使用lex---01
Posted 天堂1223
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用lex---01相关的知识,希望对你有一定的参考价值。
(一)、写在前面
lex是构建词法分析程序的工具。词法分析程序把随机输入流标记化,即将他拆分成词法标记。然后,可以进一步处理这种被标记化的输出,通常是由yacc来处理的,或者他就成为“最终产品”。
当编写lex规范的时候,可以创建lex匹配输入所用的一套模式。每次匹配一个模式的时候,lex程序就调用我们提供的C代码来处理匹配的文本。采用这种方式,lex程序将输入拆分成成为标记的字符串。lex本身不产生可执行程序。相反,他把lex规范转化成包含C例程yylex()的文件。程序调用yylex()来运行词法分析程序。
(二)、正则表达式
1:正则表达式字符
正则表达式被广泛应用于UNIX环境,并且lex可以使用丰富的正则表达式语言。
正则表达式是一种使用”元(meta)”语言的模式描述。元语言用于描述特定模式。形成正则表达式的字符为:
| 符号 | 含义 |
|---|---|
| . | 匹配除换行符(“\n”)以外的任何单个字符 |
| * | 匹配前面表达式的零个或多个拷贝 |
| [] | 匹配括号中任意字符的字符类 |
| ^ | 作为正则表达式的第一个字符匹配行的开头,也用于方括号中的否定 |
| $ | 作为正则表达式的最后一个字符匹配行的结尾 |
| {} | 当括号中包含一个或两个数字的时候,指示前面的模式被允许匹配多少次 |
| \ | 用于转义字符 |
| + | 匹配前面的正则表达式的一次或多次出现 |
| ? | 匹配前面的正则表达式的零次或一次出现 |
| “…” | 引号中的每个字符解释为字面意义 |
| / | 只有在后面跟有指定的正则表达式的时候才匹配前面的正则表达式 |
| () | 将一系列正则表达式组合成一个新的正则表达式 |
2:lex的正则例子程序
下面我们编写一个小数的lex规范:
首先我们先来看一下表示小数的正则表达式:
-?(([0-9]+)|([0-9]*\.[0-9]+)([eE][-+]?[0-9]+)?)现在我们来看一下lex的实现:
名称:xs.lex
%%
[\n\t ] ;
-?(([0-9]+)|([0-9]*\.[0-9]+)([eE][-+]?[0-9]+)?) { printf("number\n"); }
. ECHO;
%%
main()
{
yylex();
}
int yywrap()
{
return 0;
}
我们使用下面的命令编译程序:
lex xs.lex
gcc lex.yy.c -o xs
./xs //运行程序下面我们来看一下运行效果:
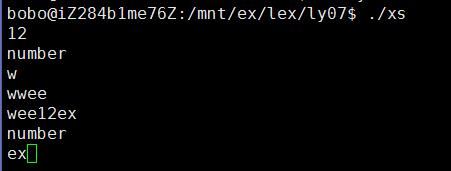
(三)、实例:单词计数程序
下面我们通过一个实例来进一步了解lex。
lex规范由二部分组成:定义段,规则段和用户子例程段。第一部分处理lex用在词法分析程序中的选项,并且一半建立词法分析程序运行的执行环境。
单词计数示例的定义段如下:
%{
unsigned int charCount = 0,wordCount = 0,lineCount = 0;
%}
word [^ \t\n]+
eol \n由”%{“和”%}”括住的部分是C代码,他们将被逐字地拷贝到词法分析程序中。这些C代码一开始就被放入到输出代码中。
最后的两行是定义。lex提供了一种简单的替换机制,从而使定义长的或复杂的模式变得很容易。我们这里添加了两个定义,第一个定义提供了单词描述:除了空格,制表符和换行符以外的字符的非空组合。第二个定义描述行结束字符,即换行。
规则段包含指定词法分析程序的模式和动作。下面是示例中的单词计数的规则段:
%%
{word} { wordCount++; charCount+=yyleng; }
{eol} { charCount++; lineCount++; }
. { charCount++; }规则段以”%%”开始。在模式中,lex使用substitution代替大括号{}中的名字。在词法分析程序识别了完整的单词之后,我们的示例增加单词和字符的数目。
大括号中封闭的多个语句组成的动作生成一个C语言复合语句。
值得重复的是,lex总是尝试匹配了能最长的字符串。因此,词法分析程序将把字符串”well-being”作为一个单词。
示例中也使用了lex的内部变量yyleng,他包含词法分析程序识别的字符串长度。如果匹配了well-being,yyleng就为10。
lex规范的第三部分和最后部分是用户子例程段。他通过”%%”和前面的段分开。用户子例程段包含任何有效的C代码。他被逐字拷贝到生成的词法分析程序中。
%%
int main()
{
yylex();
printf("%d %d %d",lineCount,wordCount,charCount);
return 0;
}
int yywrap()
{
return 0;
}
首先,它调用词法分析程序的入口点yylex(),然后调用printf()打印这次运行的结果。
下面我们来看一下该示例的整体程序:
%{
unsigned int charCount = 0,wordCount = 0,lineCount = 0;
%}
word [^ \t\n]+
eol \n
%%
{word} { wordCount++; charCount+=yyleng; }
{eol} { charCount++; lineCount++; }
. { charCount++; }
%%
int main()
{
yylex();
printf("%d %d %d",lineCount,wordCount,charCount);
return 0;
}
int yywrap()
{
return 0;
}要注意,我们的示例没有任何花哨的操作:他既不接受命令行参数,也不打开任何文件,指示使用lex默认读取标准输入。当然,我们可以为lex 重新连接输入流。
