作数,其计算方式也有多种形式,可参考ARM手册上的“Addressing Mode 1 - Data-processing operands on page A5-2”;Rd为目的寄存;Rn为第一操作数;S位用于区分是否影响CPSR;opcode用于明确是那种数据操作,如MOV,ADD等;I用于区分第二操作数是寄存器形式还是立即数形式;mustbe00是固定的;Cond为条件域。
段表、显示表、返回表的组织
为简单起见,本程序中这些表统统用容器Vector来实现
typedef struct Elem{ int re[16]; unsigned int addr; }Elem; static vector <unsigned int> segmentTable; //段表 static vector < unsigned int > returnAddrTable; //返回表 static vector <Elem> showAddrTable; //显示表
如上所述,其中Elem结构体用于存储显示表里面的元素。segmentTable为段表,returnAddrTable为返回表,showAddrTable为显示表。
所有的填表操作都是用push_back 函数来实现的,还有就是操作显示表和返回表时要记住返回表是后进先出的。
指令共用体


typedef union access32 { QByte qbyte; SWI swi; //SWI instruction CPRegTrans cpregtrans; // Coprocessor registesr transfers CPDataOp cpdataop; // Coprocessor data processing // Coprocessor load/store and double register transfers[6] CPDataTrans cpdatatrans; //Branch and branch with link and change to Thumb Branch branch; Undefined4 undefined4; //Undefined Ins[4] LoadStoreMultiple loadstoremultiple; //load/store multiple Undefined47 undefined47; //Undefined instruction [4,7] Undefined undefined; //Undefined instruction //Load,store immediate offset,Load,store register offset SingleDataTrans singledatatrans; MSRImeToSReg msrimetosreg; //Move immediate to status register Undefined3 undefined3; //Undefined instruction [3] DataProc dataproc; DataProcImmediate dataprocimme; MultiplyExtraLoadStore multiextraloadstore; //Multiplies, extra load/stores: MiscellanesInstructOne miscelinstrone; //Miscellaneous instructions DataProcRegShift dataprocregshift; MiscellanesInstructTwo miscelinstrtwo; //Miscellaneous instructions: DataProcImmeShift dataprocimmeshit; } Access32;
这个指令共用体的设置应该说是十分巧妙的,涵盖了所有类型的指令。在反汇编过程中,首先是从目标二进制代码中读取一个32位数到内存,然后将这个32位数从内存拷贝到共用体变量中,由于共用体的存储空间是共享的,定义一个上面的共用体,其实也就只是4个字节大小的空间,但是他可以指代任何一条指令,因此用这个共用体变量来判断读进来的32位数是那条指令非常方便和直观,具体判断的将在接下来的指令反汇编模块介绍。
其他数据结构
协处理器寄存器:
static const char *cregister[16] = { "cr0", "cr1", "cr2", "cr3", "cr4", "cr5", "cr6", "cr7", "cr8", "cr9", "cr10", "cr11", "cr12", "cr13", "cr14", "cr15" };
寄存器:
static const char *registers[16] = { "R0", "R1", "R2", "R3", "R4", "R5", "R6", "R7", "R8", "R9", "R10","R11", "R12", "R13", "R14", "PC" };
条件域:
static const char *condtext[16] = { "EQ", //"Equal (Z)" "NE", //"Not equal (!Z)" "CS", //"Unsigned higher or same (C)" }, "CC", //"Unsigned lower (!C)" }, "MI", //"Negative (N)" }, "PL", //"Positive or zero (!N)" }, "VS", //"Overflow (V)" }, "VC", // "No overflow (!V)" }, "HI", // "Unsigned higher (C&!Z)" }, "LS", //"Unsigned lower or same (!C|Z)" }, "GE", // "Greater or equal ((N&V)|(!N&!V))" }, "LT", //"Less than ((N&!V)|(!N&V)" }, "GT", //"Greater than(!Z&((N&V)|(!N&!V)))" }, "LE", //"Less than or equal (Z|(N&!V)|(!N&V))" }, "", //"Always" }, //AL,可以省略掉 "NV" //, "Never - Use MOV R0,R0 for nop" } };
数据处理指令的操作码编码,从0到15,之所以弄成以下形式是为了增加程序的可读性。
typedef enum operatecode { AND,EOR ,SUB ,RSB //AND=0; EOR=1. ,ADD,ADC ,SBC ,RSC ,TST, TEQ,CMP,CMN ,OPR ,MOV ,BIC,MVN }OperCode;
数据处理指令字符:
static const char *opcodes[16] = { "AND", "EOR", "SUB", "RSB", "ADD", "ADC", "SBC", "RSC", "TST", "TEQ", "CMP", "CMN", "ORR", "MOV", "BIC", "MVN" };
注意里面的顺序,要跟其编码规则对应。
二、二进制可执行代码读取模块
二进制可执行代码的读取模块主要完成从外部文件中读取二进制代码到内存中,并要合理组织数据。
读取函数如下所示:
void MyRead::readSourceFile(char *addr) { ifstream f1(addr,ios::binary); if(!f1) { cerr<<addr<<"不能打开"<<endl; return; } unsigned char x; int k=0,i=0; while(f1.read(( char *)&x,1)) { Content temp; // 定义一个Content临时对象 if(i==0) { temp.fourthB=x; //一个字里的第4个字节 } else if(i==1) { temp.thirdB=x; //一个字里的第3个字节 } else if(i==2) { temp.secondB=x; //一个字里的第2个字节 } else if(i==3) { temp.firstB=x; //一个字里的第1个字节 } i++; if(i==4) { i=0; temp.addr=4*k; //给地址赋值 temp.isVisited = false; temp.isHasLable = false; k++; this->contentVector.push_back(temp); //将temp存放到容器里 Content temp; } } f1.close(); }
