语音识别技术简介
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了语音识别技术简介相关的知识,希望对你有一定的参考价值。
在人际交往中,言语是最自然并且最直接的方式之一。随着技术的进步,越来越多的人们也期望计算机能够具备与人进行言语沟通的能力,因此,语音识别这一技术也越来越受到关注。尤其,随着深度学习技术应用在语音识别技术中,使得语音识别的性能得到了显著提升,也使得语音识别技术的普及成为了现实。
以上是废话,下面开始正文。
自动语音识别技术,简单来说其实就是利用计算机将语音信号自动转换为文本的一项技术。这项技术同时也是机器理解人类言语的第一个也是很重要的一个过程。
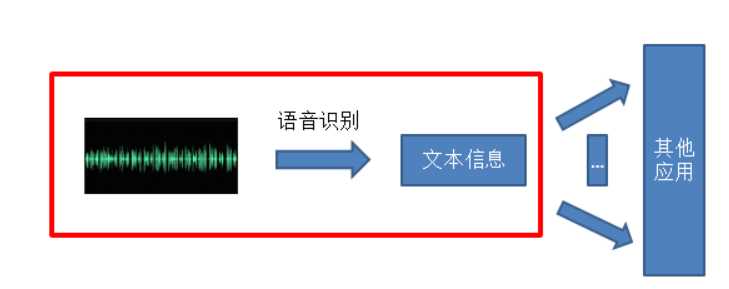
为了进一步解释计算机如何实现语音到文字的转换这一过程,我先把目前比较主流的自动语音识别系统的整体框架贴出来,然后再一一简要地对各部分进行说明。
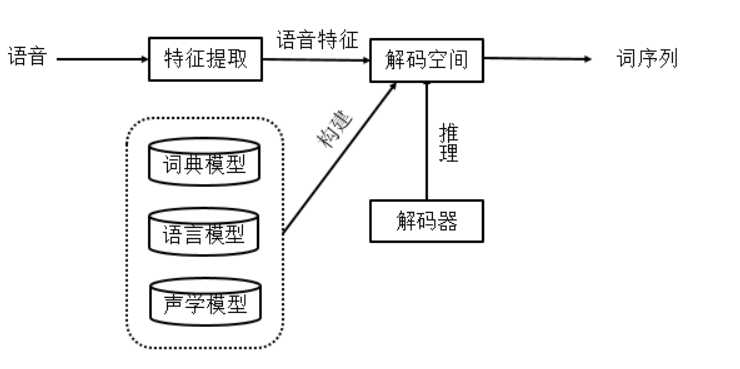
当我们要对一段语音进行识别时,首先需要进行的是对语音特征的提取。这一步所做的工作其实就是从输入的语音信号(时域信号)中提取出可以进行建模的声学观测特征向量序列O。通俗地解释就是把需要识别的一段语音进行特征提取,之后得到了一组可以表征这一段语音的向量,后续对语音进行的一系列操作都是基于这组向量的。
在得到了这组观测特征向量O之后,我们可以用一个公式来说明一下语音识别具体是要做一个什么样的事情:
W = argmax P(W|O)
这个公式含义很简单,就是说在给定一组观测向量O的条件下,找到一组词向量W使得P(W|O)的概率最大。这个也正是人听到一段语音的时候做的事情——找所有已知文字中和这段语音最匹配的。但是,依靠这个公式,我们是无法解决语音识别问题的。还需要利用贝叶斯定理对其进行转换,将其转换成我们能够分别进行建模求解的形式。转换如下:
W = argmaxP(W|O) = argmax P(O|W)P(W) / P(O)
其中,P(O)是声学观测的先验概率,在自动语音识别过程中,由于输入的声学观测特征序列是固定的,可以认为上述公式中的P(O)是常量,因此P(O)在上述公式的最大化的过程中不起作用,可以忽略。那么我们现在只剩下P(O|W)和P(W)需要考虑。而在上述结构图中的声学模型和语言模型分别提供了对P(O|W)和P(W)进行计算的方法,下面分别简单介绍一下。
首先是声学模型,其目的是提供一种方法,来对给定词w的声学观测特征序列O的似然度进行计算。(可以理解成给定一个词w,然后算目前这个特征向量是描述这个词的可能性有多大,也就是算P(O|W)),所以这个建模的任务就可以简单地理解成对每一个词建立一个描述概率分布的模型,该模型的输入是声学特征向量,输出则是一个概率(似然值),概率越高表示该声学特征越可能表示的是这个词。但是在实际的大词汇量语音识别任务中,如果对每一个词建立一个模型是很不现实的。因为词的数量非常多,而且经常会有新词出现。为了解决这个问题,声学模型通常不会直接对词进行建模,而是将词拆成字词序列,对字词进行建模。举个例子,汉语中的汉字有几万个,但是如果将汉字拆分成音标(跑 p ao),那么我们只需要用几十个音标就可以表示所有汉字的读音,就算考虑音调,我们也最多只需要几百个音标就足够了。然后,对音标进行建模,在将其拼接成汉字,就可以得到我们需要的p(O|W)同时却大大减少了建模的数量。因此,目前主流的声学建模方法一般采用对语音的基本单位——音子进行建模(音子与音标有区别,不一样,但可以利用音标对音子的概念进行理解)。
刚刚在声学模型中提到了子词的概念,那么子词如何拼接成真正的词呢?这就需要给计算机一个规则,这个就是我们的发音词典。发音词典可以理解成一个词到音子的映射(简单理解成给定词,然后利用发音单元给它“注音”,例如:你好 n i h ao),系统通过查找发音词典就可以知道每个词是由哪些发音单元组成的了。
再来说说语言模型,现在我们利用声学模型和发音词典可以搞定P(O|W)了,但是我们还需要知道P(W)要如何进行计算。语言模型就是在做这么一件事情。它提供了一种机制,来利用当前词之前的n个词来估计当前词是w的概率。举例来说,比如我们已经有了两个个词“我 是”,现在想知道接下来的词会是什么。很显然“我 是” 后面可以接很多词,比如“我是学生”,“我是猪”,“我是饮水机”等等。而语言模型的作用就是计算这些词出现的概率。因此,一个好的语言模型算得的“我是学生”的概率可能会比另两个高,因为“我是人”这句话更符合人们通常的说话习惯。这样,利用语言模型我们也找到了一种计算P(W)的方法。
最后,我们利用上述的声学模型、语言模型和发音词典就可以构建起一个解码空间,之后利用解码器,结合每一组输入的语音特征向量在空间中进行搜索,找到一条最优的词序列,就是找到一条路径使得P(O|W)P(W)概率最大。那么,最终得到的这个词序列就是我们想要的识别结果。
由于是第一次写博客,就先写篇小简介试试水,写的不好,中间也应该会有一些错误和不足,还望大家多提意见,多多指正 O(∩_∩)O
以上是关于语音识别技术简介的主要内容,如果未能解决你的问题,请参考以下文章