我们来看一下:
%%
int main(argc,argv)
int argc;
char **argv;
{
if(argc > 1){
FILE *file;
file = fopen(argv[1],"r");
if(!file){
fprintf(stderr,"could not open %s\n",argv[1]);
exit(1);
}
yyin = file;
}
yylex();
printf("%d %d %d\n",lineCount,wordCount,charCount);
return 0;
}
int yywrap()
{
// 0 - 输入未完成 1 - 输入已完成
return 1;
}
lex词法分析程序从标准IO文件yyin中读取输入,所以当需要的时候,只需要改变yyin。yyin的默认值是stdin。
编译, 运行一下我们的程序,我们来看一下运行效果:

当yylex()到达输入文件的尾端的时候,它调用yywrap(),该函数返回数值0或1.如果值为1,那么程序完成而且没有输入。换句话说,如果值为0,那么词法分析程序假设yywrap()已经打开了他要读取的另一个文件,而且继续读取yyin。默认的yywrap()总是返回1 。通常是自定义一个yywrap()函数。
下面我们来实现一个处理多个文件的lex程序:
%{
/*
* 多文件的单词计数程序
*
*/
unsigned long charCount = 0,wordCount = 0,lineCount = 0;
#undef yywrap /* 默认情况下有时是一个宏 */
%}
word [^ \t\n]+
eol \n
%%
{word} { wordCount++; charCount += yyleng; }
{eol} { charCount++; lineCount++; }
. charCount++;
%%
char **fileList;
unsigned currentFile = 0;
unsigned nFiles;
unsigned long totalCC = 0;
unsigned long totalWC = 0;
unsigned long totalLC = 0;
int main(int argc,char *argv[])
{
FILE *file;
fileList = argv + 1;
nFiles = argc - 1;
if(argc == 2){
/*
* 因为不需要打印摘要行,所以处理单个文件的情况
* 与处理多个文件的情况不同
*
*/
currentFile = 1;
file = fopen(argv[1],"r");
if(!file){
fprintf(stderr,"could not open %s\n",argv[1]);
exit(1);
}
yyin = file;
}
if(argc > 2)
yywrap(); /* 打开第一个文件 */
yylex();
/*
* 处理零个或一个文件与处理多个文件的又一个不同之处
*/
if(argc > 2){
printf("%8lu %8lu %8lu %s\n",lineCount,wordCount,charCount,fileList[currentFile-1]);
totalCC += charCount;
totalWC += wordCount;
totalLC += lineCount;
printf("%8lu %8lu %8lu total\n",totalLC,totalWC,totalCC);
}else{
printf("%8lu %8lu %8lu\n",lineCount,wordCount,charCount);
}
return 0;
}
/*
* 词法分析程序调用yywrap处理EOF。(比如,在本例中
* 我们连接到一个新文件)
*/
int yywrap()
{
FILE *file;
if((currentFile != 0) && (nFiles > 1) && (currentFile < nFiles))
{
/*
* 打印出前一个文件的统计信息
*/
printf("%8lu %8lu %8lu %s\n",lineCount,wordCount,charCount,fileList[currentFile-1]);
totalCC += charCount;
totalWC += wordCount;
totalLC += lineCount;
charCount = wordCount = lineCount = 0;
fclose(yyin); /* 处理完这个文件 */
}
while(fileList[currentFile] != (char *)0){
file = fopen(fileList[currentFile++],"r");
if(file != NULL){
yyin = file;
break;
}
fprintf(stderr,"could not open %s\n",fileList[currentFile-1]);
}
return (file ? 0 : 1); /* 0表示还有更多的输入 */
}
示例使用yywrap()执行连续的处理。每次词法分析程序调用yywrap()的时候,都尝试从命令行中打开下一个文件名并将打开的文件赋给yyin,如果存在另一个文件就返回0,如果没有就返回1.
下面我们来看一下运行的效果:
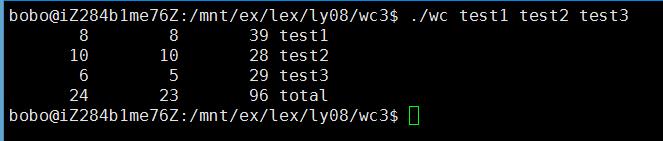
(四):写在后面
后面我们将继续进行lex的学习,将会有更多的例子程序来使我们更加深入的理解和使用lex。加油。
代码下载
以上是关于使用lex---01的主要内容,如果未能解决你的问题,请参考以下文章
Android课程---Android Studio使用小技巧:提取方法代码片段