NLP自然语言处理学习笔记二(初试)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP自然语言处理学习笔记二(初试)相关的知识,希望对你有一定的参考价值。
前言:
用Python对自然语言处理有很好的库。它叫NLTK。下面就是对NLTK的第一尝试。
安装:
1.安装Pip
比较简单,得益于CentOS7自带的easy_install。执行一行命令就可以搞定。
*在终端控制台->easy_install pip
2.检验Pip是否可用
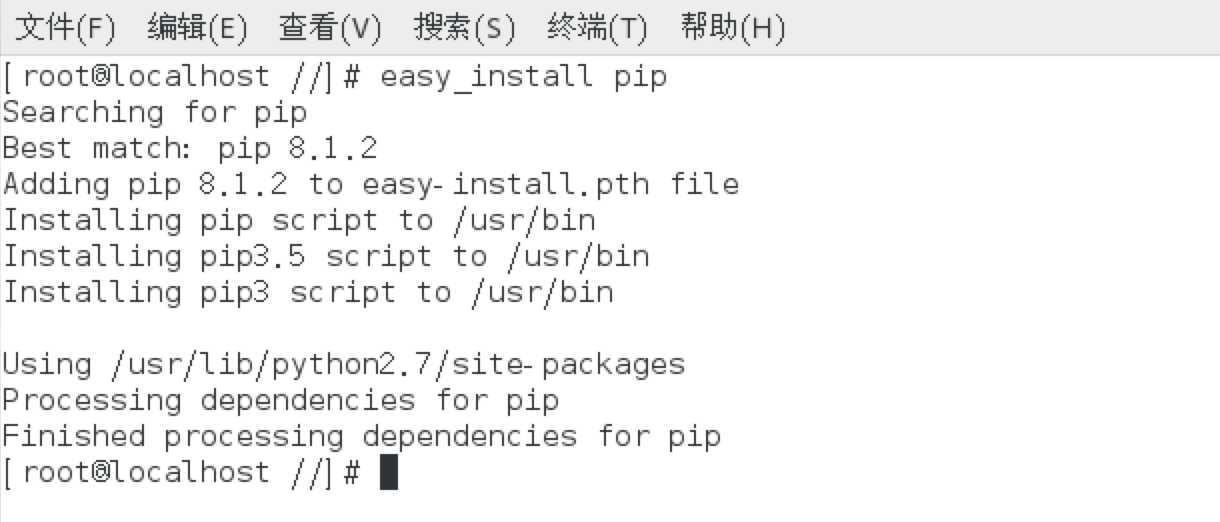
Pip是Python的包管理工具。我们运行Pip确定CentOS下可用。
*在终端控制台->pip -V 注意参数大小写

3.使用Pip安装NLTK
*在终端控制台->pip install -U nltk

NLTK使用:
完成安装后我们可以在Python的解释器里试验一下。当然在命令行形式(command line)下的解析器里编写Python确实有些不爽。下一节会推荐好用的Python IDE (集成开发环境)给大家。稍安勿躁哦。我们还是先来第一个小实验吧。
*在终端控制台->Python 进入Python解释器(command line)->print("hello python")

*继续输入->import nltk->nltk.download()

*下载我们需要的预料库按l键来浏览列表(回车进行翻页)。我们需要下载的是book标记的预料库作为我们的第一个小实验的数据。

*下载book语料库数据。按d键然后输入book回车。等待下载,下载完成可以按l键看看都安装了那些数据。后按q键退出。
按L键,看看那些预料被安装了。回车翻页。

第一个小实验搜索
现在可以可以开始第一个小实验了,按照书上的范例我们搜索《白鲸记》中的词monstrous。当然这本书已经包含在我们刚才下载的预料数据里了。
*导入nltk.book的预料库->from nltk.book import *->text1 便打印出了《白鲸记》

*找出monstrous这个词很简单只需要使用concordance这个函数就可以了。是不是很简单。

一共出现在了11处位置,并且显示了出现这个词的上下文。到现在为止我们已经开启了NLP学习的大门。是不是很激动呢。让我们一起努力吧。
以上是关于NLP自然语言处理学习笔记二(初试)的主要内容,如果未能解决你的问题,请参考以下文章