读取模块首先要做的是打开目标文件,然后一个字节一个字节的读取进来,这里所谓的第一个字节FirstB指的是一个32位数从左往右数算起第一个的,总共四个字节。然后要设置一个Content 类型的temp中间值,将读进来的字节依次往temp赋值,赋完四个字节后,把地址,是否访问标志等等也都初始化一下;最后将这个temp中间值压入contentVector容器中,这个容器里面存放的就是目标代码读进来的二进制代码,四个字节为一个元素存放。
三、指令和数据分离并标识模块
前面已经讲了指令和数据分离的思想,主要是跟踪程序的控制流,这里讲结合程序的实现继续说明一下。首先看一下指令和数据分离的函数。
void MyDisassemble::separateI_D(MyRead &read) { int k = 0; segmentTable.push_back(0); r[15] = 0; //PC设为0 disPart(read); while(true) { if(k == showAddrTable.size()) break; //显示表都访问结束 for(int i = 0;i<16;i++) r[i] = showAddrTable[k].re[i]; //恢复现场 if(read.contentVector[((showAddrTable[k].addr)/4)].isVisited == false) //是否访问 disPart(read); k++; } } void MyDisassemble::disPart(MyRead &read) { for(int i =r[15]/4;;i = r[15]/4) { unsigned int foo=((read.contentVector[i].firstB)<<24)+ ((read.contentVector[i].secondB)<<16)+ ((read.contentVector[i].thirdB)<<8)+read.contentVector[i].fourthB; read.contentVector[i].isInstruction = true; //设置是指令 read.contentVector[i].isVisited = true; //已访问过 disArm(foo,read); //反汇编指令 if ((0x0F&read.contentVector[i].firstB)==0x0f) //程序结束 { segmentTable.push_back(r[15]); break; } r[15]=r[15]+4; } }
上述separateI_D函数的目的是为了跟踪程序的控制流,遍历每一条指令(有点类似有向图的遍历),从而标识出指令。首先是segmentTable.push_back(0),将起始地址填入段表;然后按当前地址逐条分析指令类型disPart(read);在disPart函数中,当访问这条指令时,首先要做的是把该指令的isInstruction和isVisited标志设置为true;然后disARM,disARM是反汇编函数,这个函数可以反汇编出该条指令是哪条指令,在下面的反汇编模块将会有更加详细的说明,在这里只要知道他可以识别出是哪条指令即可。
当反汇编出来的指令是无条件转移指令时,以B指令为例,要执行以下代码:
segmentTable.push_back(r[15]); segmentTable.push_back(r[15] + addr); r[15]=(r[15]+addr-4); read.contentVector[(r[15]/4)].isHasLable = true;
r[15]指pc,r[15] + addr为显示地址。(1)首先将此指令所在地址填入段表,(2)然后显示地址填入段表,(3)再然后显示地址作为当前地址,由于已经设置PC自动加了,所以这里先减一下,(4)同时转向地址处的指令前面是一个标签,把isHasLable设置为true;
若为无条件转移指令子程序调用指令,以BL为例,要执行以下代码:
r[14] = r[15] + 4; segmentTable.push_back(r[15]); returnAddrTable.push_back(r[14]); segmentTable.push_back(r[15] + addr); r[15]=(r[15]+addr-4); read.contentVector[((r[15]+4)/4)].isHasLable = true;
各条语句的意思依次是
(1)保存返回地址到R14
(2)此指令所在地址填入段表
(3)返回地址填入返回地址表
(4)显示地址填入段表
(5)显示地址作为当前地址,由于已经设置PC自动加了,所以这里先减一下
(6)该地址处指令前面有个标签。
若为无条件转移指令中的返回指令,以MOV PC,LR为例,如下:
unsigned int raddr; if(returnAddrTable.size()>0) { raddr = returnAddrTable[returnAddrTable.size()-1];
return AddrTable.pop_back(); } segmentTable.push_back(r[15]); segmentTable.push_back(raddr); r[15] = raddr-4; read.contentVector[(raddr/4)].isHasLable = true;
依次做了以下事情,
(1)返回地址表中按“后进先出”原则找到返回地址
(2)删除返回表最后一个元素
(3)指令所在地址填段表
(4)返回地址填段表
(5)设置当前的PC值
(6)设置标签标志
若为二分支指令,以BNE为例,如下:
Elem temp;temp.addr = r[15] + addr; for(int ii=0;ii<16;ii++) temp.re[ii] = r[ii]; showAddrTable.push_back(temp); read.contentVector[(( r[15] + addr)/4)].isHasLable = true;
依次做了以下事情,
(1)保存“现场”
(2)显式地址填入显式表(包括当时的寄存器值)
(3)设置标签标志。
若不是转移指令,则继续按PC值自增下去,直到终结语句,然后还要判断显示表是否空,这里用了个K变量来实现,实际上并没有真的从容器中删除取出的显示表里的元素。if(k == showAddrTable.size()) break;用来判断是否显示表里的地址都访问过了。如果没有,则继续按这条指令的地址disPart下去。直到把显示表里的地址都访问一遍。
执行完以上的代码后,就实现了按控制流遍历每条指令,是指令的基本上也都做上了标识。
四、指令反汇编模块
指令反汇编模块在宏观上主要体现在disArm这个函数上,代码如下:
char * MyDisassemble::disArm(unsigned int uint,MyRead &read,int type) { Access32 instruction; memcpy(&instruction, &uint,sizeof(uint)); //拷贝数据 if (0xF == instruction.swi.mustbe1111) //SWI指令 { decode_swi (instruction.swi); }
以上是关于基于ARM处理器的反汇编器软件简单设计及实现的主要内容,如果未能解决你的问题,请参考以下文章